溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Hadoop架構原理怎么理解”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Hadoop架構原理怎么理解”吧!
一、概念
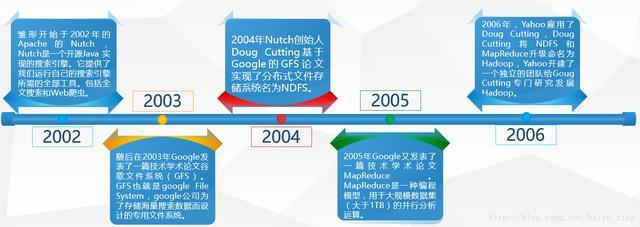
Hadoop誕生于2006年,是一款支持數據密集型分布式應用并以Apache 2.0許可協議發布的開源軟件框架。它支持在商品硬件構建的大型集群上運行的應用程序。Hadoop是根據Google公司發表的MapReduce和Google檔案系統的論文自行實作而成。
Hadoop與Google一樣,都是小孩命名的,是一個虛構的名字,沒有特別的含義。從計算機專業的角度看,Hadoop是一個分布式系統基礎架構,由Apache基金會開發。Hadoop的主要目標是對分布式環境下的“大數據”以一種可靠、高效、可伸縮的方式處理。
Hadoop框架透明地為應用提供可靠性和數據移動。它實現了名為MapReduce的編程范式:應用程序被分割成許多小部分,而每個部分都能在集群中的任意節點上執行或重新執行。
Hadoop還提供了分布式文件系統,用以存儲所有計算節點的數據,這為整個集群帶來了非常高的帶寬。MapReduce和分布式文件系統的設計,使得整個框架能夠自動處理節點故障。它使應用程序與成千上萬的獨立計算的電腦和PB級的數據。
二、組成
1.Hadoop的核心組件
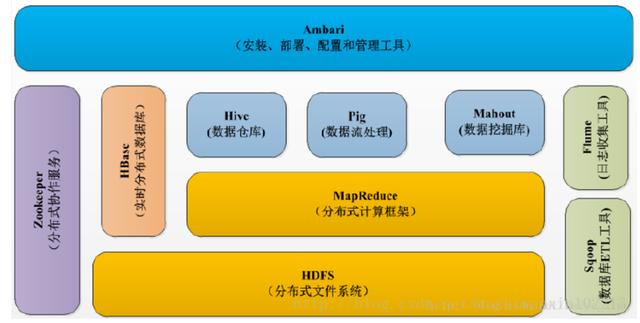
分析:Hadoop的核心組件分為:HDFS(分布式文件系統)、MapRuduce(分布式運算編程框架)、YARN(運算資源調度系統)
2.HDFS的文件系統
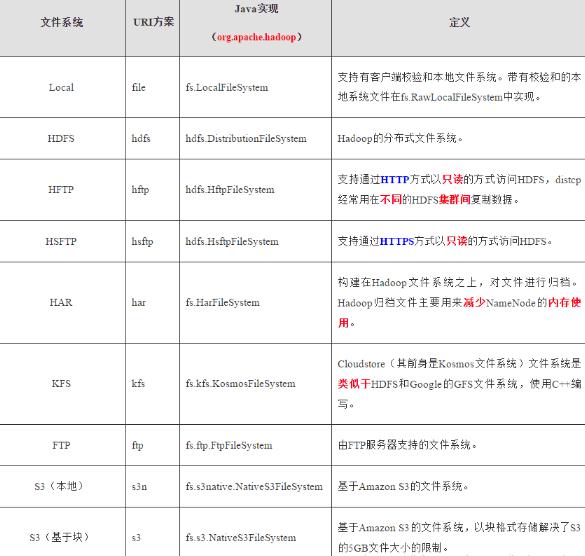
HDFS
1.定義
整個Hadoop的體系結構主要是通過HDFS(Hadoop分布式文件系統)來實現對分布式存儲的底層支持,并通過MR來實現對分布式并行任務處理的程序支持。
HDFS是Hadoop體系中數據存儲管理的基礎。它是一個高度容錯的系統,能檢測和應對硬件故障,用于在低成本的通用硬件上運行。HDFS簡化了文件的一致性模型,通過流式數據訪問,提供高吞吐量應用程序數據訪問功能,適合帶有大型數據集的應用程序。
2.組成
HDFS采用主從(Master/Slave)結構模型,一個HDFS集群是由一個NameNode和若干個DataNode組成的。NameNode作為主服務器,管理文件系統命名空間和客戶端對文件的訪問操作。DataNode管理存儲的數據。HDFS支持文件形式的數據。
從內部來看,文件被分成若干個數據塊,這若干個數據塊存放在一組DataNode上。NameNode執行文件系統的命名空間,如打開、關閉、重命名文件或目錄等,也負責數據塊到具體DataNode的映射。DataNode負責處理文件系統客戶端的文件讀寫,并在NameNode的統一調度下進行數據庫的創建、刪除和復制工作。NameNode是所有HDFS元數據的管理者,用戶數據永遠不會經過NameNode。
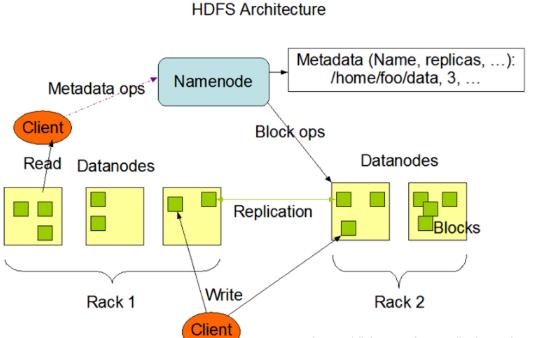
分析:NameNode是管理者,DataNode是文件存儲者、Client是需要獲取分布式文件系統的應用程序。
MapReduce
1.定義
Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是一種計算模型,用以進行大數據量的計算。其中Map對數據集上的獨立元素進行指定的操作,生成鍵-值對形式中間結果。Reduce則對中間結果中相同“鍵”的所有“值”進行規約,以得到最終結果。MapReduce這樣的功能劃分,非常適合在大量計算機組成的分布式并行環境里進行數據處理。
2.組成
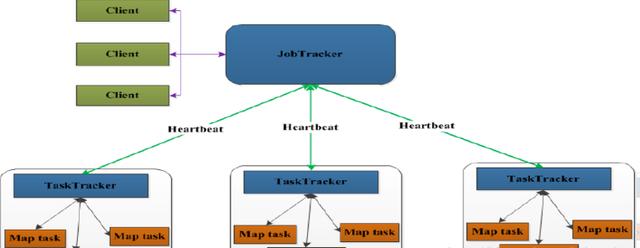
分析:
(1)JobTracker
JobTracker叫作業跟蹤器,運行到主節點(Namenode)上的一個很重要的進程,是MapReduce體系的調度器。用于處理作業(用戶提交的代碼)的后臺程序,決定有哪些文件參與作業的處理,然后把作業切割成為一個個的小task,并把它們分配到所需要的數據所在的子節點。
Hadoop的原則就是就近運行,數據和程序要在同一個物理節點里,數據在哪里,程序就跑去哪里運行。這個工作是JobTracker做的,監控task,還會重啟失敗的task(于不同的節點),每個集群只有唯一一個JobTracker,類似單點的NameNode,位于Master節點
(2)TaskTracker
TaskTracker叫任務跟蹤器,MapReduce體系的最后一個后臺進程,位于每個slave節點上,與datanode結合(代碼與數據一起的原則),管理各自節點上的task(由jobtracker分配),
每個節點只有一個tasktracker,但一個tasktracker可以啟動多個JVM,運行Map Task和Reduce Task;并與JobTracker交互,匯報任務狀態,
Map Task:解析每條數據記錄,傳遞給用戶編寫的map(),并執行,將輸出結果寫入本地磁盤(如果為map-only作業,直接寫入HDFS)。
Reducer Task:從Map Task的執行結果中,遠程讀取輸入數據,對數據進行排序,將數據按照分組傳遞給用戶編寫的reduce函數執行。
Hive
1.定義
Hive是基于Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,并提供完整的sql查詢功能,可以將sql語句轉換為MapReduce任務進行運行。
Hive是建立在 Hadoop 上的數據倉庫基礎構架。它提供了一系列的工具,可以用來進行數據提取轉化加載(ETL),這是一種可以存儲、查詢和分析存儲在 Hadoop 中的大規模數據的機制。
Hive 定義了簡單的類 SQL 查詢語言,稱為 HQL,它允許熟悉 SQL 的用戶查詢數據。同時,這個語言也允許熟悉 MapReduce 開發者的開發自定義的 mapper 和 reducer 來處理內建的 mapper 和 reducer 無法完成的復雜的分析工作。
2.組成
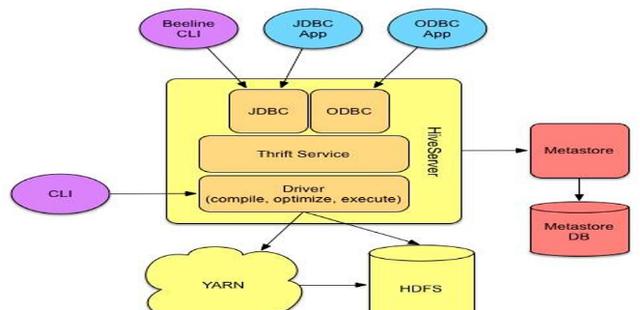
分析:Hive架構包括:CLI(Command Line Interface)、JDBC/ODBC、Thrift Server、WEB GUI、Metastore和Driver(Complier、Optimizer和Executor),這些組件分為兩大類:服務端組件和客戶端組件
3.客戶端與服務端組件
(1)客戶端組件:
CLI:Command Line Interface,命令行接口。
Thrift客戶端:上面的架構圖里沒有寫上Thrift客戶端,但是Hive架構的許多客戶端接口是建立在Thrift客戶端之上,包括JDBC和ODBC接口。
WEBGUI:Hive客戶端提供了一種通過網頁的方式訪問Hive所提供的服務。這個接口對應Hive的HWI組件(Hive Web Interface),使用前要啟動HWI服務。
(2)服務端組件:
Driver組件:該組件包括Complier、Optimizer和Executor,它的作用是將HiveQL(類SQL)語句進行解析、編譯優化,生成執行計劃,然后調用底層的MapReduce計算框架
Metastore組件:元數據服務組件,這個組件存儲Hive的元數據,Hive的元數據存儲在關系數據庫里,Hive支持的關系數據庫有Derby和Mysql。元數據對于Hive十分重要,因此Hive支持把Metastore服務獨立出來,安裝到遠程的服務器集群里,從而解耦Hive服務和Metastore服務,保證Hive運行的健壯性;
Thrift服務:Thrift是Facebook開發的一個軟件框架,它用來進行可擴展且跨語言的服務的開發,Hive集成了該服務,能讓不同的編程語言調用Hive的接口。
4.Hive與傳統數據庫的異同
(1)查詢語言
由于 SQL 被廣泛的應用在數據倉庫中,因此專門針對Hive的特性設計了類SQL的查詢語言HQL。熟悉SQL開發的開發者可以很方便的使用Hive進行開發。
(2)數據存儲位置
Hive是建立在Hadoop之上的,所有Hive的數據都是存儲在HDFS中的。而數據庫則可以將數據保存在塊設備或者本地文件系統中。
(3)數據格式
Hive中沒有定義專門的數據格式,數據格式可以由用戶指定,用戶定義數據格式需要指定三個屬性:列分隔符(通常為空格、”\t”、”\\x001″)、行分隔符(”\n”)以及讀取文件數據的方法(Hive中默認有三個文件格式TextFile,SequenceFile以及RCFile)。
(4)數據更新
由于Hive是針對數據倉庫應用設計的,而數據倉庫的內容是讀多寫少的。因此,Hive中不支持
對數據的改寫和添加,所有的數據都是在加載的時候中確定好的。而數據庫中的數據通常是需要經常進行修改的,因此可以使用INSERT INTO … VALUES添加數據,使用UPDATE … SET修改數據。
(5)索引
Hive在加載數據的過程中不會對數據進行任何處理,甚至不會對數據進行掃描,因此也沒有對數據中的某些Key建立索引。Hive要訪問數據中滿足條件的特定值時,需要暴力掃描整個數據,因此訪問延遲較高。由于MapReduce的引入, Hive可以并行訪問數據,因此即使沒有索引,對于大數據量的訪問,Hive仍然可以體現出優勢。數據庫中,通常會針對一個或者幾個列建立索引,因此對于少量的特定條件的數據的訪問,數據庫可以有很高的效率,較低的延遲。由于數據的訪問延遲較高,決定了Hive不適合在線數據查詢。
(6)執行
Hive中大多數查詢的執行是通過Hadoop提供的MapReduce來實現的(類似select * from tbl的查詢不需要MapReduce)。而數據庫通常有自己的執行引擎。
(7)執行延遲
Hive在查詢數據的時候,由于沒有索引,需要掃描整個表,因此延遲較高。另外一個導致Hive執行延遲高的因素是MapReduce框架。由于MapReduce本身具有較高的延遲,因此在利用MapReduce執行Hive查詢時,也會有較高的延遲。相對的,數據庫的執行延遲較低。當然,這個低是有條件的,即數據規模較小,當數據規模大到超過數據庫的處理能力的時候,Hive的并行計算顯然能體現出優勢。
(8)可擴展性
由于Hive是建立在Hadoop之上的,因此Hive的可擴展性是和Hadoop的可擴展性是一致的(世界上最大的Hadoop集群在Yahoo!,2009年的規模在4000臺節點左右)。而數據庫由于ACID語義的嚴格限制,擴展行非常有限。目前最先進的并行數據庫Oracle在理論上的擴展能力也只有100臺左右。
(9)數據規模
由于Hive建立在集群上并可以利用MapReduce進行并行計算,因此可以支持很大規模的數據;對應的,數據庫可以支持的數據規模較小。
Hbase
1.定義
HBase – Hadoop Database,是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統,利用HBase技術可在廉價PC Server上搭建起大規模結構化存儲集群。
HBase是Google Bigtable的開源實現,類似Google Bigtable利用GFS作為其文件存儲系統,HBase利用Hadoop HDFS作為其文件存儲系統;
Google運行MapReduce來處理Bigtable中的海量數據,HBase同樣利用Hadoop MapReduce來處理HBase中的海量數據;
Google Bigtable利用 Chubby作為協同服務,HBase利用Zookeeper作為協同服務。
2.組成
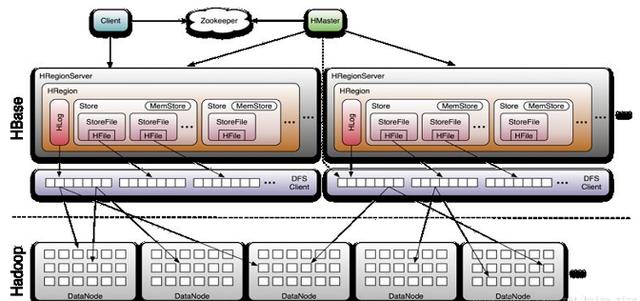
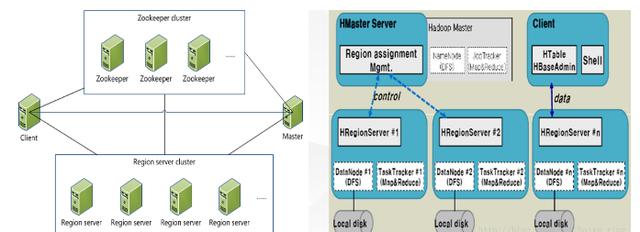
分析:從上圖可以看出:Hbase主要由Client、Zookeeper、HMaster和HRegionServer組成,由Hstore作存儲系統。
Client
HBase Client使用HBase的RPC機制與HMaster和HRegionServer進行通信,對于管理類操作,Client與 HMaster進行RPC;對于數據讀寫類操作,Client與HRegionServer進行RPC
Zookeeper
Zookeeper Quorum 中除了存儲了 -ROOT- 表的地址和 HMaster 的地址,HRegionServer 也會把自己以 Ephemeral 方式注冊到 Zookeeper 中,使得 HMaster 可以隨時感知到各個HRegionServer 的健康狀態。
HMaster
HMaster 沒有單點問題,HBase 中可以啟動多個 HMaster ,通過 Zookeeper 的 Master Election 機制保證總有一個 Master 運行,HMaster 在功能上主要負責 Table和Region的管理工作:
管理用戶對 Table 的增、刪、改、查操作
管理 HRegionServer 的負載均衡,調整 Region 分布
在 Region Split 后,負責新 Region 的分配
在 HRegionServer 停機后,負責失效 HRegionServer 上的 Regions 遷移
HStore存儲是HBase存儲的核心了,其中由兩部分組成,一部分是MemStore,一部分是StoreFiles。
MemStore是Sorted Memory Buffer,用戶寫入的數據首先會放入MemStore,當MemStore滿了以后會Flush成一個StoreFile(底層實現是HFile), 當StoreFile文件數量增長到一定閾值,會觸發Compact合并操作,將多個 StoreFiles 合并成一個 StoreFile,合并過程中會進行版本合并和數據刪除。
因此可以看出HBase其實只有增加數據,所有的更新和刪除操作都是在后續的 compact 過程中進行的,這使得用戶的寫操作只要進入內存中就可以立即返回,保證了 HBase I/O 的高性能。
當StoreFiles Compact后,會逐步形成越來越大的StoreFile,當單個 StoreFile 大小超過一定閾值后,會觸發Split操作,同時把當前 Region Split成2個Region,父 Region會下線,新Split出的2個孩子Region會被HMaster分配到相應的HRegionServer 上,使得原先1個Region的壓力得以分流到2個Region上。
三、Hadoop的應用實例
1.回顧Hadoop的整體架構
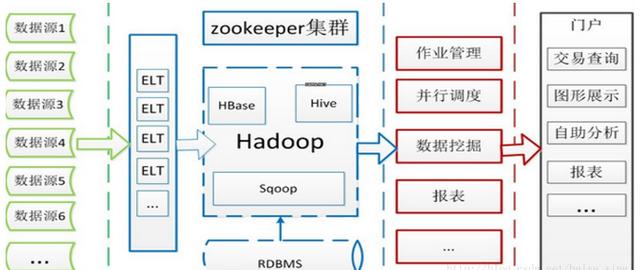
2.Hadoop的應用——流量查詢系統
(1)流量查詢系統總體框架
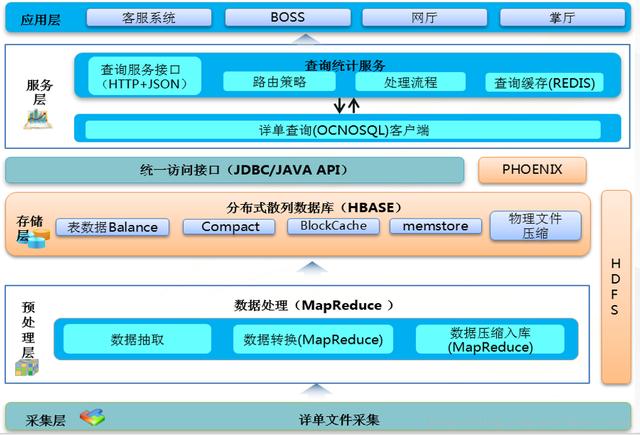
(2)流量查詢系統總體流程
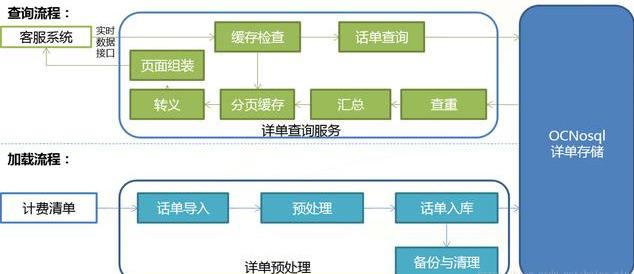
(3)流量查詢系統數據預處理功能框架
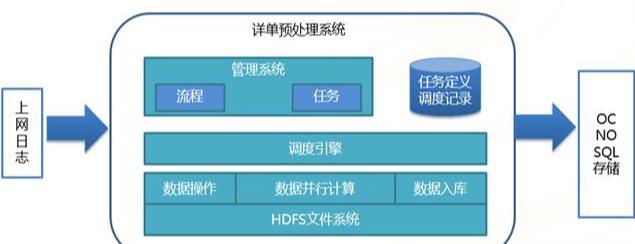
(4)流量查詢系統數據預處理流程
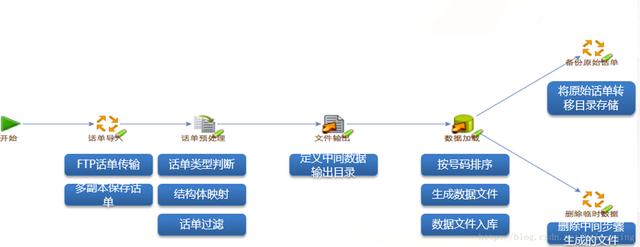
(5)流量查詢NoSQL數據庫功能框架
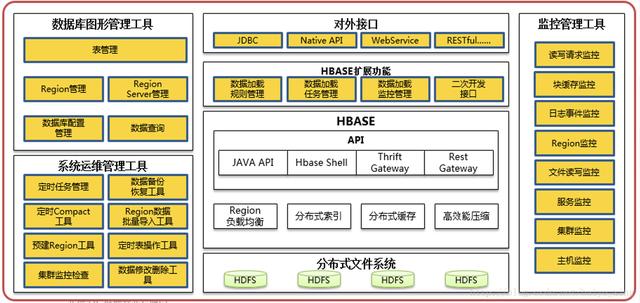
(6)流量查詢服務功能框架
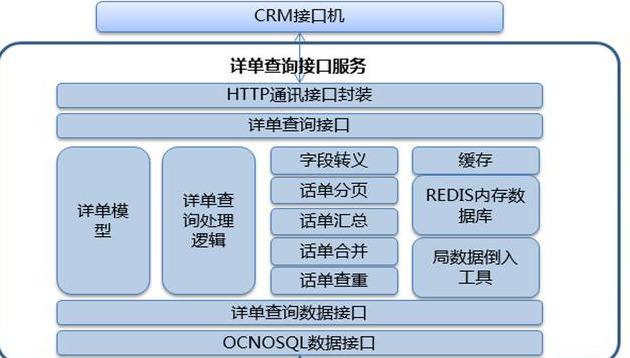
(7)實時流計算數據處理流程圖
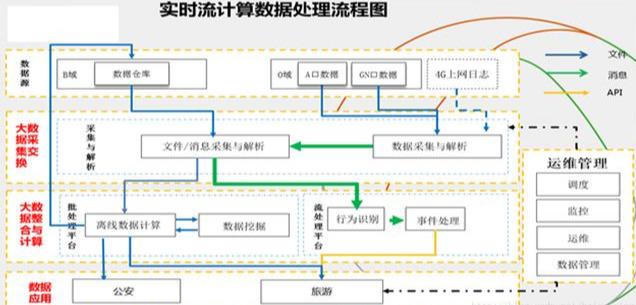
到此,相信大家對“Hadoop架構原理怎么理解”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





