溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何通過Serverless 輕松識別驗證碼,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
前言
Serverless 概念自被提出就倍受關注,尤其是近些年來 Serverless 煥發出了前所未有的活力,各領域的工程師都在試圖將 Serverless 架構與自身工作相結合,以獲取到 Serverless 架構所帶來的“技術紅利”。
驗證碼(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自動區分計算機和人類的圖靈測試)的縮寫,是一種區分用戶是計算機還是人的公共全自動程序。可以防止惡意破解密碼、刷票、論壇灌水,有效防止某個黑客對某一個特定注冊用戶用特定程序暴力破解方式進行不斷地登陸嘗試。實際上驗證碼是現在很多網站通行的方式,我們利用比較簡易的方式實現了這個功能。CAPTCHA 的問題由計算機生成并評判,但是這個問題只有人類才能解答,計算機是無法解答的,所以回答出問題的用戶就可以被認為是人類。說白了,驗證碼就是用來驗證的碼,驗證是人訪問的還是機器訪問的“碼”。
那么人工智能領域中的驗證碼識別與 Serverless 架構會碰撞出哪些火花呢?本文將通過 Serverless 架構和卷積神經網絡(CNN)算法,實現驗證碼識別功能。
淺談驗證碼
驗證碼的發展,可以說是非常迅速的,從開始的單純數字驗證碼,到后來的數字+字母驗證碼,再到后來的數字+字母+中文的驗證碼以及圖形圖像驗證碼,單純的驗證碼素材已經越來越多了。從驗證碼的形態來看,也是各不相同,輸入、點擊、拖拽以及短信驗證碼、語音驗證碼……
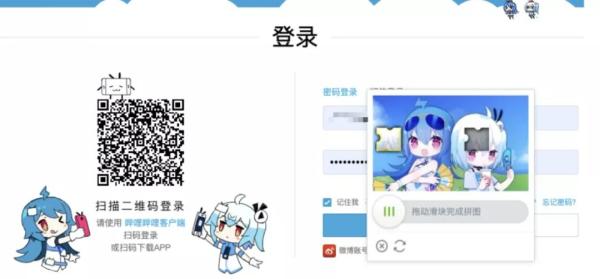
Bilibili 的登錄驗證碼就包括了多種模式,例如滑動滑塊進行驗證:
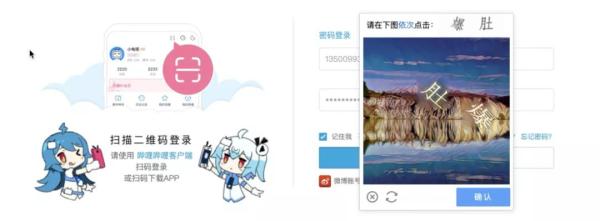
例如,通過依次點擊文字進行驗證:
而百度貼吧、知乎、以及 Google 等相關網站的驗證碼又各不相同,例如選擇正著寫的文字、選擇包括指定物體的圖片以及按順序點擊圖片中的字符等。
驗證碼的識別可能會根據驗證碼的類型而不太一致,當然最簡單的驗證碼可能就是最原始的文字驗證碼了:

即便是文字驗證碼,也是存在很多差異的,例如簡單的數字驗證碼、簡單的數字+字母驗證碼、文字驗證碼、驗證碼中包括計算、簡單驗證碼中增加一些干擾成為復雜驗證碼等。
驗證碼識別
1. 簡單驗證碼識別
驗證碼識別是一個古老的研究領域,簡單說就是把圖片上的文字轉化為文本的過程。最近幾年,隨著大數據的發展,廣大爬蟲工程師在對抗反爬策略時,對驗證碼的識別要求也越來越高。在簡單驗證碼的時代,驗證碼的識別主要是針對文本驗證碼,通過圖像的切割,對驗證碼每一部分進行裁剪,然后再對每個裁剪單元進行相似度對比,獲得最可能的結果,最后進行拼接,例如將驗證碼:

進行二值化等操作:

完成之后再進行切割:

切割完成再進行識別,最后進行拼接,這樣的做法是,針對每個字符進行識別,相對來說是比較容易的。
但是隨著時間的發展,在這種簡單驗證碼逐漸無法滿足判斷“是人還是機器”的問題時,驗證碼進行了一次小升級,即驗證碼上面增加了一些干擾線,或者驗證碼進行了嚴重的扭曲,增加了強色塊干擾,例如 Dynadot 網站的驗證碼:
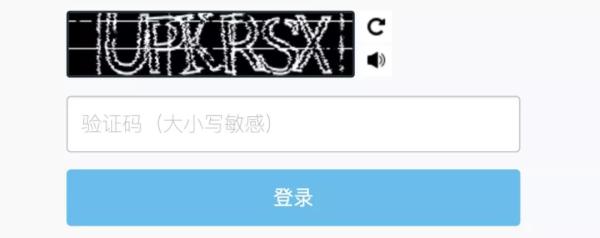
不僅有圖像扭曲重疊,還有干擾線和色塊干擾。這個時候想要識別驗證碼,簡單的切割識別就很難獲得良好的效果了,這時通過深度學習反而可以獲得不錯的效果。
2. 基于 CNN 的驗證碼識別
卷積神經網絡(Convolutional Neural Network,簡稱 CNN),是一種前饋神經網絡,人工神經元可以響應周圍單元,進行大型圖像處理。卷積神經網絡包括卷積層和池化層。

如圖所示,左圖是傳統的神經網絡,其基本結構是:輸入層、隱含層、輸出層。右圖則是卷積神經網絡,其結構由輸入層、輸出層、卷積層、池化層、全連接層構成。卷積神經網絡其實是神經網絡的一種拓展,而事實上從結構上來說,樸素的 CNN 和樸素的 NN 沒有任何區別(當然,引入了特殊結構的、復雜的 CNN 會和 NN 有著比較大的區別)。相對于傳統神經網絡,CNN 在實際效果中讓我們的網絡參數數量大大地減少,這樣我們可以用較少的參數,訓練出更加好的模型,典型的事半功倍,而且可以有效地避免過擬合。同樣,由于 filter 的參數共享,即使圖片進行了一定的平移操作,我們照樣可以識別出特征,這叫做 “平移不變性”。因此,模型就更加穩健了。
1)驗證碼生成
驗證碼的生成是非常重要的一個步驟,因為這一部分的驗證碼將會作為我們的訓練集和測試集,同時最終我們的模型可以識別什么類型的驗證碼,也是和這部分有關。
# coding:utf-8 import random import numpy as np from PIL import Image from captcha.image import ImageCaptcha CAPTCHA_LIST = [eve for eve in "0123456789abcdefghijklmnopqrsruvwxyzABCDEFGHIJKLMOPQRSTUVWXYZ"] CAPTCHA_LEN = 4 # 驗證碼長度 CAPTCHA_HEIGHT = 60 # 驗證碼高度 CAPTCHA_WIDTH = 160 # 驗證碼寬度 randomCaptchaText = lambda char=CAPTCHA_LIST, size=CAPTCHA_LEN: "".join([random.choice(char) for _ in range(size)]) def genCaptchaTextImage(width=CAPTCHA_WIDTH, height=CAPTCHA_HEIGHT, save=None): image = ImageCaptcha(width=width, height=height) captchaText = randomCaptchaText() if save: image.write(captchaText, './img/%s.jpg' % captchaText) return captchaText, np.array(Image.open(image.generate(captchaText))) print(genCaptchaTextImage(save=True))
通過上述代碼,可以生成簡單的中英文驗證碼:
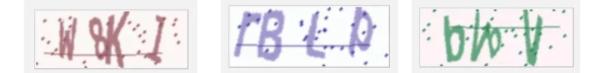
2)模型訓練
模型訓練的代碼如下(部分代碼來自網絡)。
util.py 文件,主要是一些提取出來的公有方法:
# -*- coding:utf-8 -*- import numpy as np from captcha_gen import genCaptchaTextImage from captcha_gen import CAPTCHA_LIST, CAPTCHA_LEN, CAPTCHA_HEIGHT, CAPTCHA_WIDTH # 圖片轉為黑白,3維轉1維 convert2Gray = lambda img: np.mean(img, -1) if len(img.shape) > 2 else img # 驗證碼向量轉為文本 vec2Text = lambda vec, captcha_list=CAPTCHA_LIST: ''.join([captcha_list[int(v)] for v in vec]) def text2Vec(text, captchaLen=CAPTCHA_LEN, captchaList=CAPTCHA_LIST): """ 驗證碼文本轉為向量 """ vector = np.zeros(captchaLen * len(captchaList)) for i in range(len(text)): vector[captchaList.index(text[i]) + i * len(captchaList)] = 1 return vector def getNextBatch(batchCount=60, width=CAPTCHA_WIDTH, height=CAPTCHA_HEIGHT): """ 獲取訓練圖片組 """ batchX = np.zeros([batchCount, width * height]) batchY = np.zeros([batchCount, CAPTCHA_LEN * len(CAPTCHA_LIST)]) for i in range(batchCount): text, image = genCaptchaTextImage() image = convert2Gray(image) # 將圖片數組一維化 同時將文本也對應在兩個二維組的同一行 batchX[i, :] = image.flatten() / 255 batchY[i, :] = text2Vec(text) return batchX, batchY # print(getNextBatch(batch_count=1))
model_train.py 文件,主要是進行模型訓練。在該文件中,定義了模型的基本信息,例如該模型是三層卷積神經網絡,原始圖像大小是 60*160,在第一次卷積后變為 60*160, 第一池化后變為 30*80;第二次卷積后變為 30*80 ,第二次池化后變為 15*40;第三次卷積后變為 15*40 ,第三次池化后變為7*20。經過三次卷積和池化后,原始圖片數據變為 7*20 的平面數據,同時項目在進行訓練的時候,每隔 100 次進行一次數據測試,計算一次準確度:
# -*- coding:utf-8 -*- import tensorflow.compat.v1 as tf from datetime import datetime from util import getNextBatch from captcha_gen import CAPTCHA_HEIGHT, CAPTCHA_WIDTH, CAPTCHA_LEN, CAPTCHA_LIST tf.compat.v1.disable_eager_execution() variable = lambda shape, alpha=0.01: tf.Variable(alpha * tf.random_normal(shape)) conv2d = lambda x, w: tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') maxPool2x2 = lambda x: tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') optimizeGraph = lambda y, y_conv: tf.train.AdamOptimizer(1e-3).minimize( tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=y_conv))) hDrop = lambda image, weight, bias, keepProb: tf.nn.dropout( maxPool2x2(tf.nn.relu(conv2d(image, variable(weight, 0.01)) + variable(bias, 0.1))), keepProb) def cnnGraph(x, keepProb, size, captchaList=CAPTCHA_LIST, captchaLen=CAPTCHA_LEN): """ 三層卷積神經網絡 """ imageHeight, imageWidth = size xImage = tf.reshape(x, shape=[-1, imageHeight, imageWidth, 1]) hDrop1 = hDrop(xImage, [3, 3, 1, 32], [32], keepProb) hDrop2 = hDrop(hDrop1, [3, 3, 32, 64], [64], keepProb) hDrop3 = hDrop(hDrop2, [3, 3, 64, 64], [64], keepProb) # 全連接層 imageHeight = int(hDrop3.shape[1]) imageWidth = int(hDrop3.shape[2]) wFc = variable([imageHeight * imageWidth * 64, 1024], 0.01) # 上一層有64個神經元 全連接層有1024個神經元 bFc = variable([1024], 0.1) hDrop3Re = tf.reshape(hDrop3, [-1, imageHeight * imageWidth * 64]) hFc = tf.nn.relu(tf.matmul(hDrop3Re, wFc) + bFc) hDropFc = tf.nn.dropout(hFc, keepProb) # 輸出層 wOut = variable([1024, len(captchaList) * captchaLen], 0.01) bOut = variable([len(captchaList) * captchaLen], 0.1) yConv = tf.matmul(hDropFc, wOut) + bOut return yConv def accuracyGraph(y, yConv, width=len(CAPTCHA_LIST), height=CAPTCHA_LEN): """ 偏差計算圖,正確值和預測值,計算準確度 """ maxPredictIdx = tf.argmax(tf.reshape(yConv, [-1, height, width]), 2) maxLabelIdx = tf.argmax(tf.reshape(y, [-1, height, width]), 2) correct = tf.equal(maxPredictIdx, maxLabelIdx) # 判斷是否相等 return tf.reduce_mean(tf.cast(correct, tf.float32)) def train(height=CAPTCHA_HEIGHT, width=CAPTCHA_WIDTH, ySize=len(CAPTCHA_LIST) * CAPTCHA_LEN): """ cnn訓練 """ accRate = 0.95 x = tf.placeholder(tf.float32, [None, height * width]) y = tf.placeholder(tf.float32, [None, ySize]) keepProb = tf.placeholder(tf.float32) yConv = cnnGraph(x, keepProb, (height, width)) optimizer = optimizeGraph(y, yConv) accuracy = accuracyGraph(y, yConv) saver = tf.train.Saver() with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 初始化 step = 0 # 步數 while True: batchX, batchY = getNextBatch(64) sess.run(optimizer, feed_dict={x: batchX, y: batchY, keepProb: 0.75}) # 每訓練一百次測試一次 if step % 100 == 0: batchXTest, batchYTest = getNextBatch(100) acc = sess.run(accuracy, feed_dict={x: batchXTest, y: batchYTest, keepProb: 1.0}) print(datetime.now().strftime('%c'), ' step:', step, ' accuracy:', acc) # 準確率滿足要求,保存模型 if acc > accRate: modelPath = "./model/captcha.model" saver.save(sess, modelPath, global_step=step) accRate += 0.01 if accRate > 0.90: break step = step + 1 train()當完成了這部分之后,我們可以通過本地機器對模型進行訓練,為了提升訓練速度,我將代碼中的 accRate 部分設置為:
if accRate > 0.90: break
也就是說,當準確率超過 90% 之后,系統就會自動停止,并且保存模型。
接下來可以進行訓練:

訓練時間可能會比較長,訓練完成之后,可以根據結果繪圖,查看隨著 Step 的增加,準確率的變化曲線:
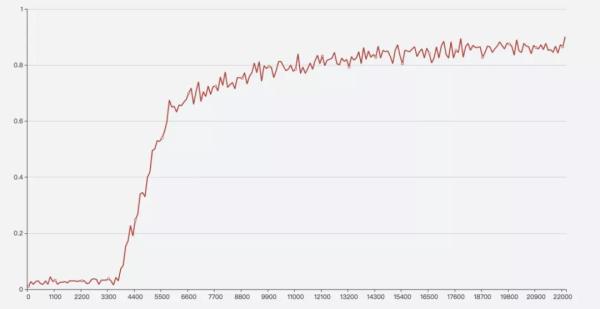
橫軸表示訓練的 Step,縱軸表示準確率
3. 基于 Serverless 架構的驗證碼識別
將上面的代碼部分進行進一步整合,按照函數計算的規范進行編碼:
# -*- coding:utf-8 -*- # 核心后端服務 import base64 import json import uuid import tensorflow as tf import random import numpy as np from PIL import Image from captcha.image import ImageCaptcha # Response class Response: def __init__(self, start_response, response, errorCode=None): self.start = start_response responseBody = { 'Error': {"Code": errorCode, "Message": response}, } if errorCode else { 'Response': response } # 默認增加uuid,便于后期定位 responseBody['ResponseId'] = str(uuid.uuid1()) print("Response: ", json.dumps(responseBody)) self.response = json.dumps(responseBody) def __iter__(self): status = '200' response_headers = [('Content-type', 'application/json; charset=UTF-8')] self.start(status, response_headers) yield self.response.encode("utf-8") CAPTCHA_LIST = [eve for eve in "0123456789abcdefghijklmnopqrsruvwxyzABCDEFGHIJKLMOPQRSTUVWXYZ"] CAPTCHA_LEN = 4 # 驗證碼長度 CAPTCHA_HEIGHT = 60 # 驗證碼高度 CAPTCHA_WIDTH = 160 # 驗證碼寬度 # 隨機字符串 randomStr = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num)) randomCaptchaText = lambda char=CAPTCHA_LIST, size=CAPTCHA_LEN: "".join([random.choice(char) for _ in range(size)]) # 圖片轉為黑白,3維轉1維 convert2Gray = lambda img: np.mean(img, -1) if len(img.shape) > 2 else img # 驗證碼向量轉為文本 vec2Text = lambda vec, captcha_list=CAPTCHA_LIST: ''.join([captcha_list[int(v)] for v in vec]) variable = lambda shape, alpha=0.01: tf.Variable(alpha * tf.random_normal(shape)) conv2d = lambda x, w: tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') maxPool2x2 = lambda x: tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') optimizeGraph = lambda y, y_conv: tf.train.AdamOptimizer(1e-3).minimize( tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=y_conv))) hDrop = lambda image, weight, bias, keepProb: tf.nn.dropout( maxPool2x2(tf.nn.relu(conv2d(image, variable(weight, 0.01)) + variable(bias, 0.1))), keepProb) def genCaptchaTextImage(width=CAPTCHA_WIDTH, height=CAPTCHA_HEIGHT, save=None): image = ImageCaptcha(width=width, height=height) captchaText = randomCaptchaText() if save: image.write(captchaText, save) return captchaText, np.array(Image.open(image.generate(captchaText))) def text2Vec(text, captcha_len=CAPTCHA_LEN, captcha_list=CAPTCHA_LIST): """ 驗證碼文本轉為向量 """ vector = np.zeros(captcha_len * len(captcha_list)) for i in range(len(text)): vector[captcha_list.index(text[i]) + i * len(captcha_list)] = 1 return vector def getNextBatch(batch_count=60, width=CAPTCHA_WIDTH, height=CAPTCHA_HEIGHT): """ 獲取訓練圖片組 """ batch_x = np.zeros([batch_count, width * height]) batch_y = np.zeros([batch_count, CAPTCHA_LEN * len(CAPTCHA_LIST)]) for i in range(batch_count): text, image = genCaptchaTextImage() image = convert2Gray(image) # 將圖片數組一維化 同時將文本也對應在兩個二維組的同一行 batch_x[i, :] = image.flatten() / 255 batch_y[i, :] = text2Vec(text) return batch_x, batch_y def cnnGraph(x, keepProb, size, captchaList=CAPTCHA_LIST, captchaLen=CAPTCHA_LEN): """ 三層卷積神經網絡 """ imageHeight, imageWidth = size xImage = tf.reshape(x, shape=[-1, imageHeight, imageWidth, 1]) hDrop1 = hDrop(xImage, [3, 3, 1, 32], [32], keepProb) hDrop2 = hDrop(hDrop1, [3, 3, 32, 64], [64], keepProb) hDrop3 = hDrop(hDrop2, [3, 3, 64, 64], [64], keepProb) # 全連接層 imageHeight = int(hDrop3.shape[1]) imageWidth = int(hDrop3.shape[2]) wFc = variable([imageHeight * imageWidth * 64, 1024], 0.01) # 上一層有64個神經元 全連接層有1024個神經元 bFc = variable([1024], 0.1) hDrop3Re = tf.reshape(hDrop3, [-1, imageHeight * imageWidth * 64]) hFc = tf.nn.relu(tf.matmul(hDrop3Re, wFc) + bFc) hDropFc = tf.nn.dropout(hFc, keepProb) # 輸出層 wOut = variable([1024, len(captchaList) * captchaLen], 0.01) bOut = variable([len(captchaList) * captchaLen], 0.1) yConv = tf.matmul(hDropFc, wOut) + bOut return yConv def captcha2Text(image_list): """ 驗證碼圖片轉化為文本 """ with tf.Session() as sess: saver.restore(sess, tf.train.latest_checkpoint('model/')) predict = tf.argmax(tf.reshape(yConv, [-1, CAPTCHA_LEN, len(CAPTCHA_LIST)]), 2) vector_list = sess.run(predict, feed_dict={x: image_list, keepProb: 1}) vector_list = vector_list.tolist() text_list = [vec2Text(vector) for vector in vector_list] return text_list x = tf.placeholder(tf.float32, [None, CAPTCHA_HEIGHT * CAPTCHA_WIDTH]) keepProb = tf.placeholder(tf.float32) yConv = cnnGraph(x, keepProb, (CAPTCHA_HEIGHT, CAPTCHA_WIDTH)) saver = tf.train.Saver() def handler(environ, start_response): try: request_body_size = int(environ.get('CONTENT_LENGTH', 0)) except (ValueError): request_body_size = 0 requestBody = json.loads(environ['wsgi.input'].read(request_body_size).decode("utf-8")) imageName = randomStr(10) imagePath = "/tmp/" + imageName print("requestBody: ", requestBody) reqType = requestBody.get("type", None) if reqType == "get_captcha": genCaptchaTextImage(save=imagePath) with open(imagePath, 'rb') as f: data = base64.b64encode(f.read()).decode() return Response(start_response, {'image': data}) if reqType == "get_text": # 圖片獲取 print("Get pucture") imageData = base64.b64decode(requestBody["image"]) with open(imagePath, 'wb') as f: f.write(imageData) # 開始預測 img = Image.open(imageName) img = img.resize((160, 60), Image.ANTIALIAS) img = img.convert("RGB") img = np.asarray(img) image = convert2Gray(img) image = image.flatten() / 255 return Response(start_response, {'result': captcha2Text([image])})在這個函數部分,主要包括兩個接口:
獲取驗證碼:用戶測試使用,生成驗證碼
獲取驗證碼識別結果:用戶識別使用,識別驗證碼
這部分代碼,所需要的依賴內容如下:
tensorflow==1.13.1 numpy==1.19.4 scipy==1.5.4 pillow==8.0.1 captcha==0.3
另外,為了更加簡單的來體驗,提供測試頁面,測試頁面的后臺服務使用 Python Web Bottle 框架:
# -*- coding:utf-8 -*- import os import json from bottle import route, run, static_file, request import urllib.request url = "http://" + os.environ.get("url") @route('/') def index(): return static_file("index.html", root='html/') @route('/get_captcha') def getCaptcha(): data = json.dumps({"type": "get_captcha"}).encode("utf-8") reqAttr = urllib.request.Request(data=data, url=url) return urllib.request.urlopen(reqAttr).read().decode("utf-8") @route('/get_captcha_result', method='POST') def getCaptcha(): data = json.dumps({"type": "get_text", "image": json.loads(request.body.read().decode("utf-8"))["image"]}).encode( "utf-8") reqAttr = urllib.request.Request(data=data, url=url) return urllib.request.urlopen(reqAttr).read().decode("utf-8") run(host='0.0.0.0', debug=False, port=9000)該后端服務,所需依賴:
bottle==0.12.19
前端頁面代碼:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>驗證碼識別測試系統</title> <link href="https://www.bootcss.com/p/layoutit/css/bootstrap-combined.min.css" rel="stylesheet"> <script> var image = undefined function getCaptcha() { const xmlhttp = window.XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject("Microsoft.XMLHTTP"); xmlhttp.open("GET", '/get_captcha', false); xmlhttp.onreadystatechange = function () { if (xmlhttp.readyState == 4 && xmlhttp.status == 200) { image = JSON.parse(xmlhttp.responseText).Response.image document.getElementById("captcha").src = "data:image/png;base64," + image document.getElementById("getResult").style.visibility = 'visible' } } xmlhttp.setRequestHeader("Content-type", "application/json"); xmlhttp.send(); } function getCaptchaResult() { const xmlhttp = window.XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject("Microsoft.XMLHTTP"); xmlhttp.open("POST", '/get_captcha_result', false); xmlhttp.onreadystatechange = function () { if (xmlhttp.readyState == 4 && xmlhttp.status == 200) { document.getElementById("result").innerText = "識別結果:" + JSON.parse(xmlhttp.responseText).Response.result } } xmlhttp.setRequestHeader("Content-type", "application/json"); xmlhttp.send(JSON.stringify({"image": image})); } </script> </head> <body> <div class="container-fluid" style="margin-top: 10px"> <div class="row-fluid"> <div class="span12"> <center> <h4> 驗證碼識別測試系統 </h4> </center> </div> </div> <div class="row-fluid"> <div class="span2"> </div> <div class="span8"> <center> <img src="" id="captcha"/> <br><br> <p id="result"></p> </center> <fieldset> <legend>操作:</legend> <button class="btn" onclick="getCaptcha()">獲取驗證碼</button> <button class="btn" onclick="getCaptchaResult()" id="getResult" style="visibility: hidden">識別驗證碼 </button> </fieldset> </div> <div class="span2"> </div> </div> </div> </body> </html>準備好代碼之后,開始編寫部署文件:
Global: Service: Name: ServerlessBook Description: Serverless圖書案例 Log: Auto Nas: Auto ServerlessBookCaptchaDemo: Component: fc Provider: alibaba Access: release Extends: deploy: - Hook: s install docker Path: ./ Pre: true Properties: Region: cn-beijing Service: ${Global.Service} Function: Name: serverless_captcha Description: 驗證碼識別 CodeUri: Src: ./src/backend Excludes: - src/backend/.fun - src/backend/model Handler: index.handler Environment: - Key: PYTHONUSERBASE Value: /mnt/auto/.fun/python MemorySize: 3072 Runtime: python3 Timeout: 60 Triggers: - Name: ImageAI Type: HTTP Parameters: AuthType: ANONYMOUS Methods: - GET - POST - PUT Domains: - Domain: Auto ServerlessBookCaptchaWebsiteDemo: Component: bottle Provider: alibaba Access: release Extends: deploy: - Hook: pip3 install -r requirements.txt -t ./ Path: ./src/website Pre: true Properties: Region: cn-beijing CodeUri: ./src/website App: index.py Environment: - Key: url Value: ${ServerlessBookCaptchaDemo.Output.Triggers[0].Domains[0]} Detail: Service: ${Global.Service} Function: Name: serverless_captcha_website整體的目錄結構:
| - src # 項目目錄 | | - backend # 項目后端,核心接口 | | - index.py # 后端核心代碼 | | - requirements.txt # 后端核心代碼依賴 | | - website # 項目前端,便于測試使用 | | - html # 項目前端頁面 | | - index.html # 項目前端頁面 | | - index.py # 項目前端的后臺服務(bottle框架) | | - requirements.txt # 項目前端的后臺服務依賴
完成之后,我們可以在項目目錄下,進行項目的部署:
s deploy
部署完成之后,打開返回的頁面地址:

點擊獲取驗證碼,即可在線生成一個驗證碼:

此時點擊識別驗證碼,即可進行驗證碼識別:

由于模型在訓練的時候,填寫的目標準確率是 90%,所以可以認為在海量同類型驗證碼測試之后,整體的準確率在 90% 左右。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





