溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“java網絡爬蟲的基礎知識有哪些”,在日常操作中,相信很多人在java網絡爬蟲的基礎知識有哪些問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”java網絡爬蟲的基礎知識有哪些”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
我為什么會把這一點放在最前面呢?因為我覺得這一點比較重要,什么叫有 “道德” 的爬蟲呢?就是遵循被爬服務器的規則,不去影響被爬服務器的正常運行,不把被爬服務搞垮,這就是有 “道德” 的爬蟲。
經常有人討論的一個問題就是爬蟲合法嗎?知乎一下你看到的將是這樣的
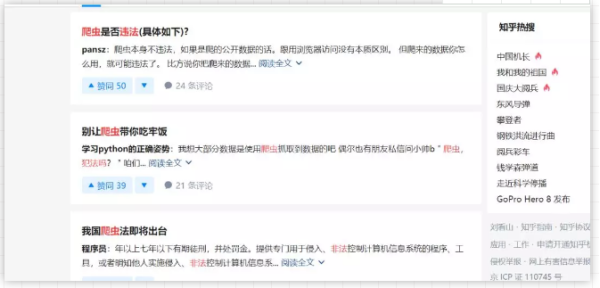
答案千千萬,在這眾多答案中,我個人比較贊同下面的這個回答
爬蟲作為一種計算機技術就決定了它的中立性,因此爬蟲本身在法律上并不被禁止,但是利用爬蟲技術獲取數據這一行為是具有違法甚至是犯罪的風險的。所謂具體問題具體分析,正如水果刀本身在法律上并不被禁止使用,但是用來捅人,就不被法律所容忍了。
爬蟲違不違法?取決于你做的事情違不違法,網絡爬蟲的本質是什么?網絡爬蟲的本質是用機器代替人工去訪問頁面。我查看公開的新聞肯定不犯法,所以我去采集公開在互聯網上的新聞也不犯法,就像各大搜索引擎網站一樣,別的網站巴不得別搜索引擎的蜘蛛抓取到。另一種恰恰相反的情況是去采集別人隱私的數據,你自己去查看別人的隱私信息這就是一種違法的行為,所以用程序去采集也是違法的,這就像答案中所說的水果刀本身不違法,但是用來捅人就違法啦。
要做到有 “道德” 的爬蟲,Robots 協議是你必須需要了解的,下面是 Robots 協議的百度百科

在很多網站中會申明 Robots 協議告訴你哪些頁面是可以抓取的,哪些頁面是不能抓取的,當然 Robots 協議只是一種約定,就像公交車上的座位一樣標明著老弱病殘專座,你去坐了也不違法。
除了協議之外,我們在采集行為上也需要克制,在 『數據安全管理辦法(征求意見稿)』的第二章第十六條指出:
網絡運營者采取自動化手段訪問收集網站數據,不得妨礙網站正常運行;此類行為嚴重影響網站運行,如自動化訪問收集流量超過網站日均流量三分之一,網站要求停止自動化訪問收集時,應當停止。
這條規定指出了爬蟲程序不得妨礙網站正常運行,如果你使用爬蟲程序把網站搞垮了,真正的訪問者就不能訪問該網站了,這是一種非常不道德的行為。應該杜絕這種行為。
除了數據的采集,在數據的使用上同樣需要注意,我們即使在得到授權的情況下采集了個人信息數據,也千萬不要去出賣個人數據,這個是法律特別指出禁止的,參見:
根據《最高人民法院 最高人民檢察院關于辦理侵犯公民個人信息刑事案件適用法律若干問題的解釋》第五條規定,對“情節嚴重”的解釋:
(1)非法獲取、出售或者提供行蹤軌跡信息、通信內容、征信信息、財產信息五十條以上的;
(2)非法獲取、出售或者提供住宿信息、通信記錄、健康生理信息、交易信息等其他可能影響人身、財產安全的公民個人信息五百條以上的;
(3)非法獲取、出售或者提供第三項、第四項規定以外的公民個人信息五千條以上的便構成“侵犯公民個人信息罪”所要求的“情節嚴重”。
此外,未經被收集者同意,即使是將合法收集的公民個人信息向他人提供的,也屬于刑法第二百五十三條之一規定的“提供公民個人信息”,可能構成犯罪。
我們每一次與服務端的交互都是通過 Http 協議,當然也有不是 Http 協議的,這個能不能采集我就不知道啦,沒有采集過,所以我們只談論 Http 協議,在 Web 網頁中分析 Http 協議還是比較簡單,我們以百度檢索一條新聞為例
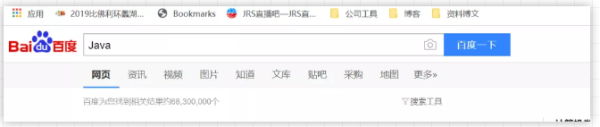
我們打開 F12 調試工具,點擊 NetWork 查看版能查看到所有的請求,找到我們地址欄中的鏈接,主鏈接一般存在 NetWork 最上面一條鏈接
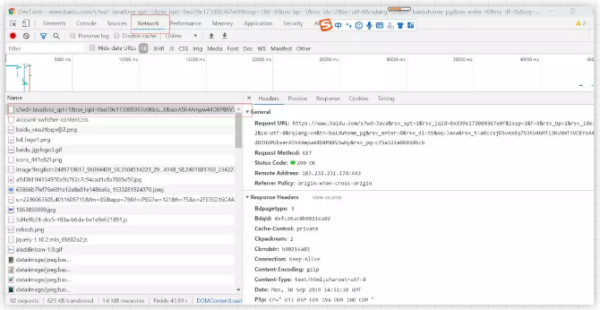
在右邊headers查看欄中,我們能夠看到這次請求所需要的參數,在這里我們需要特別注意 Request Headers 和 Query String Parameters 這兩個選項欄。
Request Headers 表示的是該次 Http 請求所需要的請求頭的參數,有一些網站會根據請求頭來屏蔽爬蟲,所以里面的參數還是需要了解一下的,請求頭參數中大部分參數都是公用的, User-Agent 和 Cookie 這兩個參數使用比較頻繁, User-Agent 標識瀏覽器請求頭,Cookie 存放的是用戶登錄憑證。
Query String Parameters 表示該次 Http 請求的請求參數,對于post 請求來說這個還是非常重要的,因為在這里可以查看到請求參數,對我們模擬登陸等 Post 請求非常有用。
上面是網頁版的 HTTP 請求的鏈接分析,如果需要采集 APP 里面的數據就需要借助模擬器了,因為 APP 里沒有調試工具,所以只能借助模擬器,使用較多的模擬器工具有如下兩種,有興趣的可以執行研究。
fiddler
wireshark
我們采集的頁面都是 HTML 頁面,我們需要在 HTML 頁面中獲取我們需要的信息,這里面就涉及到了 HTML 頁面解析,也就是 DOM 節點解析,這一點是重中之重,如果你不會這一點就像魔術師沒有道具一樣,只能干瞪眼啦。例如下面這個 HTML 頁面
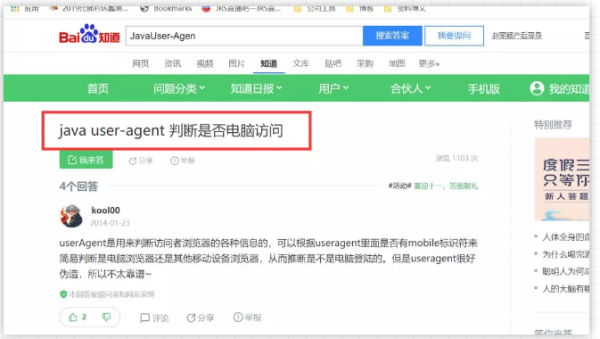
我們需要獲取標題 “java user-agent 判斷是否電腦訪問” ,我們先通過 F12 檢查元素
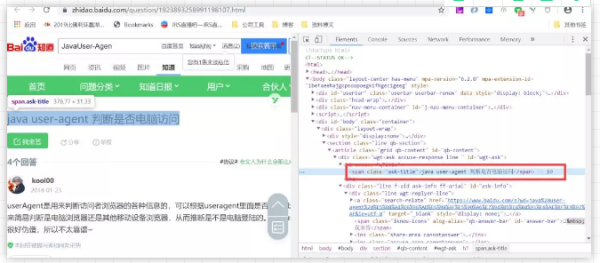
標題所在的 span 標簽我已經在圖中框出來啦,我們該如何解析這個節點信息呢?方法有千千萬萬,經常使用的選擇器應該是 CSS 選擇器 和 XPath :
使用 CSS 選擇器解析的寫法為:#wgt-ask > h2 > span
使用 XPath 解析的寫法為://span[@class="wgt-ask"]
這樣就獲取到了 span 的節點,值需要取出 text 就好了,對于 CSS 選擇器 和 XPath 除了自己編寫之外,我們還可以借助瀏覽器來幫我們完成,例如 chrome 瀏覽器
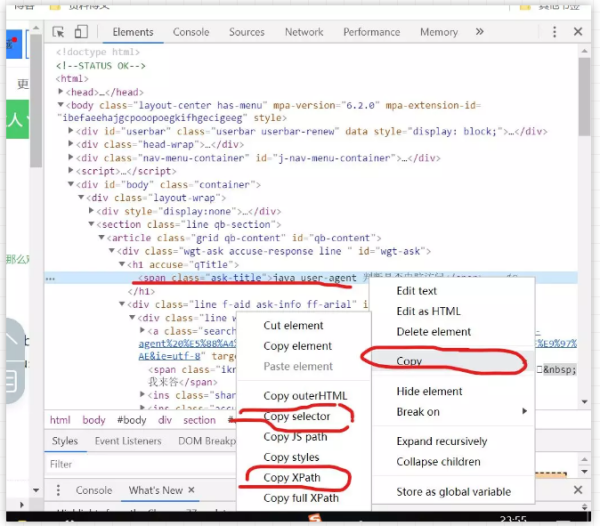
只需要選中對應的節點,右鍵找到 Copy ,它提供了幾種獲取該節點的解析方式,具體的如上圖所示,Copy selector 對應的就是 Css 選擇器,Copy XPath 對應的是 XPath,這個功能還是非常有用的。
因為現在爬蟲非常泛濫,很多網站都會有反爬蟲機制,來過濾掉爬蟲程序,以便保證網站的可以用,這也是非常有必要的手段,畢竟如果網站不能使用了,就沒有利益可談啦。反爬蟲的手段非常多,我們來看看幾種常見的反爬蟲手段。
基于 Headers 的反爬蟲機制
這是一種比較常見的反爬蟲機制,網站通過檢查 Request Headers 中的 User-Agent 、Referer 參數,來判斷該程序是不是爬蟲程序。要繞過這種機制就比較簡單,我們只需要在網頁中先查看該網站所需要的 User-Agent 、Referer 參數的值,然后在爬蟲程序的 Request Headers 設置好這些參數就好啦。
基于用戶行為的反爬蟲機制
這也是一種常見的反爬蟲機制,最常用的就是 IP 訪問限制,一個 IP 在一段時間內只被允許訪問多少次,如果超過這個頻次的話就會被認為是爬蟲程序,比如豆瓣電影就會通過 IP 限制。
對于這種機制的話,我們可以通過設置代理 IP 來解決這個問題,我們只需要從代理ip網站上獲取一批代理ip,在請求的時候通過設置代理 IP 即可。
除了 IP 限制之外,還會有基于你每次的訪問時間間隔,如果你每次訪問的時間間隔都是固定的,也可能會被認為是爬蟲程序。要繞過這個限制就是在請求的時候,時間間隔設置不一樣,比例這次休眠 1 分鐘,下次 30 秒。
基于動態頁面的反爬蟲機制
有很多網站,我們需要采集的數據是通過 Ajax 請求的或者通過 JavaScript生成的,對于這種網站是比較麻煩的,繞過這種機制,我們有兩種辦法,一種是借助輔助工具,例如 Selenium 等工具獲取渲染完成的頁面。第二種方式就是反向思維法,我們通過獲取到請求數據的 AJAX 鏈接,直接訪問該鏈接獲取數據。
以上就是爬蟲的一些基本知識,主要介紹了網絡爬蟲的使用工具和反爬蟲策略,這些東西在后續對我們的爬蟲學習會有所幫助,由于這幾年斷斷續續的寫過幾個爬蟲項目,使用 Java 爬蟲也是在前期,后期都是用 Python,最近突然間對 Java 爬蟲又感興趣了,所以準備寫一個爬蟲系列博文,重新梳理一下 Java 網絡爬蟲,算是對 Java 爬蟲的一個總結,如果能幫助到想利用 Java 做網絡爬蟲的小伙伴,那就更棒啦。Java 網絡爬蟲預計會有六篇文章的篇幅,從簡單到復雜,一步一步深入,內容涉及到了我這些年爬蟲所遇到的所有問題。下面是模擬的六篇文章介紹。
1、網絡爬蟲,原來這么簡單
這一篇是網絡爬蟲的入門,會使用 Jsoup 和 HttpClient 兩種方式獲取到頁面,然后利用選擇器解析得到數據。最后你會收獲到爬蟲就是一條 http 請求,就是這么簡單。
2、網頁采集遇到登錄問題,我該怎么辦?
這一章節簡單的聊一聊獲取需要登錄的數據,以獲取豆瓣個人信息為例,從手動設置 cookies 和模擬登陸這兩種方式簡單的聊一聊這類問題。
3、網頁采集遇到數據 Ajax 異步加載,我該怎么辦?
這一章節簡單的聊一聊異步數據的問題,以網易新聞為例,從利用 htmlunit 工具獲取渲染完頁面和反向思維直接獲取到 Ajax 請求連接獲取數據兩種方式,簡單的聊一下這類問題的處理方式。
4、網頁采集 IP 被封,我該怎么辦?
IP 訪問被限制這應該是常見的事情,以豆瓣電影為例,主要以設置代理IP為中心,簡單的聊一聊 IP 被限制的解決辦法,還會簡單的聊一下如何搭建自己的ip代理服務。
5、網絡采集性能太差,我該怎么辦?
有時候對爬蟲程序的性能有要求,這種單線程的方式可能就行不通了,我們可能就需要多線程甚至是分布式的爬蟲程序啦,所以這一篇主要聊一聊多線程爬蟲以及分布式爬蟲架構方案。
6、開源爬蟲框架 webmagic 使用案例解析
以前用 webmagic 做過一次爬蟲,但是那個時候我似懂非懂的,沒有很好的理解 webmagic 框架,經過這幾年的經歷,我現在對這個框架有了全新的認識,所以想按照 webmagic 的規范搭建一個簡單的 demo來體驗 webmagic 的強大之處。
到此,關于“java網絡爬蟲的基礎知識有哪些”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





