溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么在Kaggle上打比賽”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么在Kaggle上打比賽”吧!
Kaggle是最著名的機器學習競賽網站。Kaggle競賽由一個數據集組成,該數據集可以從網站上獲得,需要使用機器、深度學習或其他數據科學技術來解決問題。一旦你發現了一個解決方案,你就可以把你的模型結果上傳到網站上,然后網站根據你的結果對你進行排名。如果你的結果可以擊敗其他參賽選手,那么你可能獲得現金獎勵。

Kaggle是一個磨練您的機器學習和數據科學技能的好地方,您可以將自己與他人進行比較,并學習新的技術。
Kaggle最新的一項競賽提供了一個數據集,包含推文以及一個告訴我們這些推文是否真的是關于災難的標簽。該比賽的排行榜上有近3000名參賽者,最高獎金為1萬美元。
如果你還沒有Kaggle賬戶,你可以先免費創建一個。
如果你從比賽頁面選擇“下載全部”,你會得到一個包含三個CSV文件的zip文件:
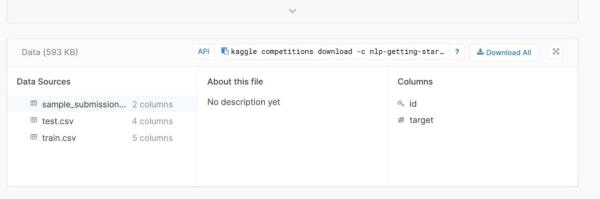
第一個數據文件train.csv包含一組特性及其對應的用于培訓目的的目標標簽。該數據集由以下屬性組成:
Id: tweet的數字標識符。當我們將我們的預測上傳到排行榜時,這將是非常重要的。
關鍵字:推文中的一個關鍵字,可能在某些情況下沒有。
位置:發送推文的位置,這也可能不存在。
文本:推文的全文。
目標:這是我們試圖預測的標簽。如果這條推文真的是關于一場災難,它將是1,如果不是,它將是0。
讓我們并進一步了解這個。在下面的代碼中,您將注意到我使用了一個set_option 命令。這個來自Pandas庫的命令允許您控制dataframe結果顯示的格式。我在這里使用這個命令,以確保顯示文本列的全部內容,這使我的結果和分析更容易查看:
import pandas as pdpd.set_option('display.max_colwidth', -1)train_data = pd.read_csv('train.csv')train_data.head()
第二個數據文件test.csv是測試集,只包含特征,而沒有標簽。對于這個數據集,我們將預測目標標簽并使用結果在排行榜上獲得一個位置。
test_data = pd.read_csv('test.csv')test_data.head()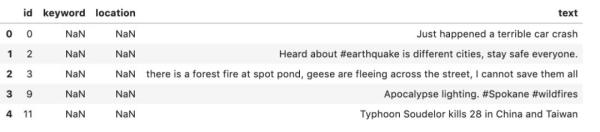
第三個文件sample_submission是示例,展示了提交文件的外觀。這個文件將包含test.csv文件中的id列和我們用模型預測的目標。一旦我們創建了這個文件,我們將提交給網站,并獲得一個位置的排行榜。
sample_submission = pd.read_csv('sample_submission.csv')sample_submission.head()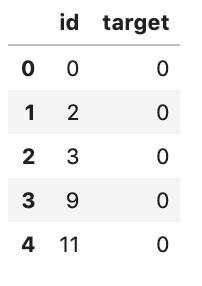
對于任何機器學習任務,在我們可以訓練一個模型之前,我們必須執行一些數據清理和預處理。這在處理文本數據時尤為重要。
為了簡化我們的第一個模型,并且由于這些列中有許多缺失的數據,我們將刪除位置和關鍵字特性,只使用來自tweet的實際文本進行訓練。我們還將刪除id列,因為這對訓練模型沒有用處。
train_data = train_data.drop(['keyword', 'location', 'id'], axis=1)train_data.head()
我們的數據集變成這樣:

文本常常包含許多特殊字符,這些字符對于機器學習算法來說不一定有意義。因此,我要采取的第一步是刪除這些。我也把所有的單詞都小寫了。
import redef clean_text(df, text_field): df[text_field] = df[text_field].str.lower() df[text_field] = df[text_field].apply(lambda elem: re.sub(r"(@[A-Za-z0-9]+)|([^0-9A- Za-z \t])|(\w+:\/\/\S+)|^rt|http.+?", "", elem)) return dfdata_clean = clean_text(train_data, "text")data_clean.head()

另一個有用的文本清理過程是刪除停止字。停止詞是非常常用的詞,通常傳達很少的意思。在英語中,這些詞包括“the”、“it”和“as”。如果我們把這些單詞留在文本中,它們會產生很多噪音,這將使算法更難學習。
NLTK是用于處理文本數據的python庫和工具的集合。除了處理工具之外,NLTK還擁有大量的文本語料庫和詞匯資源,其中包括各種語言中的所有停止詞。我們將使用這個庫從數據集中刪除停止字。
可以通過pip安裝NLTK庫。安裝之后,需要導入庫文集,然后下載stopwords文件:
import nltk.corpusnltk.download('stopwords')一旦這一步完成,你可以閱讀停止詞,并使用它來刪除他們的推文。
from nltk.corpus import stopwordsstop = stopwords.words('english')data_clean['text'] = data_clean['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))data_clean.head()
一旦清理好數據,就需要進一步的預處理,為機器學習算法的使用做好準備。
所有的機器學習算法都使用數學計算來映射特征(在我們的例子中是文本或單詞)和目標變量中的模式。因此,在對機器學習模型進行訓練之前,必須將文本轉換為數字表示,以便進行這些計算。
這種類型的預處理有很多方法,但是在這個例子中,我將使用兩個來自scikit-learn庫的方法。
這個過程的第一步是將數據分割成標記或單個單詞,計算每個單詞在文本中出現的頻率,然后將這些計數表示為一個稀疏矩陣。CountVectoriser函數可以實現這一點。
下一步是對CountVectoriser生成的字數進行加權。應用這種加權的目的是縮小文本中出現頻率非常高的單詞的影響,以便在模型訓練中認為出現頻率較低、可能信息量較大的單詞很重要。TfidTransformer可以執行這個功能。
讓我們把所有這些預處理和模型擬合一起放到scikit-learn流程中,看看模型是如何執行的。對于第一次嘗試,我使用線性支持向量機分類器(SGDClassifier),因為這通常被認為是最好的文本分類算法之一。
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(data_clean['text'],data_clean['target'],random_state = 0)from sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.pipeline import Pipelinefrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfTransformerfrom sklearn.linear_model import SGDClassifierpipeline_sgd = Pipeline([ ('vect', CountVectorizer()), ('tfidf', TfidfTransformer()), ('nb', SGDClassifier()),])model = pipeline_sgd.fit(X_train, y_train)讓我們使用這個訓練好的模型來預測我們的測試數據,并看看這個模型是如何執行的。
from sklearn.metrics import classification_reporty_predict = model.predict(X_test)print(classification_report(y_test, y_predict))
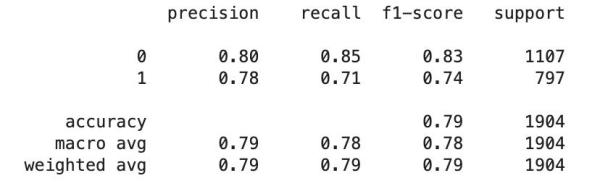
對于第一次嘗試,模型執行得相當好。
現在讓我們看看這個模型在競爭測試數據集上的表現,以及我們在排行榜上的排名。
首先,我們需要清除測試文件中的文本,并使用模型進行預測。下面的代碼獲取測試數據的副本,并執行我們應用于培訓數據的相同清理。輸出如下面的代碼所示。
submission_test_clean = test_data.copy()submission_test_clean = clean_text(submission_test_clean, "text")submission_test_clean['text'] = submission_test_clean['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))submission_test_clean = submission_test_clean['text']submission_test_clean.head()

接下來,我們使用模型創建預測。
submission_test_pred = model.predict(submission_test_clean)
為了創建一個提交,我們需要構造一個dataframe,它只包含來自測試集的id和我們的預測。
id_col = test_data['id']submission_df_1 = pd.DataFrame({ "id": id_col, "target": submission_test_pred})submission_df_1.head()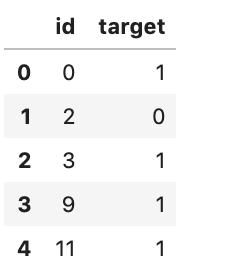
最后,我們將其保存為CSV文件。必須包含index=False,否則索引將被保存為文件中的一列,您的提交將被拒絕。
submission_df_1.to_csv('submission_1.csv', index=False)一旦我們有了CSV文件,我們就可以返回比賽頁面并選擇提交預測按鈕。這將打開一個表單,您可以上傳CSV文件。添加一些關于該方法的注釋是一個好主意,這樣您就有了以前提交嘗試的記錄。
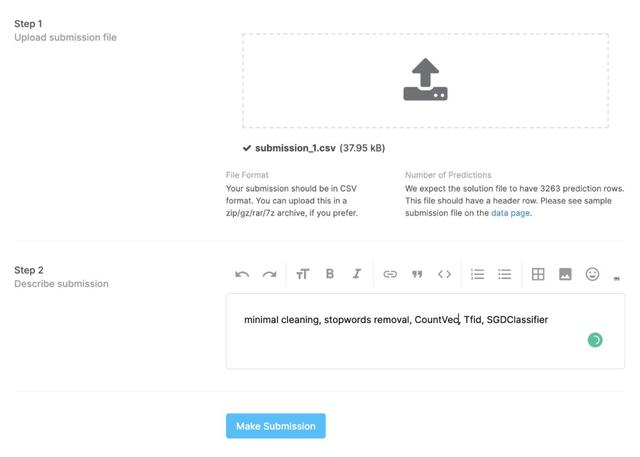
提交文件后,您將看到如下結果:
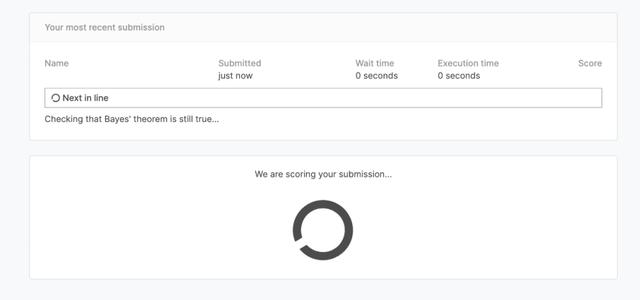
現在我們有一個成功的提交!
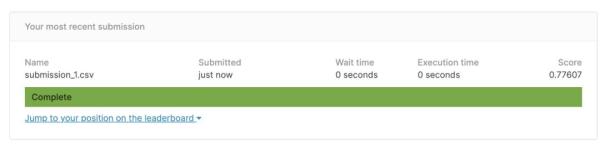
這個模型在排行榜上給了我0.78分,排名2371。顯然還有一些改進的空間,但現在我已經有了一個未來提交的基準。

感謝各位的閱讀,以上就是“怎么在Kaggle上打比賽”的內容了,經過本文的學習后,相信大家對怎么在Kaggle上打比賽這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





