溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關FISCO BCOS工程師常用的性能分析工具有什么,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
FISCO BCOS是完全開源的聯盟區塊鏈底層技術平臺,由金融區塊鏈合作聯盟(深圳)(簡稱金鏈盟)成立開源工作組通力打造。開源工作組成員包括博彥科技、華為、深證通、神州數碼、四方精創、騰訊、微眾銀行、亦筆科技和越秀金科等金鏈盟成員機構。
『過早的優化是萬惡之源』
說出這句話的計算機科學先驅Donald Knuth并不是反對優化,而是強調要對系統中的關鍵位置進行優化。假設一個for循環耗時0.01秒,即使使用循環展開等各種奇技淫巧將其性能提升100倍,把耗時降到0.00001秒,對于用戶而言,也基本無法感知到。對性能問題進行量化測試之前,在代碼層面進行各種炫技式優化,可能不僅提升不了性能,反而會增加代碼維護難度或引入更多錯誤。
『沒有任何證據支撐的優化是萬惡之源』
在對系統施展優化措施前,一定要對系統進行詳盡的性能測試,從而找出真正的性能瓶頸。奮戰在FISCO BCOS性能優化的前線上,我們對如何使用性能測試工具來精確定位性能熱點這件事積累了些許經驗心得。本文將我們在優化過程中使用到的工具進行了整理匯總,以饗讀者。
窮人的分析器,簡稱PMP。盡管名字有些讓人摸不著頭腦,但人家真的是一種正經的性能分析手段,甚至有自己的官方網站https://poormansprofiler.org/。PMP的原理是Stack Sampling,通過調用第三方調試器(比如gdb),反復獲取進程中每個線程的堆棧信息,PMP便可以得到目標進程的熱點分布。
第一步,獲取一定數量的線程堆棧快照:
pid=$(pidof fisco-bcos)num=10for x in $(seq 1 $(num)) do gdb -ex "set pagination 0" -ex "thread apply all bt" -batch -p $pid sleep 0.5done
第二步,從快照中取出函數調用棧信息,按照調用頻率排序:
awk ' BEGIN { s = ""; } /^Thread/ { print s; s = ""; } /^\#/ { if (s != "" ) { s = s "," $4} else { s = $4 } } END { print s }' | \sort | uniq -c | sort -r -n -k最后得到輸出,如下圖所示:

從輸出中可以觀察到哪些線程的哪些函數被頻繁采樣,進而可按圖索驥找出可能存在的瓶頸。上述寥寥數行shell腳本便是PMP全部精華之所在。極度簡單易用是PMP的最大賣點,除了依賴一個隨處可見的調試器外,PMP不需要安裝任何組件,正如PMP作者在介紹中所言:『盡管存在更高級的分析技術,但毫無例外它們安裝起來都太麻煩了……Poor man doesn't have time. Poor man needs food.』????。
PMP的缺點也比較明顯:gdb的啟動非常耗時,限制了PMP的采樣頻率不能太高,因此一些重要的函數調用事件可能會被遺漏,從而導致最后的profile結果不夠精確。
但是在某些特殊場合,PMP還是能發揮作用的,比如在一些中文技術博客中,就有開發人員提到使用PMP成功定位出了線上生產環境中的死鎖問題,PMP作者也稱這項技術在Facebook、Intel等大廠中有所應用。不管怎樣,這種閃爍著程序員小智慧又帶點小幽默的技術,值得一瞥。
perf的全稱是Performance Event,在2.6.31版本后的Linux內核中均有集成,是Linux自帶的強力性能分析工具,使用現代處理器中的特殊硬件PMU(Performance Monitor Unit,性能監視單元)和內核性能計數器統計性能數據。
perf的工作方式是對運行中的進程按一定頻率進行中斷采樣,獲取當前執行的函數名及調用棧。如果大部分的采樣點都落在同一個函數上,則表明該函數執行的時間較長或該函數被頻繁調用,可能存在性能問題。
使用perf需要首先對目標進程進行采樣:
$ sudo perf record -F 1000 -p `pidof fisco-bcos` -g -- sleep 60
在上述命令中, 我們使用perf record指定記錄性能的統計數據;使用-F指定采樣的頻率為1000Hz,即一秒鐘采樣1000次;使用-p指定要采樣的進程ID(既fisco-bcos的進程ID),我們可以直接通過pidof命令得到;使用-g表示記錄調用棧信息;使用sleep指定采樣持續時間為60秒。
待采樣完成后,perf會將采集到的性能數據寫入當前目錄下的perf.data文件中。
$ perf report -n
上述命令會讀取perf.data并統計每個調用棧的百分比,且按照從高到低的順序排列,如下圖所示:
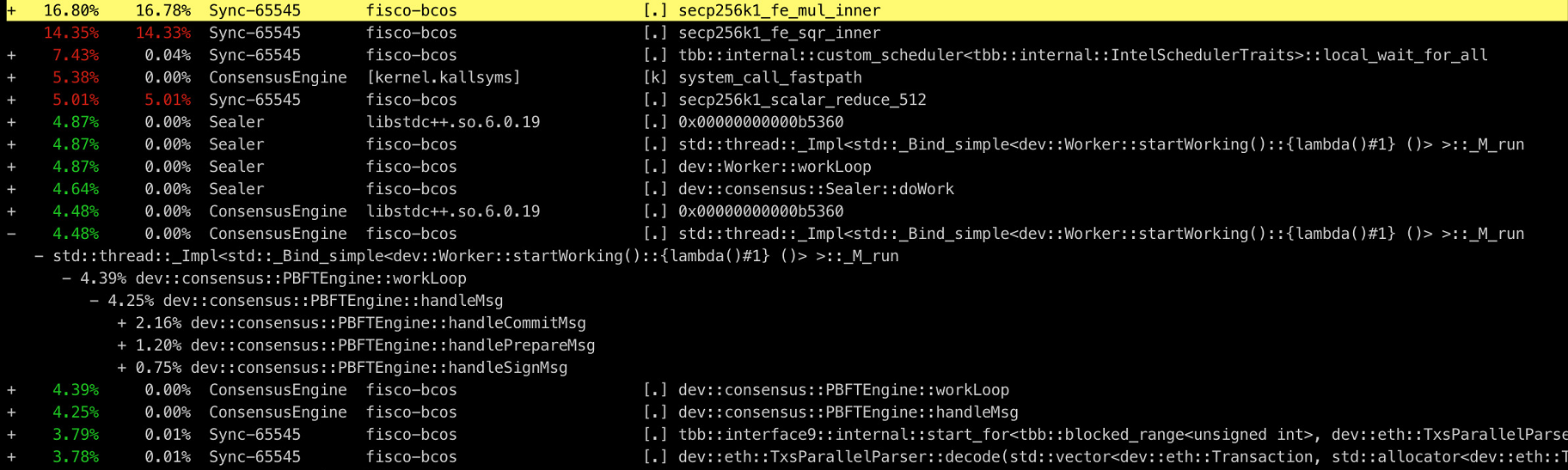
信息已足夠豐富,但可讀性仍然不太友好。盡管示例中perf的用法較為簡單,但實際上perf能做的遠不止于此。配合其他工具,perf采樣出的數據能夠以更加直觀清晰的方式展現在我們面前,這便是我們接下來要介紹的性能分析神器——火焰圖。
火焰圖,即Flame Graph,藉由系統性能大牛 Brendan Gregg提出的動態追蹤技術而發揚光大,主要用于將性能分析工具生成的數據進行可視化處理,方便開發人員一眼就能定位到性能問題所在。火焰圖的使用較為簡單,我們僅需將一系列工具從github上下載下來,置于本地任一目錄即可:
wget https://github.com/brendangregg/FlameGraph/archive/master.zipunzip master.zip
3.1、CPU火焰圖
當我們發現FISCO BCOS性能較低時,直覺上會想弄清楚到底是哪一部分的代碼拖慢了整體速度,CPU是我們的首要考察對象。
首先使用perf對FISCO BCOS進程進行性能采樣:
sudo perf record -F 10000 -p `pidof fisco-bcos` -g -- sleep 60# 對采樣數據文件進行解析生成堆棧信息sudo perf script > cpu.unfold
生成了采樣數據文件后,接下來調用火焰圖工具生成火焰圖:
# 對perf.unfold進行符號折疊sudo ./stackcollapse-perf.pl cpu.unfold > cpu.folded# 生成SVG格式的火焰圖sudo ./flamegraph.pl cpu.folded > cpu.svg
最后輸出一個SVG格式圖片,用來展示CPU的調用棧,如下圖所示:
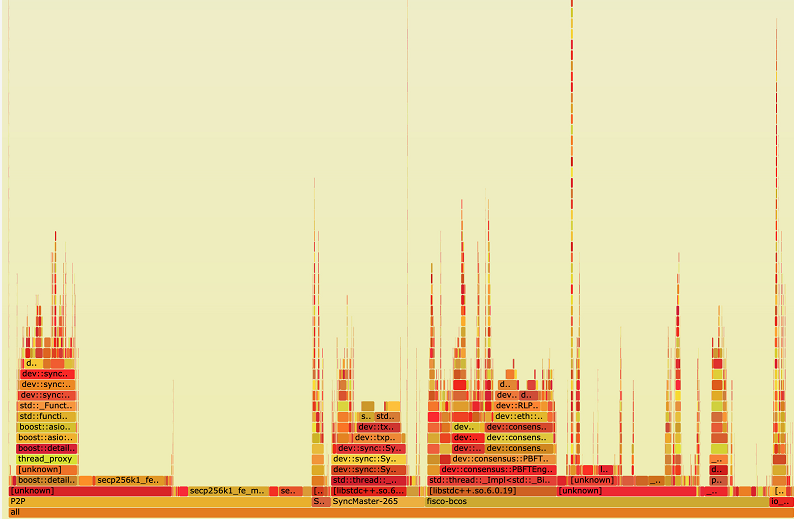
縱軸表示調用棧。每一層都是一個函數,也是其上一層的父函數,最頂部就是采樣時正在執行的函數,調用棧越深,火焰就越高。
橫軸表示抽樣數。注意,并不是表示執行時間。若一個函數的寬度越寬,則表示它被抽到的次數越多,所有調用棧會在匯總后,按字母序列排列在橫軸上。
火焰圖使用了SVG格式,可交互性大大提高。在瀏覽器中打開時,火焰的每一層都會標注函數名,當鼠標懸浮其上,會顯示完整的函數名、被抽樣次數和占總抽樣字數的百分比,如下:
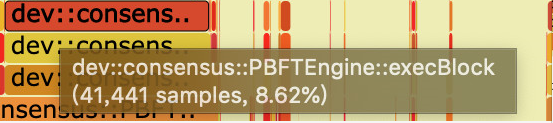
點擊某一層時,火焰圖會水平放大,該層會占據所有寬度,并顯示詳細信息,點擊左上角的『Reset Zoom』即可還原。下圖展示了PBFT模塊在執行區塊時,各個函數的抽樣數占比:
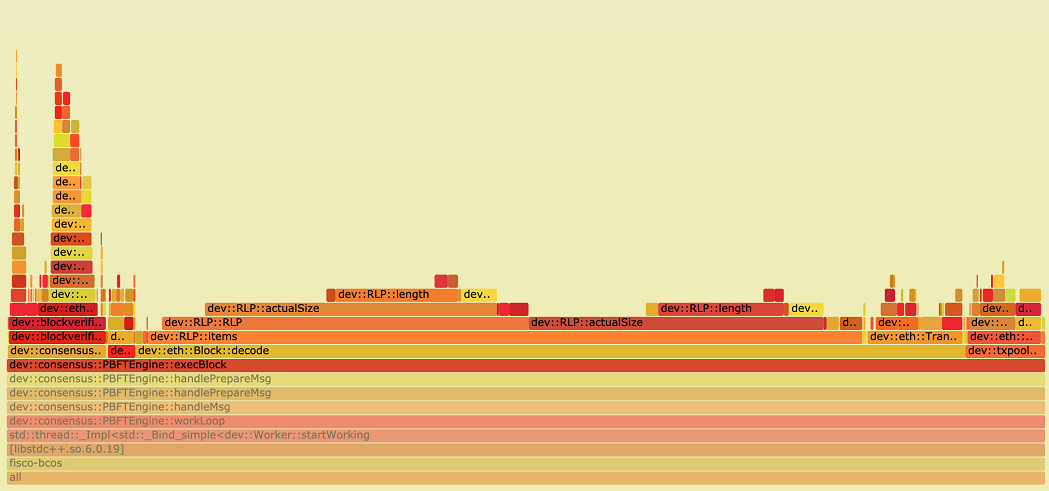
從圖中可以看出,在執行區塊時,主要開銷在交易的解碼中,這是由于傳統的RLP編碼在解碼時,RLP編碼中每個對象的長度不確定,且RLP編碼只記錄了對象的個數,沒記錄對象的字節長度,若要獲取其中的一個編碼對象,必須遞歸解碼其前序的所有對象。
因此,RLP編碼的解碼過程是一個串行的過程,當區塊中交易數量較大時,這一部分的開銷將變得十分巨大。對此,我們提出了一種并行解碼RLP編碼的優化方案,具體實現細節可以參考上一篇文章《FISCO BCOS中的并行化實踐 》。
有了火焰圖,能夠非常方便地查看CPU的大部分時間開銷都消耗在何處,進而也能針對性進行優化了。
3.2、Off-CPU火焰圖
在實現FISCO BCOS的并行執行交易功能時,我們發現有一個令人困惑的現象:有時即使交易量非常大,區塊的負載已經打滿,但是通過top命令觀察到CPU的利用率仍然比較低,通常4核CPU的利用率不足200%。在排除了交易間存在依賴關系的可能后,推測CPU可能陷入了I/O或鎖等待中,因此需要確定CPU到底在什么地方等待。
使用perf,我們可以輕松地了解系統中任何進程的睡眠過程,其原理是利用perf static tracer抓取進程的調度事件,并通過perf inject對這些事件進行合并,最終得到誘發進程睡眠的調用流程以及睡眠時間。
我們要通過perf分別記錄sched:sched_stat_sleep、sched:sched_switch、sched:sched_process_exit三種事件,這三種事件分別表示進程主動放棄 CPU 而進入睡眠的等待事件、進程由于I/O和鎖等待等原因被調度器切換而進入睡眠的等待事件、進程的退出事件。
perf record -e sched:sched_stat_sleep -e sched:sched_switch \-e sched:sched_process_exit -p `pidof fisco-bcos` -g \-o perf.data.raw sleep 60perf inject -v -s -i perf.data.raw -o perf.data# 生成Off-CPU火焰圖perf script -f comm,pid,tid,cpu,time,period,event,ip,sym,dso,trace | awk ' NF > 4 { exec = $1; period_ms = int($5 / 1000000) } NF > 1 && NF <= 4 && period_ms > 0 { print $2 } NF < 2 && period_ms > 0 { printf "%s\n%d\n\n", exec, period_ms }' | \./stackcollapse.pl | \./flamegraph.pl --countname=ms --title="Off-CPU Time Flame Graph" --colors=io > offcpu.svg在較新的Ubuntu或CentOS系統中,上述命令可能會失效,出于性能考慮,這些系統并不支持記錄調度事件。好在我們可以選擇另一種profile工具——OpenResty的SystemTap,來替代perf幫助我們收集進程調度器的性能數據。我們在CentOS下使用SystemTap時,只需要安裝一些依賴kenerl debuginfo即可使用。
wget https://raw.githubusercontent.com/openresty/openresty-systemtap-toolkit/master/sample-bt-off-cpuchmod +x sample-bt-off-cpu./sample-bt-off-cpu -t 60 -p `pidof fisco-bcos` -u > out.stap./stackcollapse-stap.pl out.stap > out.folded./flamegraph.pl --colors=io out.folded > offcpu.svg
得到的Off-CPU火焰圖如下圖所示:

展開執行交易的核心函數后,位于火焰圖中右側的一堆lock_wait很快引起了我們的注意。分析過它們的調用棧后,我們發現這些lock_wait的根源,來自于我們在程序中有大量打印debug日志的行為。
在早期開發階段,我們為了方便調試,添加了很多日志代碼,后續也沒有刪除。雖然我們在測試過程中將日志等級設置得較高,但這些日志相關的代碼仍會產生運行時開銷,如訪問日志等級狀態來決定是否打印日志等。由于這些狀態需要線程間互斥訪問,因此導致線程由于競爭資源而陷入饑餓。
我們將這些日志代碼刪除后,執行交易時4核CPU的利用率瞬間升至300%+,考慮到線程間調度和同步的開銷,這個利用率已屬于正常范圍。這次調試的經歷也提醒了我們,在追求高性能的并行代碼中輸出日志一定要謹慎,避免由于不必要的日志而引入無謂的性能損失。
3.3 、內存火焰圖
在FISCO BCOS早期測試階段,我們采取的測試方式是反復執行同一區塊,再計算執行一個區塊平均耗時,我們發現,第一次執行區塊的耗時會遠遠高于后續執行區塊的耗時。從表象上看,這似乎是在第一次執行區塊時,程序在某處分配了緩存,然而我們并不知道具體是在何處分配的緩存,因此我們著手研究了內存火焰圖。
內存火焰圖是一種非侵入式的旁路分析方法,相較于模擬運行進行內存分析的Valgrid和統計heap使用情況的TC Malloc,內存火焰圖可以在獲取目標進程的內存分配情況的同時不干擾程序的運行。
制作內存火焰圖,首先需要向perf動態添加探針以監控標準庫的malloc行為,并采樣捕捉正在進行內存申請/釋放的函數的調用堆棧:
perf record -e probe_libc:malloc -F 1000 -p `pidof fisco-bcos` -g -- sleep 60
然后繪制內存火焰圖:
perf script > memory.perf./stackcollapse-perf.pl memory.perf > memory.folded./flamegraph.pl --colors=mem memory.folded > memory.svg
得到的火焰圖如下圖所示:
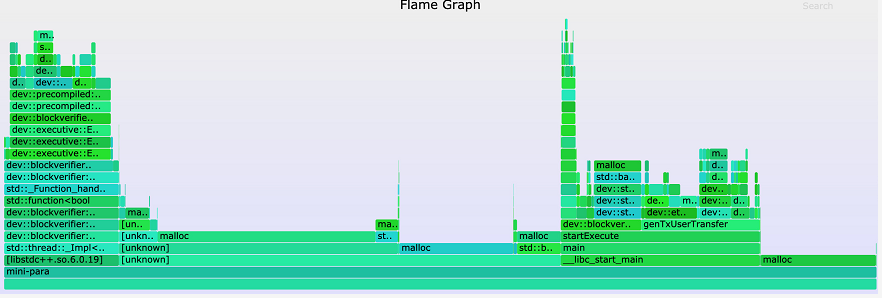
我們起初猜想,這塊未知的緩存可能位于LevelDB的數據庫連接模塊或JSON解碼模塊中,但通過比對第一次執行區塊和后續執行區塊的內存火焰圖,我們發現各個模塊中malloc采樣數目的比例大致相同,因此很快便將這些猜想否定掉了。直到結合Off-CPU火焰圖觀察,我們才注意到第一次執行區塊時調用sysmalloc的次數異常之高。聯想到malloc會在首次被調用時進行內存預分配的特性,我們猜想第一次執行區塊耗時較多可能就是由此造成的。
為驗證猜想,我們將malloc的預分配空間上限調低:
export MALLOC_ARENA_MAX=1
然后再次進行測試并繪制Off-CPU火焰圖,發現雖然性能有所降低,但是第一次執行區塊的耗時和sysmalloc調用次數,基本無異于之后執行的區塊。據此,我們基本可以斷定這種有趣的現象是由于malloc的內存預分配行為導致。
當然,這種行為是操作系統為了提高程序整體性能而引入的,我們無需對其進行干涉,況且第一個區塊的執行速度較慢,對用戶體驗幾乎也不會造成負面影響,但是再小的性能問題也是問題,作為開發人員我們應當刨根問底,做到知其然且知其所以然。
雖然這次Memory火焰圖并沒有幫我們直接定位到問題的本質原因,但通過直觀的數據比對,我們能夠方便地排除錯誤的原因猜想,減少了大量的試錯成本。面對復雜的內存問題,不僅需要有敏銳的嗅覺,更需要Memory火焰圖這類好幫手。
盡管已經有如此多優秀的分析工具,幫助我們在性能優化前進的道路上披荊斬棘,但強大的功能有時也會趕不上性能問題的多變性,這種時候就需要我們結合自身的需求,自給自足地開發分析工具。
在進行FISCO BCOS的穩定性測試時,我們發現隨著測試時間的增長,FISCO BCOS節點的性能呈現衰減趨勢,我們需要得到所有模塊的性能趨勢變化圖,以排查出導致性能衰減的元兇,但現有的性能分析工具基本無法快速、便捷地實現這一需求,因此我們選擇另尋他路。
首先,我們在代碼中插入大量的樁點,這些樁點用于測量我們感興趣的代碼段的執行耗時,并將其附加上特殊的標識符記錄于日志中:
auto startTime = utcTime();/*...code to be measured...*/auto endTime = utcTime();auto elapsedTime = endTime - startTime;LOG(DEBUG) << MESSAGE("<identifier>timeCost: ") \ << MESSAGE(to_string(elspasedTime));當節點性能已經開始明顯下降后,我們將其日志導出,使用自己編寫的Python腳本將日志以區塊為單位進行分割,隨后讀取每個區塊在執行時產生的樁點日志,并解析出各個階段的耗時,然后由腳本匯總到一張大的Excel表格中,最后再直接利用Excel自帶的圖表功能,繪制出所有模塊的性能趨勢變化圖,如下圖所示:
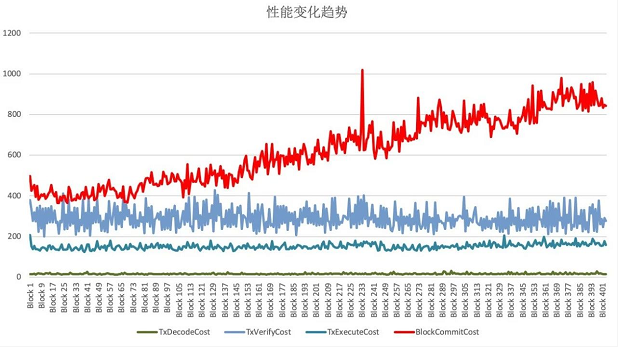
其中,橫坐標為區塊高度,縱坐標為執行耗時(ms),不同顏色曲線代表了不同模塊的性能變化。
從圖中可以看出,只有由紅色曲線代表的區塊落盤模塊的執行耗時明顯地隨著數據庫中數據量的增大而迅速增加,由此可以判斷節點性能衰減問題的根源就出在區塊落盤模塊中。使用同樣的方式,對區塊落盤模塊的各個函數進一步剖析,我們發現節點在向數據庫提交新的區塊數據時,調用的是LevelDB的update方法,并非insert方法。
兩者的區別是,由于LevelDB以K-V的形式存儲數據,update方法在寫入數據前會進行select操作,因為待update的數據可能在數據庫中已存在,需要先按Key查詢出Value的數據結構才能進行修改,而查詢的耗時與數據量成正比,insert方法則完全不需要這一步。由于我們寫入的是全新的數據,因此查詢這一步是不必要的,只需改變數據寫入的方式,節點性能衰減的問題便迎刃而解。
相同的工具稍微變換一下用法,就能衍生出其他的用途,比如:將兩批樁點性能數據放入同一張Excel表格中,便能夠通過柱狀圖工具清晰地展現兩次測試結果的性能變化。
下圖展示的是我們在優化交易解碼及驗簽流程時,優化前后性能柱狀對比圖:
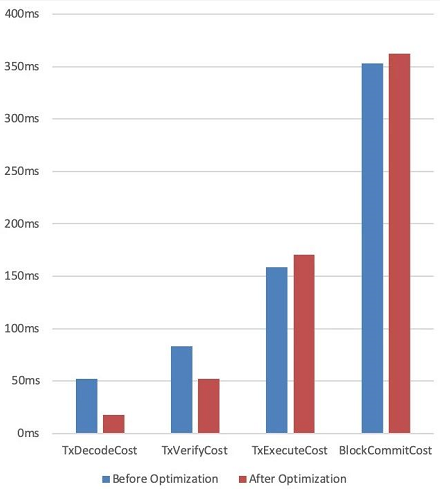
從圖中可以看出,交易解碼和驗簽流程優化后的耗時的確比優化前有所降低。借由柱狀對比圖,我們能夠輕松地檢查優化手段是否行之有效,這一點在性能優化的過程中起到了重要的指導作用。
上述就是小編為大家分享的FISCO BCOS工程師常用的性能分析工具有什么了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





