溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么利用Python網絡爬蟲獲取電影天堂視頻下載鏈接”,在日常操作中,相信很多人在怎么利用Python網絡爬蟲獲取電影天堂視頻下載鏈接問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么利用Python網絡爬蟲獲取電影天堂視頻下載鏈接”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
【一、項目背景】
相信大家都有一種頭疼的體驗,要下載電影特別費勁,對吧?要一部一部的下載,而且不能直觀的知道最近電影更新的狀態。
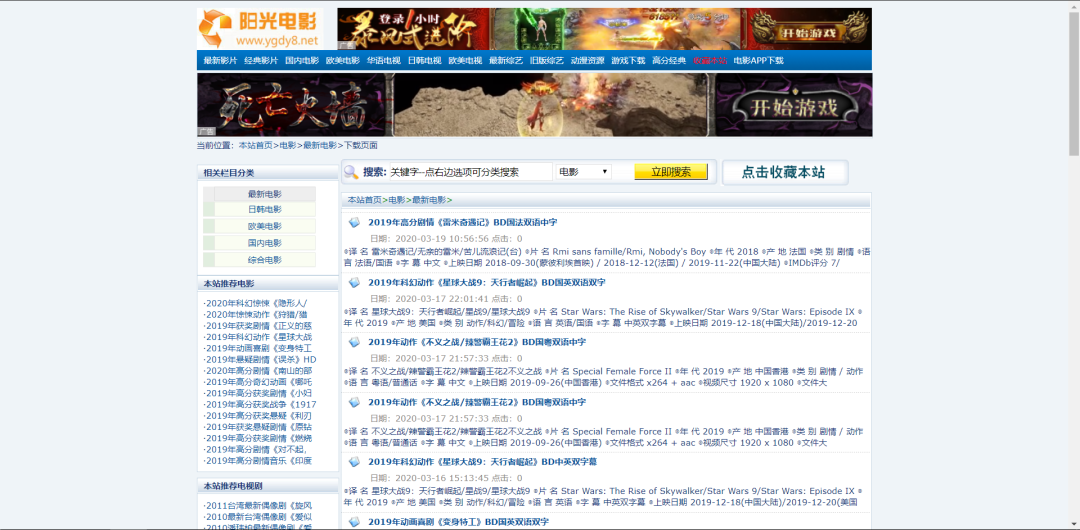
今天小編以電影天堂為例,帶大家更直觀的去看自己喜歡的電影,并且下載下來。
【二、項目準備】
首先 我們第一步我們要安裝一個Pycharm的軟件。Pycharm軟件安裝可以看這篇教程:Python環境搭建—安利Python小白的Python和Pycharm安裝詳細教程。
電影天堂網的網址:
https://www.ygdy8.net/html/gndy/dyzz/list_23_1.html
我們需要下載幾個庫,怎么下載呢?首先打開Pycharm點擊File再點開setting。
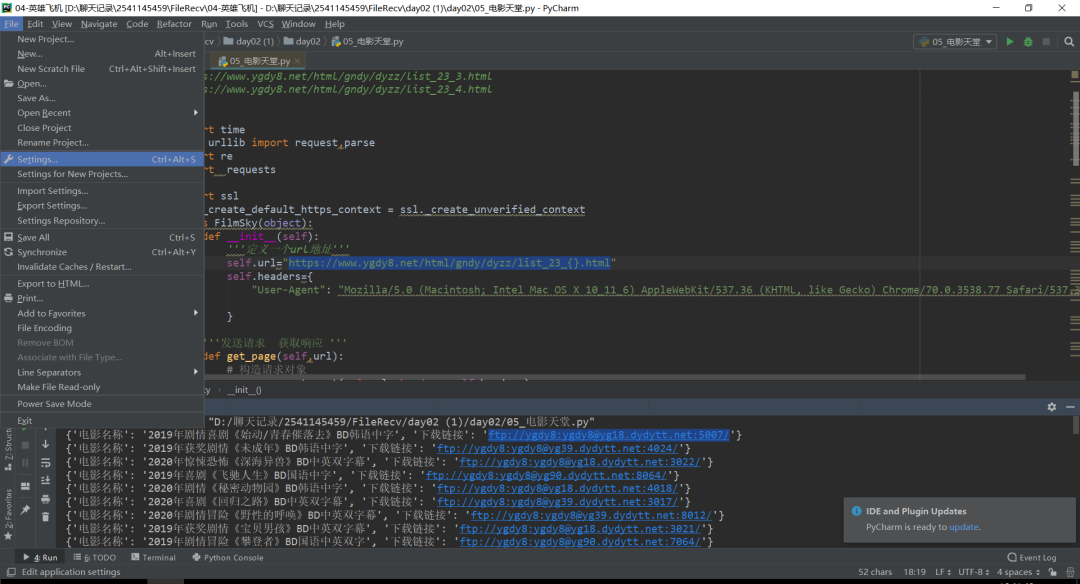
打開后會出現這個界面點擊你的項目名字(project:(你的項目名字))project interpreter點擊加號下載我們需要的庫本項目需要(requests,requests,time,re模塊),如下圖所示。
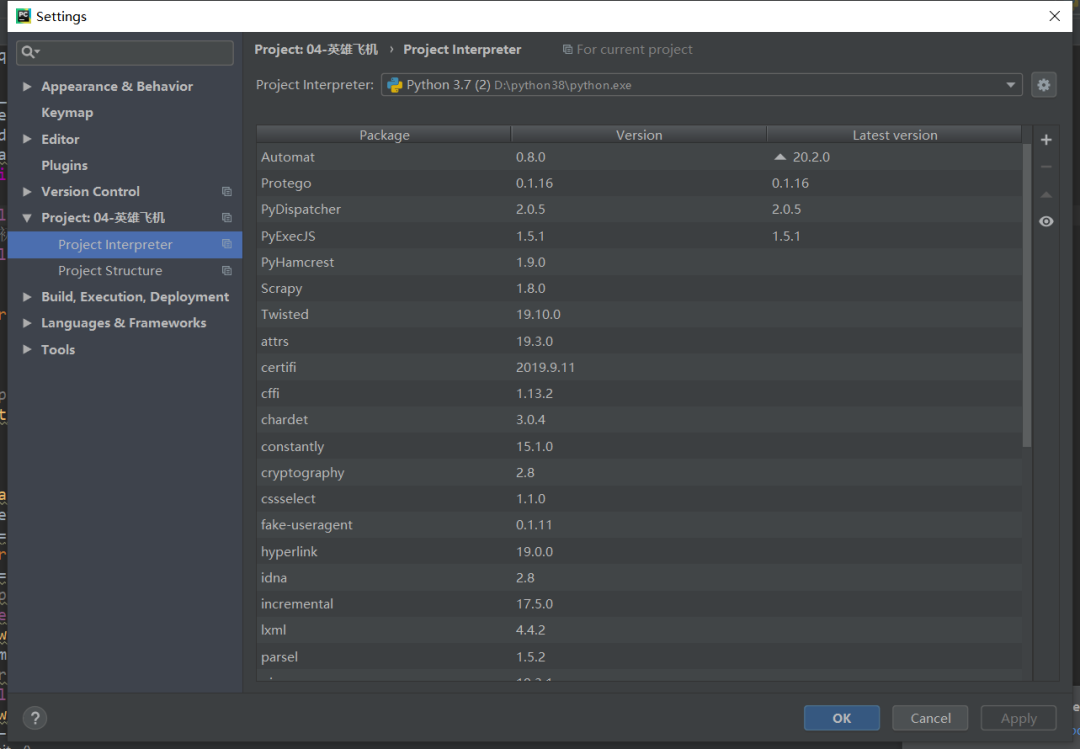
如果不會加載解釋器的話,可以參考這篇手把手教程:安裝好Pycharm后如何配置Python解釋器簡易教程。
如果還缺少相應庫的話,可以按照如下方式進行下載和安裝。

【三、項目實施】
我們需要(requests,requests,time,re模塊 ),如下圖所示。
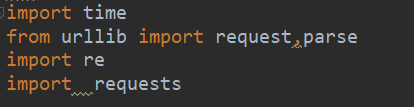
用封裝方法去實現各個部分功能。首先要寫一個框架 :構造一個類FilmSky 然后定義一個—init方法里繼承(self),再定義一個主方法(main)。最后實現這個main方法。代碼如下:
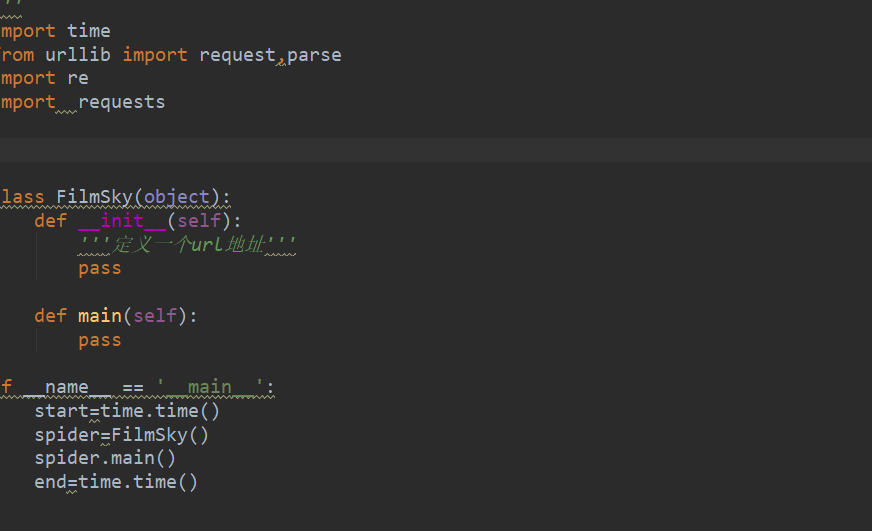
這個time是用于防止反爬,設置的時間延時。
首先我們來分析一下這個網址下一頁得到特點。
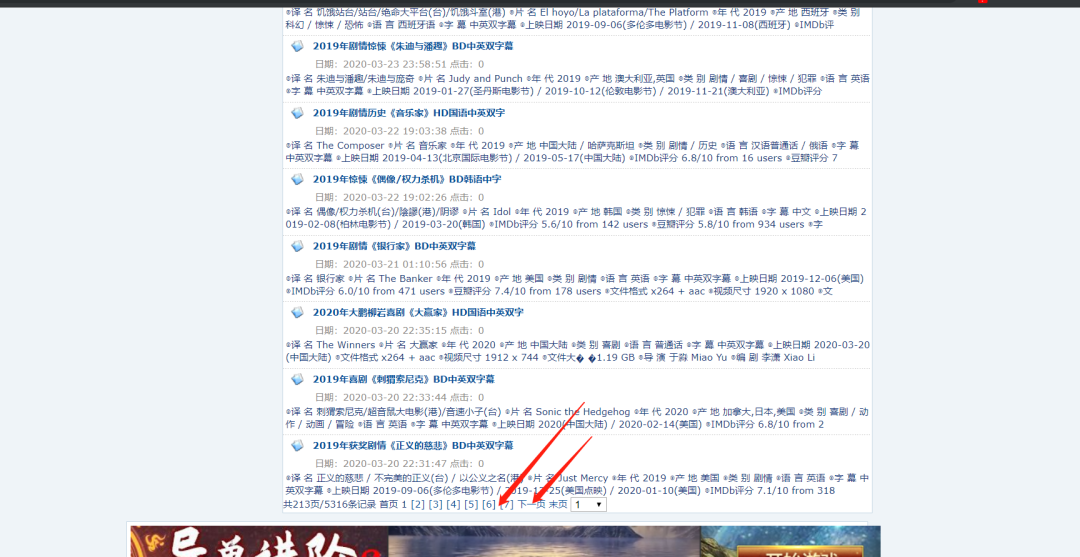
通過點擊了三頁我們會發現地址都是在原有的基礎上“23—3,4,5”這樣的變化。
我們可以用{}去代替變化的值就像這樣:
https://www.ygdy8.net/html/gndy/dyzz/list_23_{}.html
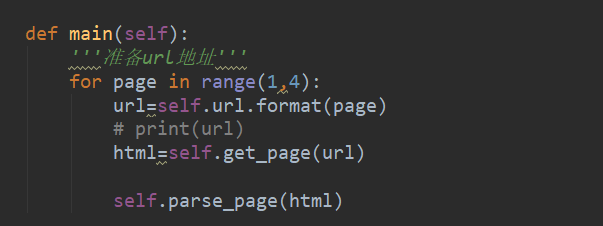
這樣我們在inti方法初始化url地址和構造請求頭。

在主方法main函數里邊用for循環實現遍歷網址。
得到下圖這樣的結果:
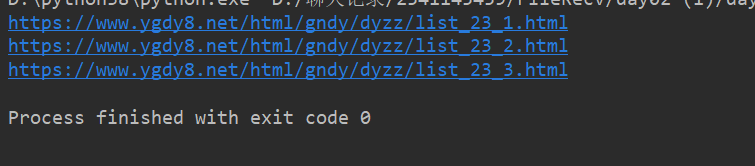
說明你已經成功一半了加油!!
現在我們需要對這些網址發生請求,為了更直觀的看出來,我們用一個類寫。
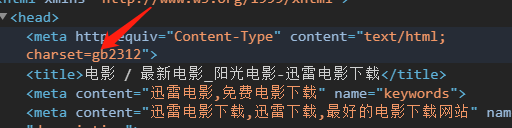
我們用requests發生請求 這個網站的編碼是gbk (怎么看網站的編碼?)。
打開一個網站右鍵檢查在header的標簽,以這個網站為例,可以看到charset=“gb312”。
這個gb2312就是編碼 我們常見的編碼方式有2種(utf_8, gbk)。
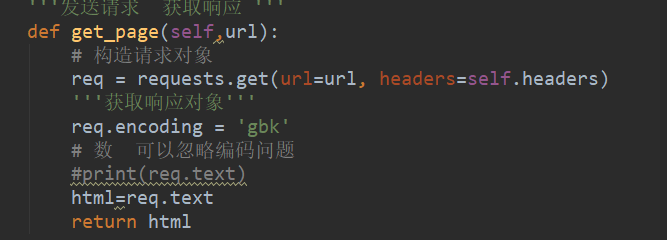
我們可以驗證一下是不是真的請求到了。使用Print(html)看到這個結果(一個完整的html網頁)說明請求成功。
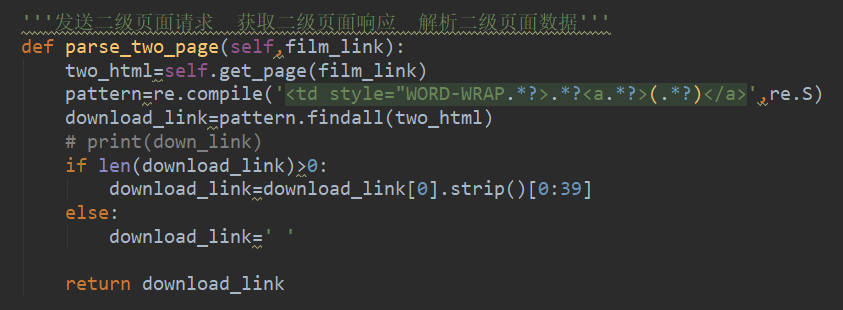
我們再定義這個方法(對我們的網頁代碼進行解析)。
我們用正則表達式 來解析數據 我們右鍵檢查可以看到我們要的網站在table里面的<tr>標簽的<b>標簽的<a>標簽的href。
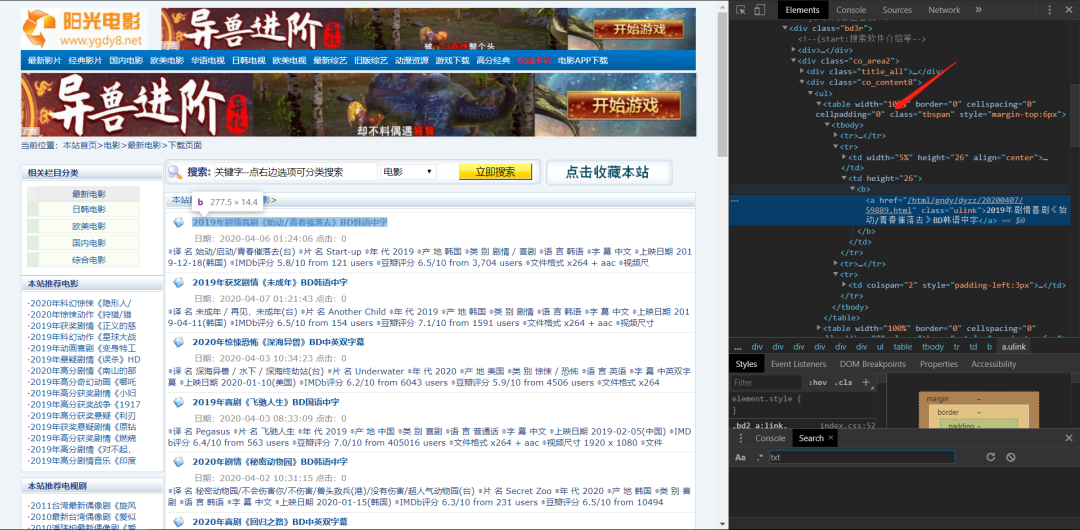
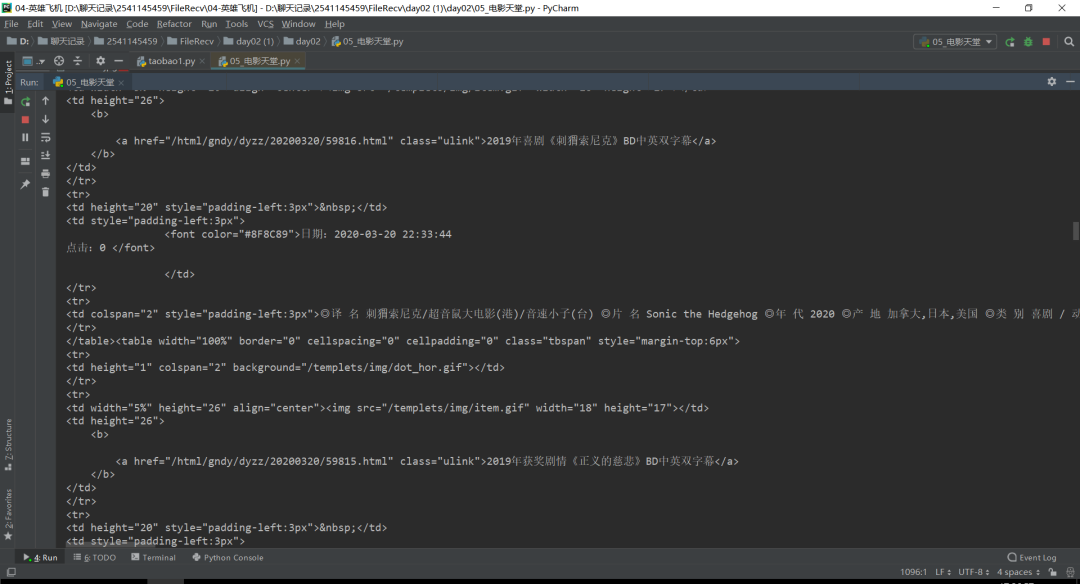
所以我們可以先找到table,一層一層的去找,可以參考一下下面的圖。

正則表達式就是(.*?)里面就是你想要得到的內容,“.*?”就是可以省略其中的標簽,取到你想要地區那一層。for循環遍歷得到每個網址,點擊這些網址我們要對二級頁面發生請求,并解析它。
因為在網頁網址上的鏈接有一些是空的 ,所有這樣會導致電影下載的鏈接不匹配。所以我們要加個判斷,如果下載鏈接的長度大于0那么就照常顯示,否則就給它一個空值,這樣就不會不對應了。最后返回這個結果,如下圖所示。
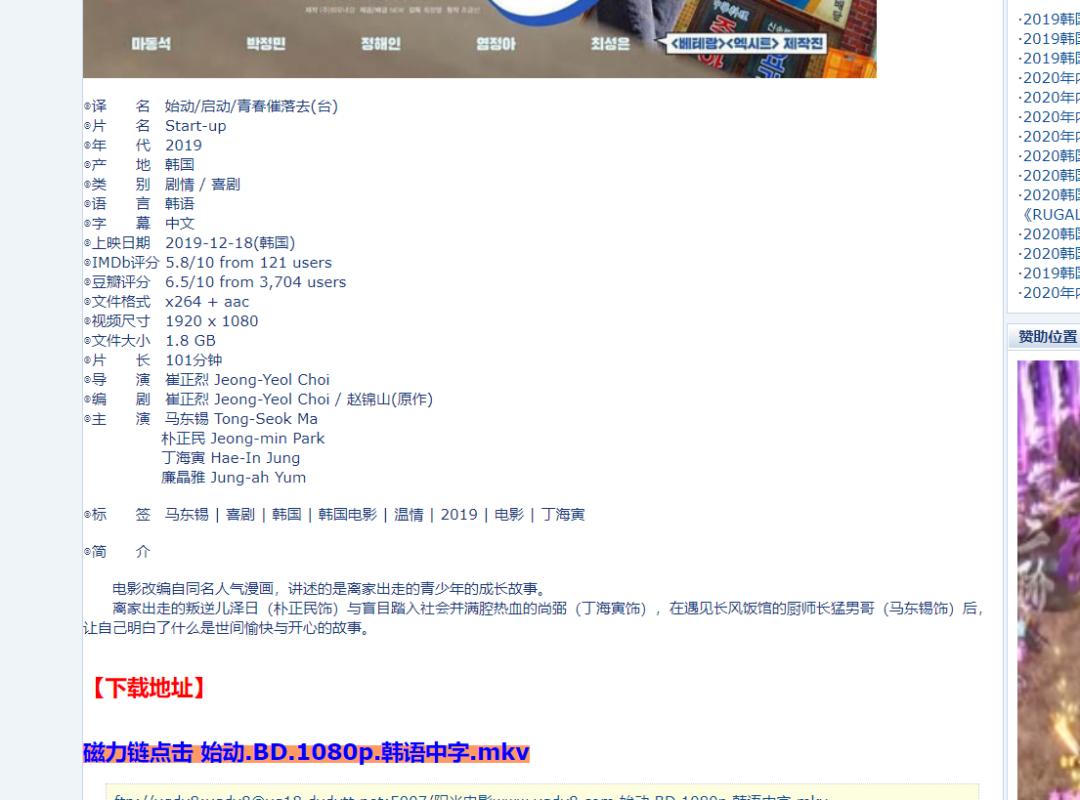
點開第二級頁面如圖右鍵點擊下載鏈接,如下圖所示:
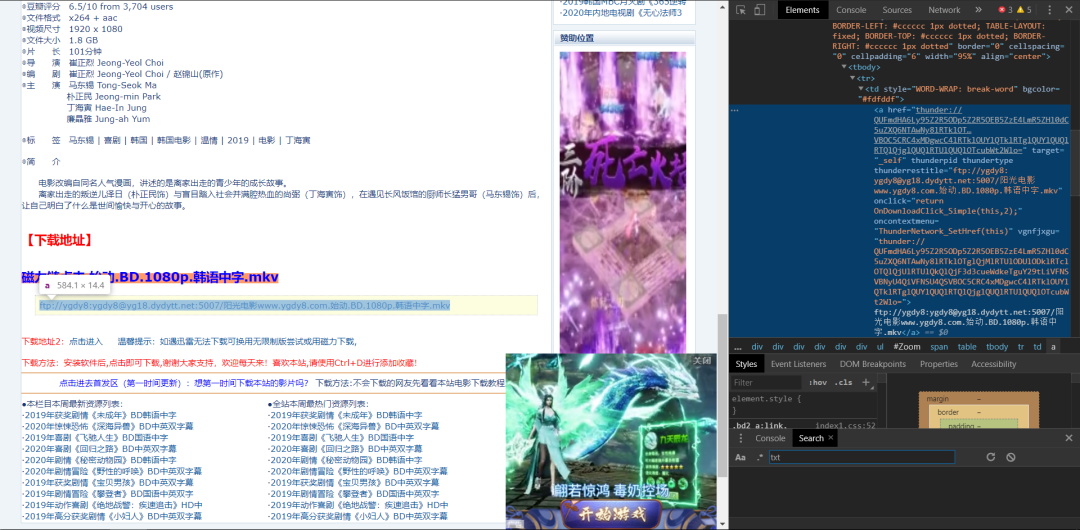
我們用正則表達式解析 得到我們下載鏈接地址,如下圖所示:
看去了不是很美觀,我們把鏈接處理一下,如下圖所示:

得到結果,如下圖所示:
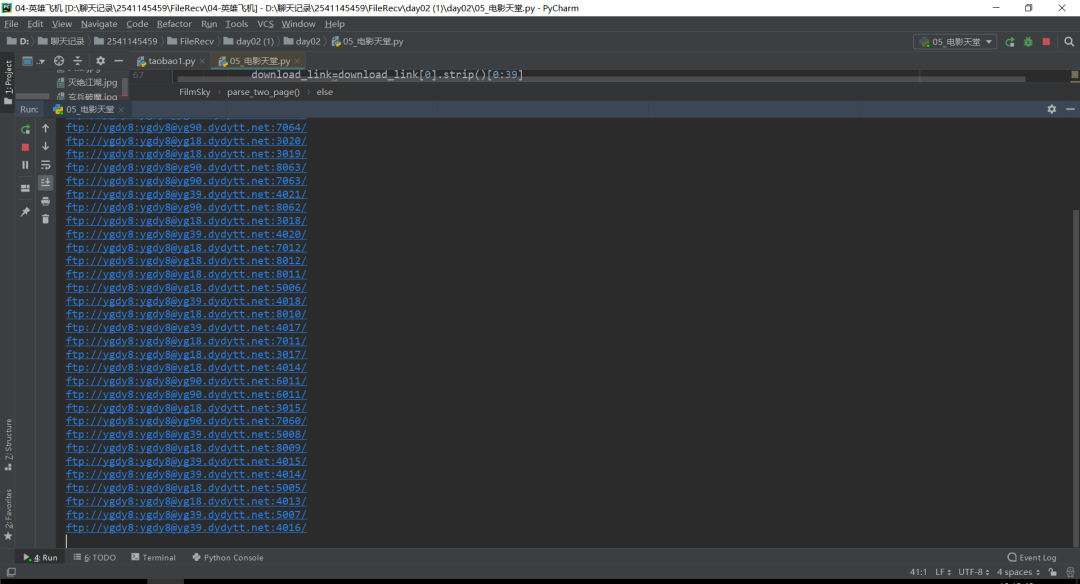
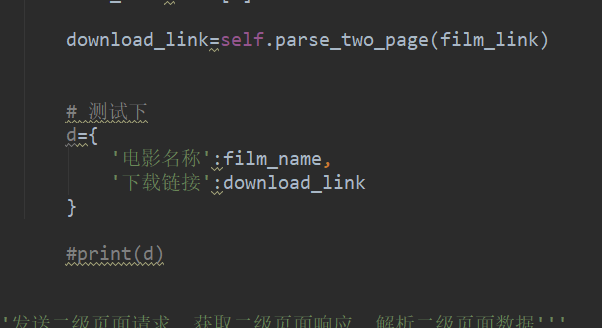
最后我們用把數據保存在一個字典加上下載鏈接和電影名字:
最后我們優化一下請求的代碼有點重復 我們優化一下;
用一個值去保存說明請求頭的內容以后請求我們只有調用這個方法進行請求就好,如下圖所示:

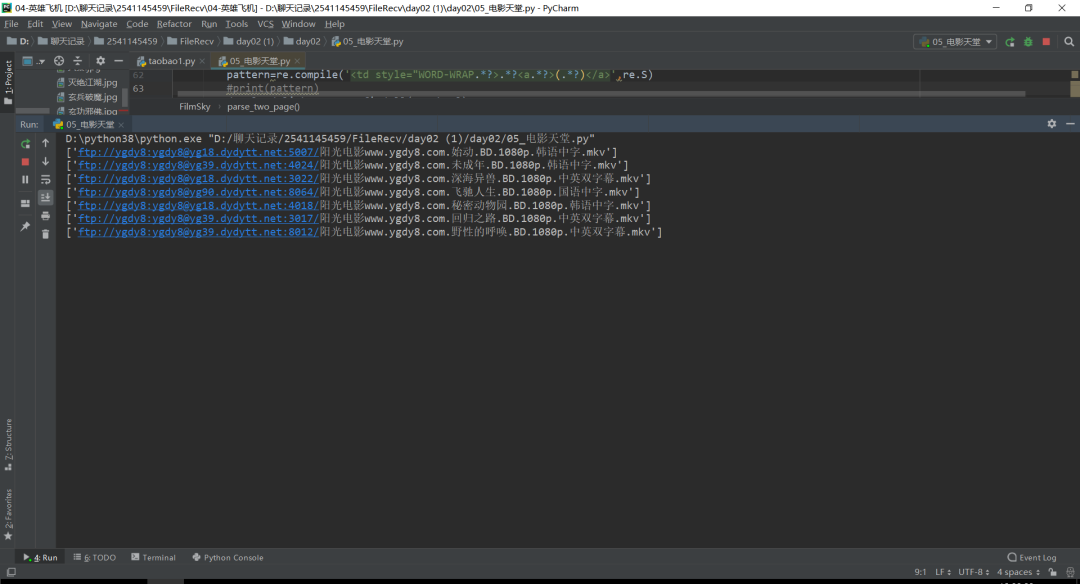
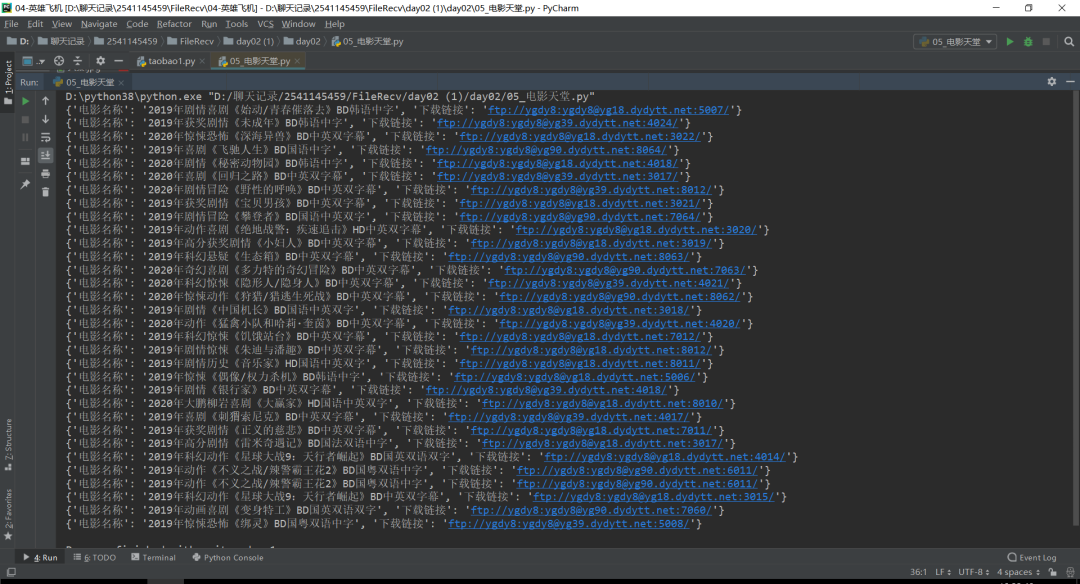
程序運行之后可以看到效果圖,如下圖所示:
到此,關于“怎么利用Python網絡爬蟲獲取電影天堂視頻下載鏈接”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





