溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關MySQL中SQL優化建議的示例分析,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
今天早上看到同事的一個優化需求,優化的時間其實不多,但是對于這條SQL的優化思考了很多,希望有一些參考。
業務同學提供的SQL如下:
SELECT b.order_id FROM ( SELECT a.order_id, a.order_time AS create_time FROM trade_order a WHERE a.user_id = 12345678 。。。。。。 AND a.deleted = 0 UNION SELECT v.order_id, v.create_time FROM virtual_order v WHERE v.user_id = 12345678 。。。。 ORDER BY order_id DESC ) AS b LIMIT 0, 10;
根據反饋,這條SQL的執行時長在200毫秒,在壓測情況下會到500毫秒左右,從業務層面來看,目前是不滿足需求的,想看看我們有沒有優化的建議。
第一印象這條SQL執行時長200~500毫秒,要優化好像可打的牌不多啊,如果要想得到一個可接受的基準值,當然反饋會是越快越好。所以從這個角度來看,我們不妨按照毫秒級優化的標準來看,這條SQL需要做哪些補充的工作。
首先通過SQL看下邏輯情況,整體的邏輯是按照用戶id去查詢兩個數據源(trade_order和virtual_order),從兩個數據源查詢出10條單號數據返回。這個用戶在兩個數據源中可能有單號,也可能沒有,只要有匹配的就返回,累計返回10條,看起來是為了去重才選擇了union的組合方式。
先不看表結構信息,我大體有了如下的建議:
union的模式更建議采用union all,兩個數據源存在數據重合應該是不合理的。
查詢語句里面使用了order_time但是數據返回壓根沒有用到,建議去掉
SQL層面承載了太多的數據處理壓力,比如多數據源,去重和過濾,分頁,是不是可以做下精簡。
當然到了這里,和業務的需求就產生了脫節,這就屬于那種看啥都不順眼的狀態,總想找出點問題來,而且對于業務同學來說,哪怕十個八個需求,你得有一個需求的收益更高,他們采用其他需求的可能性才越大,否則就是不作為了。
所以到了這里,我們開始做下分析,要優化SQL不看看執行計劃是不過關的,在執行前,我的大體感覺表數據量很大,應該是生成了派生表,然后在數據去重過濾層面的消耗比較大,而兩個子查詢來說,返回的結果集應該很少。 預測的執行情況是:
1)子查詢trade_order應該很快,毫米級響應
2)子查詢virtual_order應該也很快,但是最后有一個order by操作,可能代價略高
3)union的去重過濾代價相對較大,涉及到兩個結果集的合并,如果返回結果較多,可能是瓶頸
從執行結果來看,讓我有些意外,其中virtual_order的返回結果竟然有40多萬行,相當于直接走了全表掃描。

而其他的部分也會收到相關影響,所以后續的處理都會受到影響。
為了快速定位問題,我把兩個子查詢拆開單獨執行,查看執行計劃,這是分析瓶頸最快的一種處理思路。
>>explain SELECT -> v.order_id, -> v.create_time -> FROM -> virtual_order v -> WHERE -> v.user_id = 12345678 。。。;
執行計劃如下:

可以看到是直接走了全表掃描,這是一個基礎需求,不會業務同學漏了索引吧,然后查看表結構:
CREATE TABLE `virtual_order` ( `order_id` varchar(255) NOT NULL COMMENT '訂單ID', 。。。 `user_id` varchar(255) DEFAULT NULL COMMENT '用戶ID', 。。。 `refund` tinyint(3) DEFAULT NULL COMMENT ' 是否退款(1:無,2:是)', `atc_pay_status` int(3) NOT NULL DEFAULT '0' COMMENT '支付狀態', 。。。 PRIMARY KEY (`order_id`), KEY `order_status` (`order_status`), KEY `user_id` (`user_id`), KEY `prepaid_account` (`prepaid_account`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
發現user_id是走了索引的,那么問題來了,user_id既然是索引,但是為什么SQL語句中依然走了全表掃描呢?
此處思考10秒鐘,繼續往下看。
其實這個時候問題的邊界都很清晰了,SQL語句很簡單,索引也存在,走了全表掃描,在MySQL中可以暫時排除直方圖的影響,目前在5.7版本中還不存在直方圖的特性,那么結果只有一個:字段的類型產生了隱式類型轉換。
這個部分可以參考這篇的一篇文章
MySQL中需要重視的隱式轉換
比如初始化語句如下:
create table test(id int primary key,name varchar(20) ,key idx_name(name)); insert into test values(1,'10'),(2,'20');
然后我們使用如下的兩條語句進行執行計劃的對比測試。
explain select * from test where name=20; explain select * from test where name=’20’;
在name列為字符類型時,得到的執行計劃列表如下:
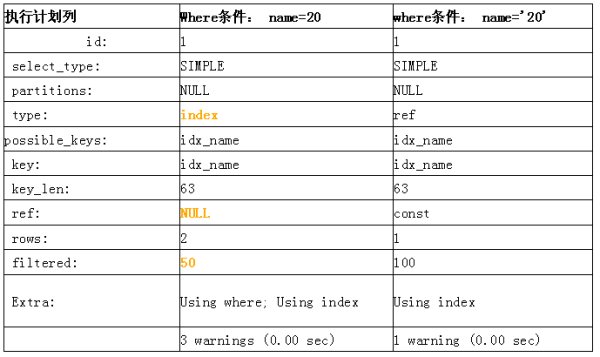
可以很明顯的看到,在name為字符串類型時,如果where條件為name=20,則執行全索引掃描,查看warning信息會明確提示:
Message: Cannot use range access on index 'idx_name' due to type or collation conversion on field 'name'
所以此處的問題也顯而易見了。
修改了子查詢的條件為字符后,整個SQL的執行效率就立馬好多了。
使用sql_no_cache的方式測試。
SQL修改前性能:
+-----------------------+ 2 rows in set (0.27 sec) 修改后性能: +-----------------------+ 2 rows in set (0.00 sec)
然后再次查看執行計劃,就都規規矩矩了,這樣我們就解決了瓶頸問題,而那些規范,更好的改進就可以逐步展開了,而從建議的角度來看,采用的概率也會高一些。

當然在這個基礎上確實有一些補充的建議,在定位瓶頸之后也可以攤開來說了。
優化不是一錘子買賣,在這個基礎上,也發現了一些其他的問題,可以看下這個表的表結構信息,其實能夠發現一些設計上的小問題。
1) 表字段的字符型基本都是varchar(255),需要盡可能避免這種使用習慣,對于存儲性能的開銷會有顯著影響
2)使用的int類型 int(3),這種使用對于int還是存儲4個字節,但是有限范圍大大減少,可以考慮更小的數值類型
3)表的索引比較松散,可以根據業務模型創建復合索引,比如user_id和status的結合場景更多,應該創建的是(user_id,status)的復合索引
上述就是小編為大家分享的MySQL中SQL優化建議的示例分析了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





