溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹Python中實現一個LZ77壓縮算法,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
首先介紹幾個專業術語。
1.lookahead buffer(不知道怎么用中文表述,暫時稱為待編碼區):
等待編碼的區域
2. search buffer:
已經編碼的區域,搜索緩沖區
3.滑動窗口:
指定大小的窗,包含“搜索緩沖區”(左) + “待編碼區”(右)
接下來,介紹具體的編碼過程:
為了編碼待編碼區, 編碼器在滑動窗口的搜索緩沖區查找直到找到匹配的字符串。匹配字符串的開始字符串與待編碼緩沖區的距離稱為“偏移值”,匹配字符串的長度稱為“匹配長度”。編碼器在編碼時,會一直在搜索區中搜索,直到找到***匹配字符串,并輸出(o, l ),其中o是偏移值, l是匹配長度。然后窗口滑動l,繼續開始編碼。如果沒有找到匹配字符串,則輸出(0, 0, c),c為待編碼區下一個等待編碼的字符,窗口滑動“1”。算法實現將類似下面的:
while( lookAheadBuffer not empty )
{ get a pointer (position, match) to the longest match in the window for the lookAheadBuffer;output a (position, length, char());
shift the window length+1 characters along;
}主要步驟為:
1.設置編碼位置為輸入流的開始
2.在滑窗的待編碼區查找搜索區中的***匹配字符串
3.如果找到字符串,輸出(偏移值, 匹配長度), 窗口向前滑動“匹配長度”
4.如果沒有找到,輸出(0, 0, 待編碼區的***個字符),窗口向前滑動一個單位
5.如果待編碼區不為空,回到步驟2
描述實在是太復雜,還是結合實例來講解吧
現在有字符串“AABCBBABC”,現在對其進行編碼。
一開始,窗口滑入如圖位置
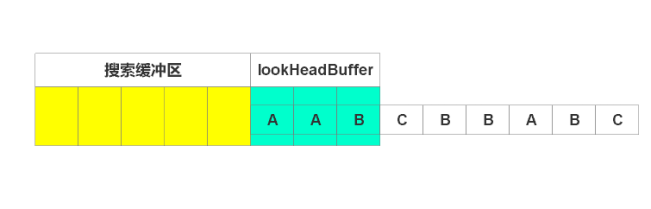
由圖可見,待編碼緩沖區有“AAB”三個字符,此時搜索緩沖區還是空的。所以編碼***個字符,由于搜索區為空,故找不到匹配串,輸出(0,0, A),窗口右移一個單位,如下圖
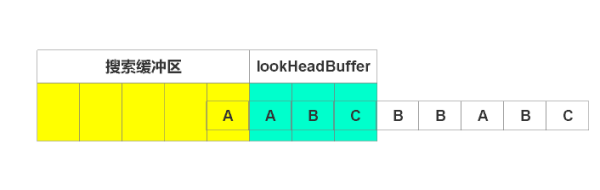
此時待編碼區有“ABC”。開始編碼。***編碼”A”,在搜索區找到”A”。由于沒有超過待編碼區,故開始編碼”AB”,但在搜索區沒有找到匹配字符串,故無法編碼。因此只能編碼”A”。
輸出(1, 1)。即為相對于待編碼區,偏移一個單位,匹配長度為1。窗口右滑動匹配長度,即移動1個單位。如下圖
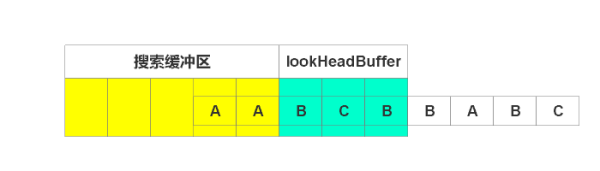
一樣,沒找到,輸出(0, 0, B),右移1個單號,如下圖

輸出(0, 0, C),右移1個單位,如下圖
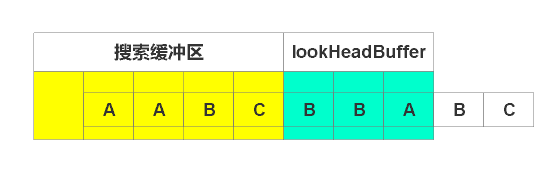
輸出(2, 1),右移1個單位,如下圖
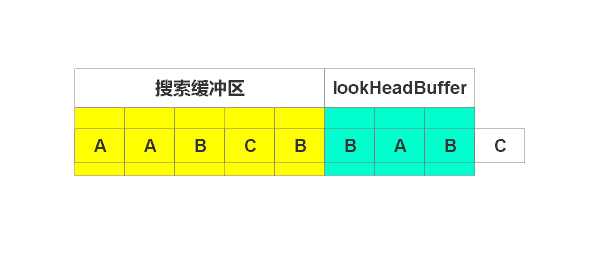
輸出(3, 1), 右移1個單位,如下圖
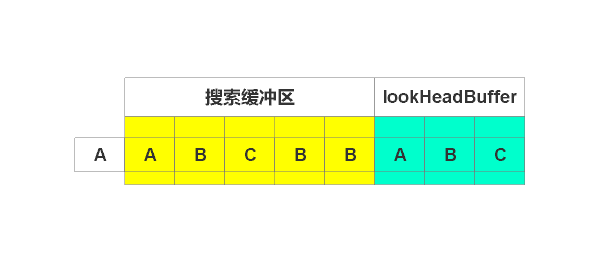
開始編碼”A”,在搜索緩沖區查找到匹配字符串。由于待編碼緩沖區沒有超過,繼續編碼。開始編碼”AB”,也搜索到。不要停止,繼續編碼“ABC”,找到匹配字符串。由于繼續編碼,則超過了窗口,故只編碼“ABC”,輸出(5, 3),偏移5,長度3。右移3個單位,如下圖

此時待編碼緩沖區為空,停止編碼。
最終輸出結果如下

python代碼實現:
class Lz77:def __init__(self, inputStr):self.inputStr = inputStr #輸入流self.searchSize = 5 #搜索緩沖區(已編碼區)大小self.aheadSize = 3 #lookAhead緩沖區(待編碼區)大小 self.windSpiltIndex = 0 #lookHead緩沖區開始的索引self.move = 0self.notFind = -1 #沒有找到匹配字符串#得到滑動窗口的末端索引def getWinEndIndex(self):return self.windSpiltIndex + self.aheadSize#得到滑動窗口的始端索引def getWinStartIndex(self):return self.windSpiltIndex - self.searchSize#判斷lookHead緩沖區是否為空def isLookHeadEmpty(self):return True if self.windSpiltIndex + self.move> len(self.inputStr) - 1 else Falsedef encoding(self):step = 0print("Step Position Match Output")while not self.isLookHeadEmpty():#1.滑動窗口self.winMove()#2. 得到***匹配串的偏移值和長度(offset, matchLen) = self.findMaxMatch()#3.設置窗口下一步需要滑動的距離self.setMoveSteps(matchLen) if matchLen == 0:#匹配為0,說明無字符串匹配,輸出下一個需要編碼的字母nextChar = self.inputStr[self.windSpiltIndex]
result = (step, self.windSpiltIndex, '-', '(0,0)' + nextChar)else:
result = (step, self.windSpiltIndex, self.inputStr[self.windSpiltIndex - offset: self.windSpiltIndex - offset + matchLen], '(' + str(offset) + ',' + str(matchLen) + ')')#4.輸出結果self.output(result)
step = step + 1 #僅用來設置第幾步#滑動窗口(移動分界點)def winMove(self):self.windSpiltIndex = self.windSpiltIndex + self.move#尋找***匹配字符并返回相對于窗口分界點的偏移值和匹配長度def findMaxMatch(self):matchLen = 0offset = 0minEdge = self.minEdge() + 1 #得到編碼區域的右邊界#遍歷待編碼區,尋找***匹配串for i in range(self.windSpiltIndex + 1, minEdge):#print("i: %d" %i)offsetTemp = self.searchBufferOffest(i)if offsetTemp == self.notFind: return (offset, matchLen)
offset = offsetTemp #偏移值matchLen = matchLen + 1 #每找到一個匹配串,加1return (offset, matchLen)#入參字符串是否存在于搜索緩沖區,如果存在,返回匹配字符串的起始索引def searchBufferOffest(self, i):searchStart = self.getWinStartIndex()
searchEnd = self.windSpiltIndex #下面幾個if是處理開始時的特殊情況if searchEnd < 1:return self.notFindif searchStart < 0:
searchStart = 0if searchEnd == 0:
searchEnd = 1searchStr = self.inputStr[searchStart : searchEnd] #搜索區字符串findIndex = searchStr.find(self.inputStr[self.windSpiltIndex : i])if findIndex == -1:return -1return len(searchStr) - findIndex#設置下一次窗口需要滑動的步數def setMoveSteps(self, matchLen):if matchLen == 0:
self.move = 1else:
self.move = matchLendef minEdge(self):return len(self.inputStr) if len(self.inputStr) - 1 < self.getWinEndIndex() else self.getWinEndIndex() + 1def output(self, touple):print("%d %d %s %s" % touple)if __name__ == "__main__":
lz77 = Lz77("AABCBBABC")
lz77.encoding()關于Python中實現一個LZ77壓縮算法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





