溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編今天帶大家了解數據倉庫中的OLTP與OLAP查詢是怎樣的,文中知識點介紹的非常詳細。覺得有幫助的朋友可以跟著小編一起瀏覽文章的內容,希望能夠幫助更多想解決這個問題的朋友找到問題的答案,下面跟著小編一起深入學習“數據倉庫中的OLTP與OLAP查詢是怎樣的”的知識吧。
在業務數據處理的早期,對數據庫的寫操作通常對應于正在發生的商業交易-進行銷售,與供應商下訂單,支付員工的工資等。隨著數據庫擴展到不涉及的領域 涉及貨幣易手,但是交易一詞仍然存在,是指構成邏輯單元的一組讀寫操作。 這些類型的查詢稱為事務處理系統查詢(OLTP)。 為這些查詢設計的系統通常是面向用戶的,這意味著它們可能會看到大量的請求。 為了處理負載,應用程序通常僅在每個查詢中觸摸少量記錄。 該應用程序使用某種密鑰來請求記錄,而存儲引擎使用索引來查找所請求密鑰的數據。 磁盤查找時間通常是這里的瓶頸。
但是,數據庫也開始越來越多地用于數據分析,而這種數據分析具有非常不同的訪問模式。 通常,分析查詢需要掃描大量記錄,僅讀取每條記錄的幾列,并計算匯總統計信息(例如計數,總和或平均值),而不是將原始數據返回給用戶。 例如,如果您的數據是銷售交易表,則分析查詢可能是:
一月份,我們每家商店的總收入是多少?
在最近的促銷活動中,我們售出的iPhone比平時多了多少?
哪個品牌的牛奶最常與家樂氏的玉米片一起購買?
這些查詢通常由業務分析人員編寫,并饋入有助于公司管理層做出更好決策(業務智能)的報告。 為了將這種使用數據庫的模式與事務處理區分開來,它被稱為在線分析處理(OLAP)。 它們之所以鮮為人知,是因為它們是由業務分析師而不是最終用戶處理的。 與OLTP系統相比,它們處理的查詢量要少得多,但每個查詢的要求通常很高,需要在短時間內掃描數百萬條記錄。 磁盤帶寬(不是尋道時間)通常是這里的瓶頸,而面向列的存儲是此類工作負載越來越流行的解決方案。
OLTP和OLAP之間的區別并不總是很明確,但是下面列出了一些典型特征。
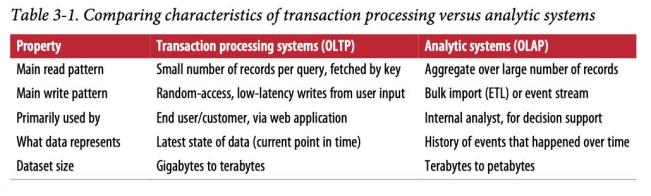
首先,將相同的數據庫用于事務處理和分析查詢。事實證明,SQL在這方面非常靈活:它對于OLTP類型查詢和OLAP類型查詢都適用。盡管如此,在1980年代末和1990年代初,公司有一種趨勢是停止使用OLTP系統進行分析,而改為在單獨的數據庫上運行分析。這個獨立的數據庫稱為數據倉庫。
企業可能具有數十種不同的交易處理系統:為面向客戶的網站提供動力的系統,實體商店中的銷售點(結帳)系統,倉庫中的庫存跟蹤,車輛路線規劃,供應商管理,員工管理等。這些系統中的一個很復雜,需要一個團隊來維護它,因此這些系統最終只能彼此獨立地運行。通常期望這些OLTP系統具有高可用性,并以低延遲處理事務,因為它們通常對業務運營至關重要。因此,數據庫管理員密切保護其OLTP數據庫。他們通常不愿讓業務分析人員在OLTP數據庫上運行臨時分析查詢,因為這些查詢通常很昂貴,會掃描數據集的大部分,這可能會損害并發執行事務的性能。
數據倉庫
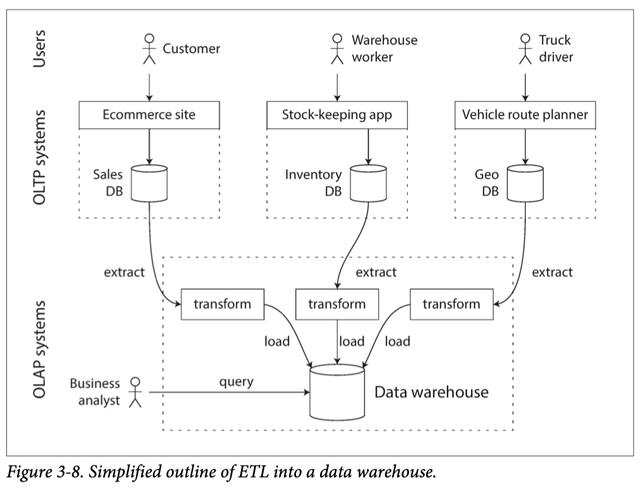
相比之下,數據倉庫是一個獨立的數據庫,分析人員可以查詢其內心的內容,而不會影響OLTP操作。數據倉庫包含公司所有各種OLTP系統中數據的只讀副本。從OLTP數據庫中提取數據(使用定期數據轉儲或連續的更新流),將其轉換為易于分析的模式,進行清理,然后將其加載到數據倉庫中。將數據放入倉庫的過程稱為"提取-轉換-加載(ETL)"。現在,幾乎所有大型企業都存在數據倉庫,但在小型企業中幾乎聞所未聞。這可能是因為大多數小型公司沒有太多不同的OLTP系統;而且大多數小型公司的數據量都很小-足夠小,可以在常規SQL數據庫中查詢,甚至可以在電子表格中進行分析。在大型公司中,要做一些在小型公司中簡單的事情需要很多繁重的工作。
使用單獨的數據倉庫而不是直接查詢OLTP系統進行分析的一大優勢是,可以針對分析訪問模式對數據倉庫進行優化。 某些數據庫(例如Microsoft SQL Server和SAP HANA)在同一產品中支持事務處理和數據倉庫。 但是,它們越來越成為兩個獨立的存儲和查詢引擎,它們恰巧可以通過公共SQL接口進行訪問。 數據倉庫供應商(例如Teradata,Vertica,SAP HANA和ParAccel)通常在昂貴的商業許可下銷售其系統。 Amazon RedShift是ParAccel的托管版本。 最近,出現了許多開源的SQL-onHadoop項目。 他們很年輕,但旨在與商業數據倉庫系統競爭。 這些包括Apache hive,Spark SQL,Cloudera Impala,Facebook Presto,Apache Tajo和Apache Drill。 其中一些是基于Google Dremel的想法。
Analytics的存儲架構
根據應用程序的需求,在事務處理領域中會使用各種不同的數據模型。 另一方面,在分析中,數據模型的多樣性要少得多。 許多數據倉庫都以相當公式化的方式使用,稱為星型模式(也稱為維建模)。 通常,將事實捕獲為單個事件,因為這樣可以在以后最大程度地進行分析。 但是,這意味著事實表可能會變得非常大。
星星和雪花:
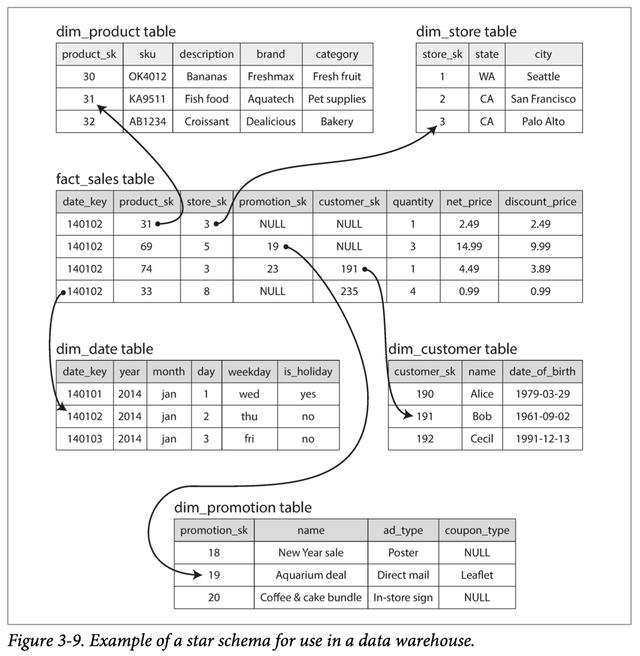
"星型模式"的名稱來自以下事實:當可視化表關系時,事實表位于中間,并被其維度表包圍; 這些桌子的連接就像星星的光芒。 此模板的一種變體稱為雪花模式,其中尺寸進一步細分為多個子維度。 像Apple,Walmart或eBay這樣的大企業,其數據倉庫中可能有數十PB的事務歷史記錄,其中大多數實際上是表。
列式存儲:
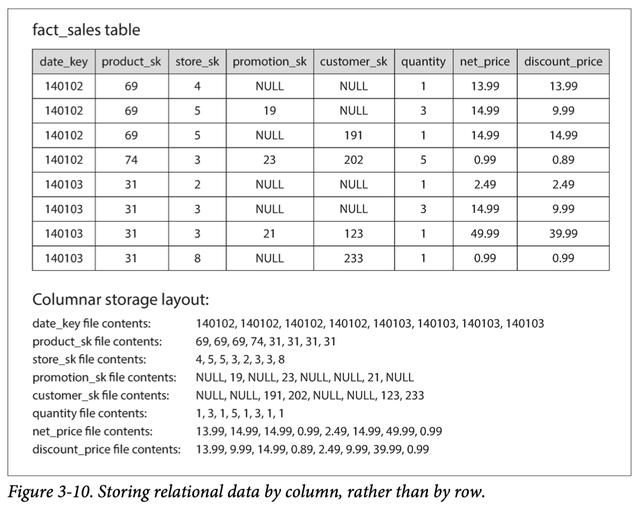
盡管事實表通常超過100列,但是典型的數據倉庫查詢一次只能訪問其中的4或5。 在大多數OLTP數據庫中,存儲以面向行的方式進行布局:表的一行中的所有值都彼此相鄰存儲。 為了處理諸如"查找某項X在12月的平均銷售額"之類的分析查詢,面向行的存儲引擎仍然需要將所有這些行(每個行包含100多個屬性)從磁盤加載到內存中 ,解析它們并過濾掉不符合要求的條件,這可能會花費很長時間。 面向列的存儲背后的想法很簡單:不要將一行中的所有值都存儲在一起,而是將每一列中的所有值存儲在一起。 如果每列存儲在單獨的文件中,則查詢僅需要讀取和解析該查詢中使用的那些列,這可以節省大量工作。
列壓縮:

通常,一列中不同值的數量與行數相比很小(例如,零售商可能進行數十億次銷售交易,但只有100,000種不同產品)。 根據列中的數據,可以使用不同的壓縮技術-在數據倉庫中特別有效的一種技術是位圖編碼。
現在,我們可以將一列包含n個不同的值,并將其轉換為n個單獨的位圖-每個不同的值一個位圖,每行一個位。 如果行具有該值,則該位為1,否則為0。 如果n很小(例如,一個國家/地區列可能具有大約200個不同的值),則這些位圖可以每行一位存儲。
感謝大家的閱讀,以上就是“數據倉庫中的OLTP與OLAP查詢是怎樣的”的全部內容了,學會的朋友趕緊操作起來吧。相信億速云小編一定會給大家帶來更優質的文章。謝謝大家對億速云網站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





