溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Elasticsearch入門知識點總結”,在日常操作中,相信很多人在Elasticsearch入門知識點總結問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Elasticsearch入門知識點總結”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
正文
我先介紹一下目前主流的幾種數據庫存儲方式 :
行存儲:同一行的數據被物理的存儲在一起
常見的行式數據庫系統有:MySQL、Postgres和MS SQL Server。
存儲結構:
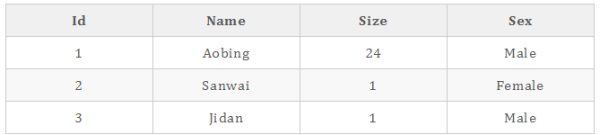
某些場景下行存儲數據庫的查詢效率:

列存儲 :來自不同列的值被單獨存儲,來自同一列的數據被存儲在一起
常見的列式數據庫有:Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+、Hbase、clickhouse。
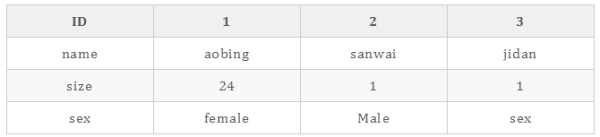
某些場景下列存儲數據庫的查詢效率:
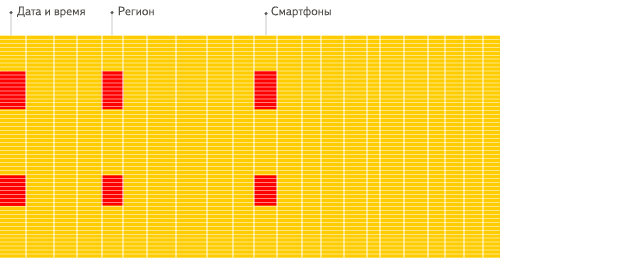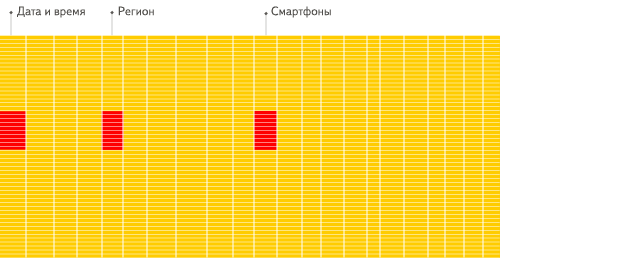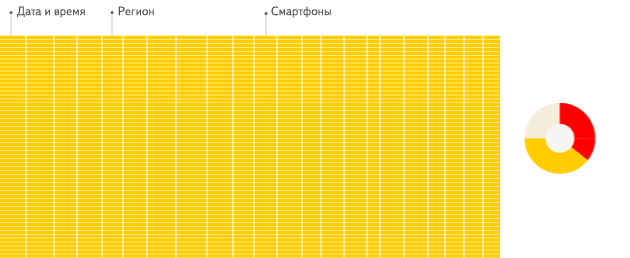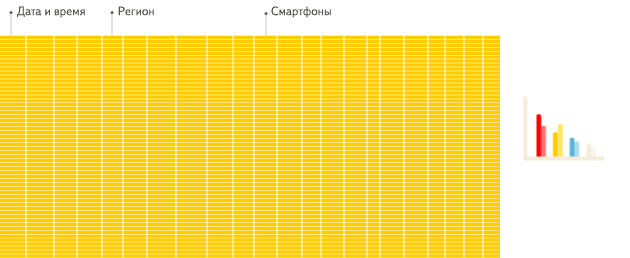
最近我在接觸Clickhouse他就是列式存儲,他之所以這么快,主要是以下三點原因:
輸入/輸出
針對分析類查詢,通常只需要讀取表的一小部分列。在列式數據庫中你可以只讀取你需要的數據。例如,如果只需要讀取100列中的5列,這將幫助你最少減少20倍的I/O消耗。
由于數據總是打包成批量讀取的,所以壓縮是非常容易的。同時數據按列分別存儲這也更容易壓縮。這進一步降低了I/O的體積。
由于I/O的降低,這將幫助更多的數據被系統緩存。
注:這里列出這兩個只是對比一些特殊場景的效率差,也是為后面es的快和數據結構做鋪墊而已,事實上Clickhouse這樣的數據庫也只適合某些場景,大部分場景還得行式數據庫。
大家感興趣我后面可以來點Clickhouse的分享(雖然我也還在看)
接下來就說另外一種存儲結構了:
文檔
實際上 es在某種程度上是和列式文檔有一定的相似之處的,大家往后面看就知道了
{ "name": "name" "size": 24 "sex': "male" }上面我介紹了幾種常見的存儲結構其實是為了說明一下es的場景,以及es的一些優勢,我們都知道數據庫是有索引的,而且也挺快的,那es又是怎么存儲數據,他的索引又是咋樣的呢?
倒排索引
倒排顧名思義就是通過Value去找key,跟我們傳統意義的根據key找value還不太一樣。
舉個例子,還是上面的數據,我們可以看到es會建立以下的索引:
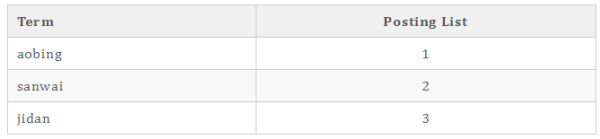
Name 倒排索引
Size倒排索引

Sex倒排索引

大家可以看到所有的倒排所有都有Term和Posting List這兩個概念,Posting list就是一個int的數組,存儲了所有符合某個term的文檔id。
怎么根據value找key呢?就比如我要找所有性別是男生的人,Sex的倒排索引的Posting list可以告訴我是id為1和3的人,那再通過Name的term我可以看到1的是人aobing,3的人是雞蛋,依次類推找到所有信息。
Es的查詢速度是非常快的,但是目前看來如果只是以Term的樣子去查找并不快呀?是為什么呢?
這里就會引出接下來的兩個概念,Term Dictionary和Term Index。
Term Dictionary:這個很好理解,我上面說過都是各種Term組成的,那為了查找Term方便,es把所有的Term都排序了,是二分法查找的。
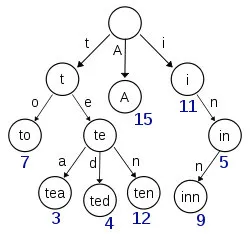
Trem Index:這是為了優化Term Dictionary而存在的,大家想呀這么多Term光是排序了肯定也不行,想要快就得放到內存,但是es數據量級往往是很大的,那放在磁盤?磁盤的尋址又會很慢,那怎么去減少磁盤上的尋址開銷呢?Term Index
其實就是跟新華字典一樣,每個字母開頭的是哪些,再按照拼音去排序。
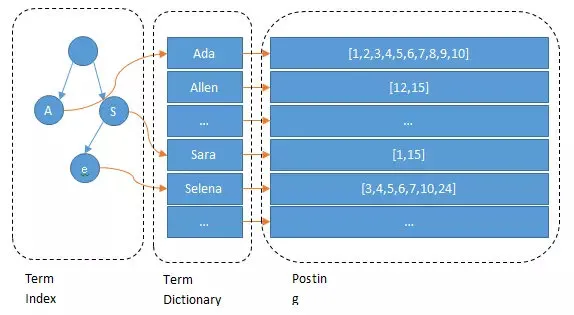
這就是三者的關系,是一張很經典的圖了,基本上所有學es的人都應該看到過。
Term Index就存了一些前綴和映射關系,這樣可以大大減少磁盤的隨機讀次數了。
巧妙壓縮
大家是不是發現這個設計是很巧妙的?而且es的檢索速度比MySQL是快很多的,大家在使用MySQL的時候可以發現其實索引跟Trem Dictionary是一樣的,但是es多了一個Index 多了一層篩選,少了一些隨機次數。
還有一點我很想提一下,就是Term index 在磁盤的存儲結構,這個在我歷史文章有寫過,而且當時我還踩過他的坑,今天鑒于篇幅,我就簡單介紹一下。
FST大家可以理解為一種壓縮技術,最簡單化通過壓縮字節的方式,上面我說了Term index放到內存都放不下,但是壓縮一下呢?
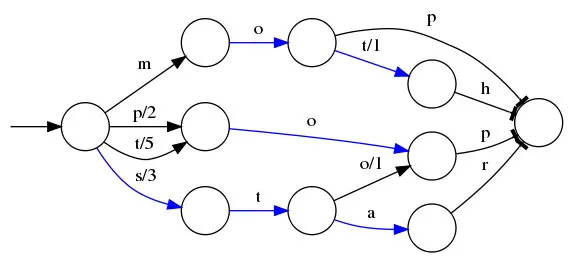
細節我就不展開了,下面這個文章解釋的特別詳細,因為這是一篇大概科普的,后面我會專門出文章介紹集群和他壓縮的細節。

鏈接:https://cs.nyu.edu/~mohri/pub/fla.pdf
接下來再介紹一些es里面我覺得很重要的概念吧:
接近實時(NRT)
ES寫入的數據會先寫到一個內存bufferr中去(在buffer里的時候數據是搜索不到的),然后每隔默認是一秒會刷到os cache。
操作系統里面,磁盤文件其實都有一個東西,叫做os cache,操作系統緩存,就是說數據寫入磁盤文件之前,會先進入os cache,先進入操作系統級別的一個內存緩存中去。
只要buffer中的數據被refresh操作,刷入os cache中,就代表這個數據就可以被搜索到了。默認是每隔1秒refresh一次的,所以es是準實時的,因為寫入的數據1秒之后才能被看到。
為什么要這么設計呢?
簡單我們看一下不這么設計會怎么樣:

如果寫入緩存之后直接刷到硬盤,其實是十分消耗資源的,而且寫了馬上去硬盤讀取,并發量很難上去,你可以想象上萬QPS寫入的時候,還去查詢磁盤,是怎樣一個災難級別的現場。
那es怎么做的呢?

數據寫入到buffer,然后再每秒刷到cache,這個時候就可以被搜到了,所以說準實時,而不是實時就是這一秒的差距,這樣設計可以讓磁盤壓力減少不說,寫入和查詢都不會受到影響,并發也就上去了。
分詞文本分析(Analysis)是把全文本轉換一系列單詞(term/token)的過程,也稱為分詞。
當一個文檔被索引時,每個Term都可能會創建一個倒排索引。倒排索引的過程就是將文檔通過分詞器(Analyzer)分成一個一個的Term,每一個Term都指向包含這個Term的文檔集合。
分詞
是es比較核心的功能,但是他默認的分詞其實對中文并不友好,比如我搜中國,那可能會把帶中和帶國的都搜出來,但是中國就是一個詞匯不應該這樣分。
現在都是可以采用機器學習算法來分詞,還有一些中文分詞插件,比如ik分詞器。
他內置分詞器的在英文場景是比較好用的。
腦裂
腦裂問題其實在集群部署的機器上都是會存在的,假設現在es集群有兩個節點,節點1是主節點對外提供服務,節點2是副本分片節點。
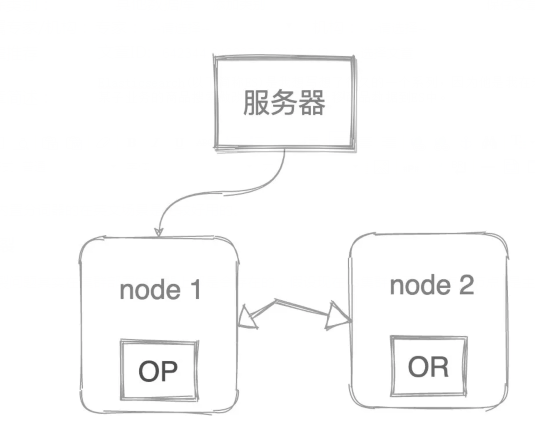
現在兩個節點因為網絡原因斷聯了,會發現什么?主節點發現自己是主節點繼續對外提供服務,副本節點發現沒有主節點了,選舉自己是主節點,也對外提供服務了,因為主節點不可用他也是被迫當主節點的(狗頭)。
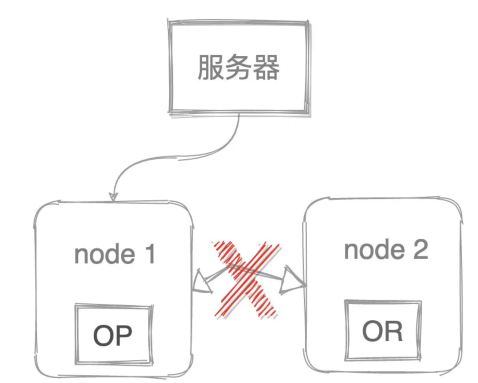
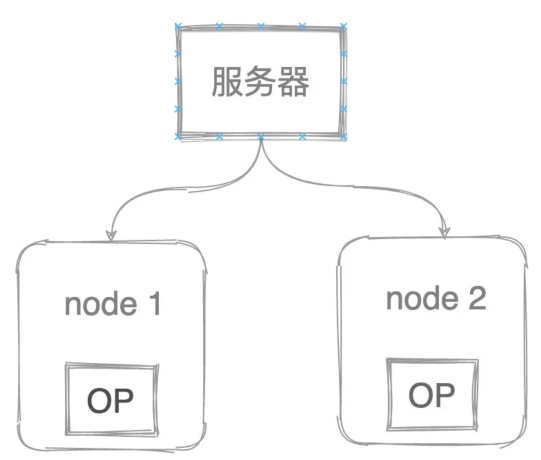
對于調用者來說,這是很難發現差別的,除非去對比數據,而我之前在生產環境就發生過腦裂的情況,還是用戶反饋的,因為搜索一個詞匯他有時候能搜出那個商品,有時候不能,因為請求打在不同的節點上了。
那正常我們會怎么解決呢?elasticsearch.yml中有個配置:discovery.zen.minimum_master_nodes 這個參數決定了在選主過程中需要有多少個節點通信,默認是1,設置的原則就是設置為 集群節點數量/2+1個。
如果你的集群是三個節點,那這個參數就設置為3/2+1=2個,那掛了一個,另外兩個可以通信,所以可以選出一個主的,如果你集群是三個節點,參數還是2,但是你發現掛了一個只有一個節點自己跟自己通信,就不會選主了。
但是這樣也有弊端只有2個節點的時候,掛一個就相當于服務不可用了,所以大家要保證集群是三個以上是最好的。
Elasticsearch的選舉算法基于 Bully 選舉算法,簡單的說,在 Bully 算法中,每個節點都有一個編號,只有編號最大的存活節點才能成為 master 節點。Bully算法的具體過程為:
當任何一個進程P發現 master 不響應請求時,它發起一次選舉,選舉過程如下:
(1)P進程向所有編號比它大的進程發送一個 election 消息;
(2)如果無人響應,則P獲勝,成為 master;
(3)如果編號比它大的進程響應,則由響應者接管選舉工作,P的工作完成。
任何一個時刻,一個進程只能從編號比它小的進程接受 election 消息,當消息到達時,接受者發送一個 OK 消息給發送者,表明它在運行,接管工作。
最終除了一個進程外,其他進程都放棄,那個進程就是新的協調者,隨后協調者將獲勝消息發送給其他所有進程,通知它們新的協調者誕生了。
ELK
其實提到ES往往都是ELK三兄弟一起提到的,最后在收尾的地方,我就說一下另外兩個兄弟吧。
L是Logstash,Logstash是一個開源數據收集引擎,具有實時管道功能。Logstash可以動態地將來自不同數據源的數據統一起來,并將數據標準化到你所選擇的目的地。
Logstash管道有兩個必需的元素:輸入和輸出,以及一個可選元素:過濾器。輸入插件從數據源那里消費數據,過濾器插件根據你的期望修改數據,輸出插件將數據寫入目的地。
K就是Kibana,Kibana是一個針對Elasticsearch的開源分析及可視化平臺,用來搜索、查看交互存儲在Elasticsearch索引中的數據。使用Kibana,可以通過各種圖表進行高級數據分析及展示。
Kibana讓海量數據更容易理解。它操作簡單,基于瀏覽器的用戶界面可以快速創建儀表板(dashboard)實時顯示Elasticsearch查詢動態。
設置Kibana非常簡單,無需編碼或者額外的基礎架構,幾分鐘內就可以完成Kibana安裝并啟動Elasticsearch索引監測。
到此,關于“Elasticsearch入門知識點總結”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





