溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了KNN算法原理及Spark實現是怎樣的,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
首先,KNN是一種分類算法,有監督的機器學習,將訓練集的類別打標簽,當測試對象和訓練對象完全匹配時候,就可以對其進行分類,但是測試對象與訓練對象的多個類,如何匹配呢,前面可以判別是否測試對象術語某個訓練對象,但是如果是多個訓練對象類,那如何解決這種問題呢,所以就有了KNN,KNN是通過測量不同特征值之間的距離進行分類。它的思路是:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別,其中K通常是不大于20的整數。KNN算法中,所選擇的鄰居都是已經正確分類的對象。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別
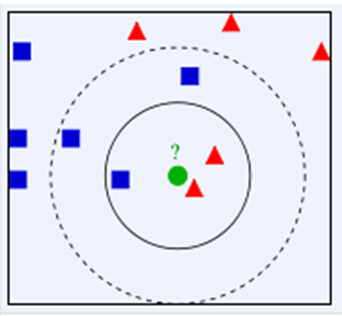 KNN算法的核心思想是,如果一個樣本在特征空間中的K個最相鄰的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別,并具有這個類別上樣本的特性。該方法在確定分類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。KNN方法在類別決策時,只與極少量的相鄰樣本有關。由于KNN方法主要靠周圍有限的鄰近的樣本,而不是靠判別類域的方法來確定所屬類別的,因此對于類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合。
KNN算法的核心思想是,如果一個樣本在特征空間中的K個最相鄰的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別,并具有這個類別上樣本的特性。該方法在確定分類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。KNN方法在類別決策時,只與極少量的相鄰樣本有關。由于KNN方法主要靠周圍有限的鄰近的樣本,而不是靠判別類域的方法來確定所屬類別的,因此對于類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合。
優點:易于理解,實現起了很方便,無需預估參數,無需訓練
缺點:數據集中如果某個類的數據量很大,那么勢必導致測試集合跑到這個類的更多,因為離這些點較近的概率也較大
鏈接:https://pan.baidu.com/s/1FmFxSrPIynO3udernLU0yQ提取碼:hell 復制這段內容后打開百度網盤手機App,操作更方便哦
鳶尾花數據集,數據集包含3類共150調數據,每類含50個數據,每條記錄含4個特征:花萼長度、花萼寬度、花瓣長度、花瓣寬度
過這4個 特征預測鳶尾花卉屬于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品種
package com.hoult.work
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object KNNDemo {
def main(args: Array[String]): Unit = {
//1.初始化
val conf=new SparkConf().setAppName("SimpleKnn").setMaster("local[*]")
val sc=new SparkContext(conf)
val K=15
//2.讀取數據,封裝數據
val data: RDD[LabelPoint] = sc.textFile("data/lris.csv")
.map(line => {
val arr = line.split(",")
if (arr.length == 6) {
LabelPoint(arr.last, arr.init.map(_.toDouble))
} else {
println(arr.toBuffer)
LabelPoint(" ", arr.map(_.toDouble))
}
})
//3.過濾出樣本數據和測試數據
val sampleData=data.filter(_.label!=" ")
val testData=data.filter(_.label==" ").map(_.point).collect()
//4.求每一條測試數據與樣本數據的距離
testData.foreach(elem=>{
val distance=sampleData.map(x=>(getDistance(elem,x.point),x.label))
//獲取距離最近的k個樣本
val minDistance=distance.sortBy(_._1).take(K)
//取出這k個樣本的label并且獲取出現最多的label即為測試數據的label
val labels=minDistance.map(_._2)
.groupBy(x=>x)
.mapValues(_.length)
.toList
.sortBy(_._2).reverse
.take(1)
.map(_._1)
printf(s"${elem.toBuffer.mkString(",")},${labels.toBuffer.mkString(",")}")
println()
})
sc.stop()
}
case class LabelPoint(label:String,point:Array[Double])
import scala.math._
def getDistance(x:Array[Double],y:Array[Double]):Double={
sqrt(x.zip(y).map(z=>pow(z._1-z._2,2)).sum)
}
}上述內容就是KNN算法原理及Spark實現是怎樣的,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





