溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Java網絡爬蟲的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
需要提取的內容如下圖所示:
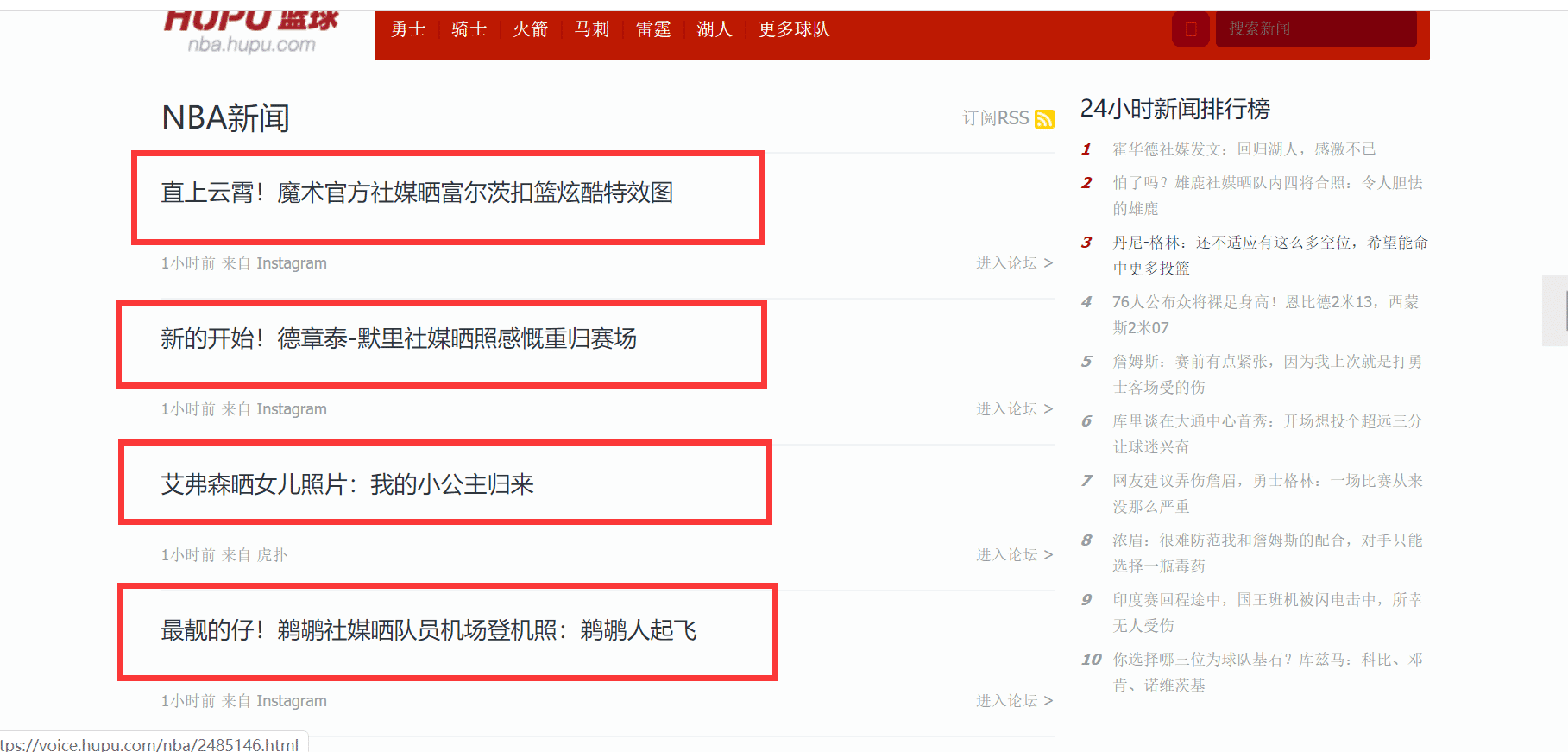
我們需要提取圖中圈出來的文字及其對應的鏈接,在提取的過程中,我們會使用兩種方式來提取,一種是 Jsoup 的方式,另一種是 httpclient + 正則表達式的方式,這也是 Java 網絡爬蟲常用的兩種方式,你不了解這兩種方式沒關系,后面會有相應的使用手冊。在正式編寫提取程序之前,我先交代一下 Java 爬蟲系列博文的環境,該系列博文所有的 demo 都是使用 SpringBoot 搭建的,不管你使用哪種環境,只需要正確的導入相應的包即可。
Jsoup 方式提取信息
我們先來使用 Jsoup 的方式提取新聞信息,如果你還不知道 Jsoup ,請參考 https://jsoup.org/
先建立一個 Springboot 項目,名字就隨意啦,在 pom.xml 中引入 Jsoup 的依賴
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.12.1</version> </dependency>
好了,接下來我們一起分析頁面吧,想必你還沒瀏覽過吧,點擊這里瀏覽虎撲新聞。在列表頁中,我們利用 F12 審查元素查看頁面結構,經過我們分析發現列表新聞在 <div class="news-list">標簽下,每一條新聞都是一個li標簽,分析結果如下圖所示:
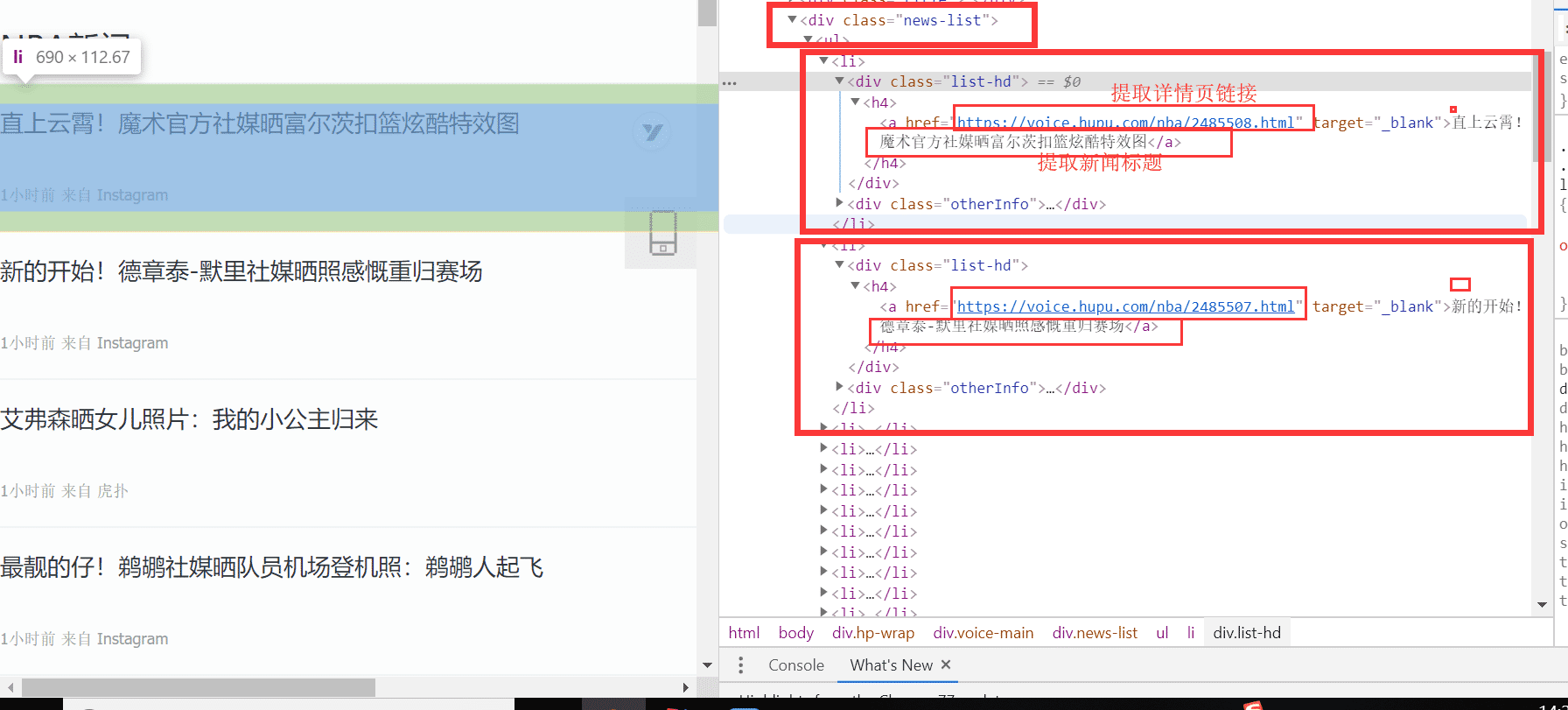
由于我們前面已經知道了 css 選擇器,我們結合瀏覽器的 Copy 功能,編寫出我們 a標簽的 css 選擇器代碼:div.news-list > ul > li > div.list-hd > h5 > a ,一切都準備好了,我們一起來編寫 Jsoup 方式提取信息的代碼:
/**
* jsoup方式 獲取虎撲新聞列表頁
* @param url 虎撲新聞列表頁url
*/
public void jsoupList(String url){
try {
Document document = Jsoup.connect(url).get();
// 使用 css選擇器 提取列表新聞 a 標簽
// <a href="https://voice.hupu.com/nba/2484553.html" rel="external nofollow" target="_blank">霍華德:夏休期內曾節食30天,這考驗了我的身心</a>
Elements elements = document.select("div.news-list > ul > li > div.list-hd > h5 > a");
for (Element element:elements){
// System.out.println(element);
// 獲取詳情頁鏈接
String d_url = element.attr("href");
// 獲取標題
String title = element.ownText();
System.out.println("詳情頁鏈接:"+d_url+" ,詳情頁標題:"+title);
}
} catch (IOException e) {
e.printStackTrace();
}
}使用 Jsoup 方式提取還是非常簡單的,就5、6行代碼就完成了,關于更多 Jsoup 如何提取節點信息的方法可以參考 jsoup 的官網教程。我們編寫 main 方法,來執行 jsoupList 方法,看看 jsoupList 方法是否正確。
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
crawlerBase.jsoupList(url);
}執行 main 方法,得到如下結果:
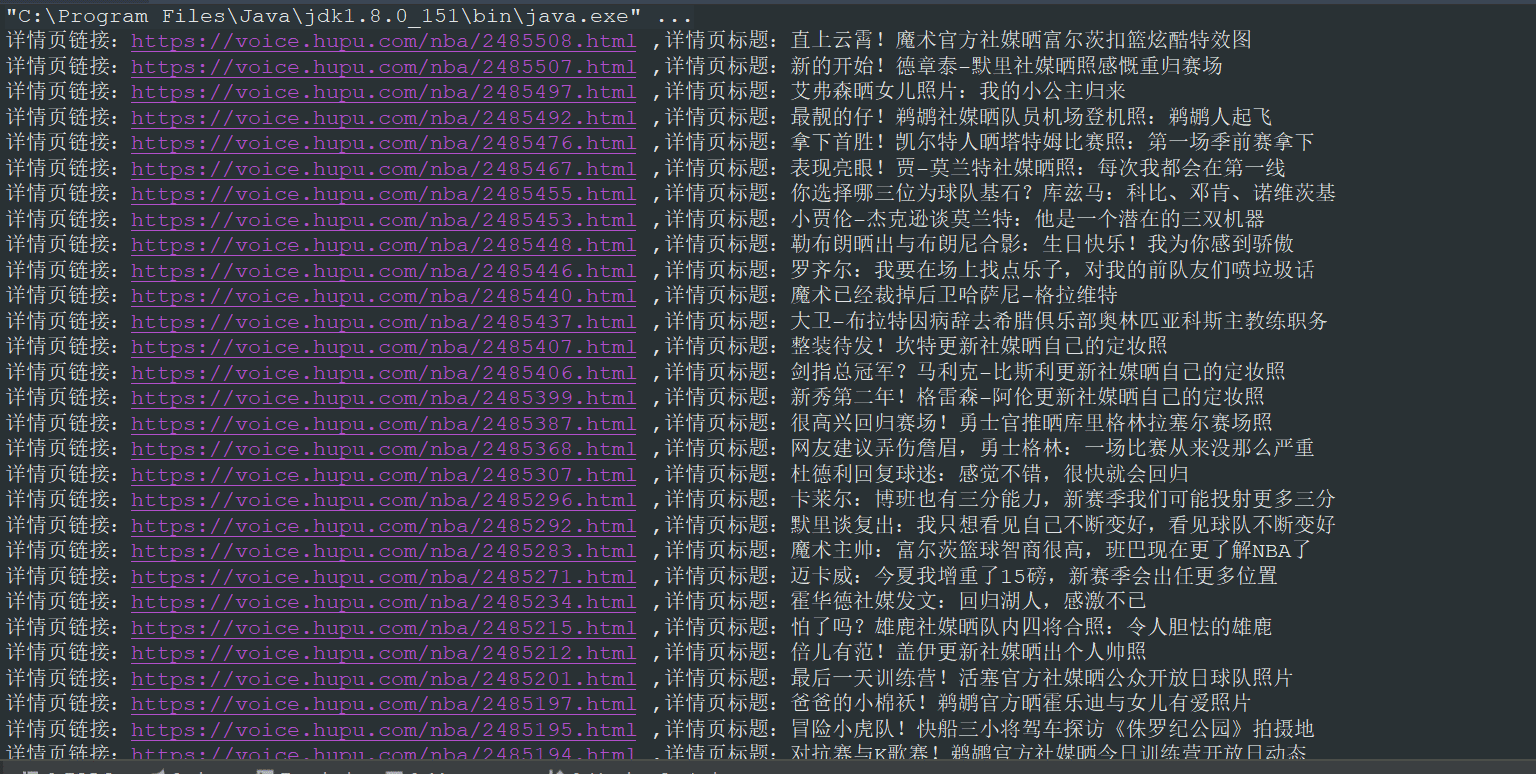
從結果中可以看出,我們已經正確的提取到了我們想要的信息,如果你想采集詳情頁的信息,只需要編寫一個采集詳情頁的方法,在方法中提取詳情頁相應的節點信息,然后將列表頁提取的鏈接傳入提取詳情頁方法即可。
httpclient + 正則表達式
上面我們使用了 Jsoup 方式正確提取了虎撲列表新聞,接下來我們使用 httpclient + 正則表達式的方式來提取,看看使用這種方式又會涉及到哪些問題?httpclient + 正則表達式的方式涉及的知識點還是蠻多的,它涉及到了正則表達式、Java 正則表達式、httpclient。如果你還不知道這些知識,可以點擊下方鏈接簡單了解一下:
正則表達式:正則表達式
Java 正則表達式:Java 正則表達式
httpclient:httpclient
我們在 pom.xml 文件中,引入 httpclient 相關 Jar 包
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.10</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpcore</artifactId> <version>4.4.10</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpmime</artifactId> <version>4.5.10</version> </dependency>
關于虎撲列表新聞頁面,我們在使用 Jsoup 方式的時候進行了簡單的分析,這里我們就不在重復分析了。對于使用正則表達式方式提取,我們需要找到能夠代表列表新聞的結構體,比如: <div class="list-hd"> <h5> <a href="https://voice.hupu.com/nba/2485508.html" rel="external nofollow" target="_blank">直上云霄!魔術官方社媒曬富爾茨扣籃炫酷特效圖</a></h5></div>
這段結構體,每個列表新聞只有鏈接和標題不一樣,其他的都一樣,而且 <div class="list-hd">是列表新聞特有的。最好不要直接正則匹配 a標簽,因為 a標簽在其他地方也有,這樣我們就還需要做其他的處理,增加我們的難度。現在我們了解了正則結構體的選擇,我們一起來看看 httpclient + 正則表達式方式提取的代碼:
/**
* httpclient + 正則表達式 獲取虎撲新聞列表頁
* @param url 虎撲新聞列表頁url
*/
public void httpClientList(String url){
try {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity,"utf-8");
if (body!=null) {
/*
* 替換掉換行符、制表符、回車符,去掉這些符號,正則表示寫起來更簡單一些
* 只有空格符號和其他正常字體
*/
Pattern p = Pattern.compile("\t|\r|\n");
Matcher m = p.matcher(body);
body = m.replaceAll("");
/*
* 提取列表頁的正則表達式
* 去除換行符之后的 li
* <div class="list-hd"> <h5> <a href="https://voice.hupu.com/nba/2485167.html" rel="external nofollow" target="_blank">與球迷親切互動!凱爾特人官方曬球隊開放訓練日照片</a> </h5> </div>
*/
Pattern pattern = Pattern
.compile("<div class=\"list-hd\">\\s* <h5>\\s* <a href=\"(.*?)\"\\s* target=\"_blank\">(.*?)</a>\\s* </h5>\\s* </div>" );
Matcher matcher = pattern.matcher(body);
// 匹配出所有符合正則表達式的數據
while (matcher.find()){
// String info = matcher.group(0);
// System.out.println(info);
// 提取出鏈接和標題
System.out.println("詳情頁鏈接:"+matcher.group(1)+" ,詳情頁標題:"+matcher.group(2));
}
}else {
System.out.println("處理失敗!!!獲取正文內容為空");
}
} else {
System.out.println("處理失敗!!!返回狀態碼:" + response.getStatusLine().getStatusCode());
}
}catch (Exception e){
e.printStackTrace();
}
}從代碼的行數可以看出,比 Jsoup 方式要多不少,代碼雖然多,但是整體來說比較簡單,在上面方法中我做了一段特殊處理,我先替換了 httpclient 獲取的字符串 body 中的換行符、制表符、回車符,因為這樣處理,在編寫正則表達式的時候能夠減少一些額外的干擾。接下來我們修改 main 方法,運行 httpClientList 方法。
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
// crawlerBase.jsoupList(url);
crawlerBase.httpClientList(url);
}運行結果如下圖所示:
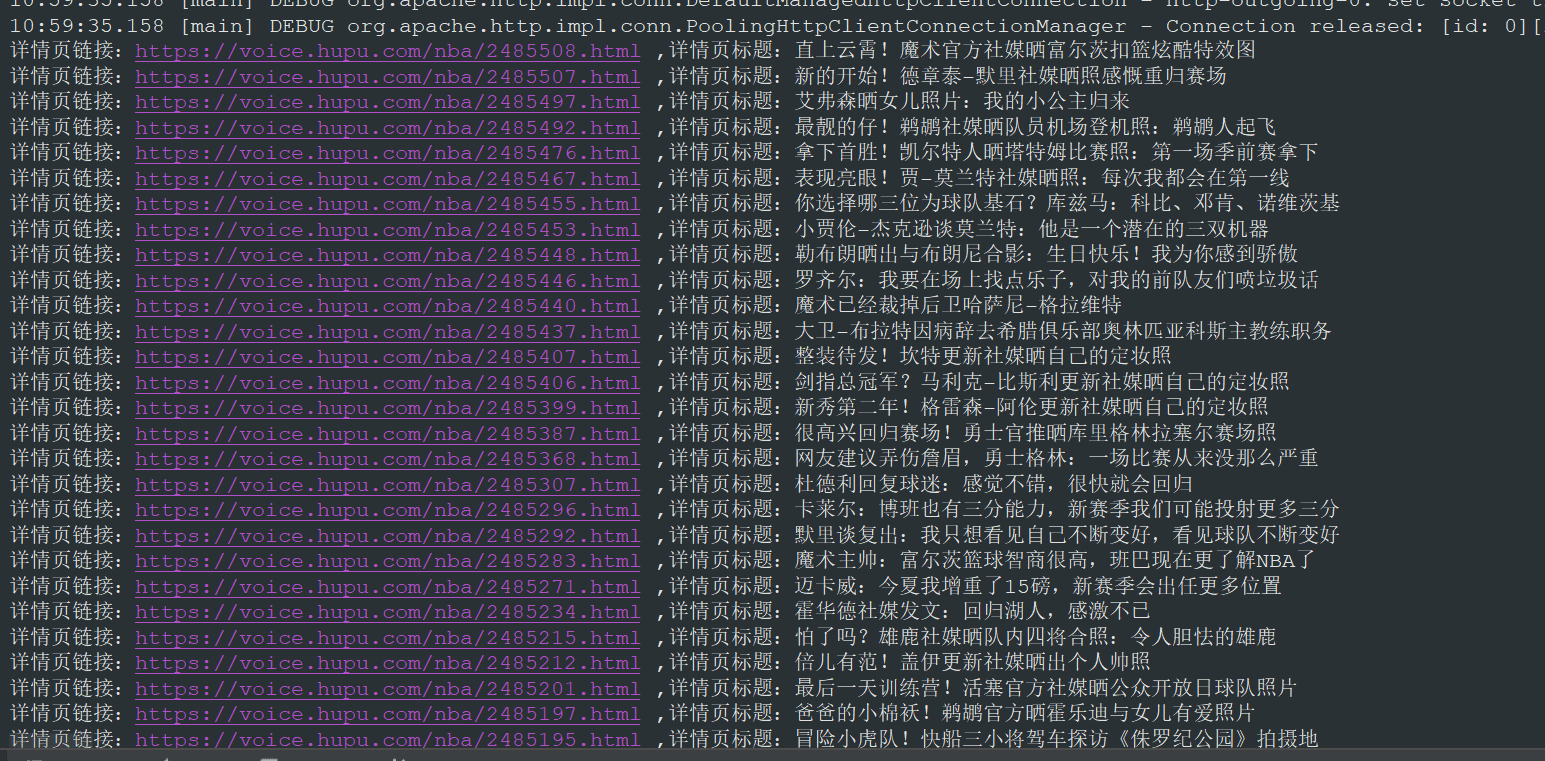
使用 httpclient + 正則表達式的方式同樣正確的獲取到了列表新聞的標題和詳情頁鏈接。這一篇主要是 Java 網絡爬蟲的入門,我們使用了 jsoup 和 httpclient + 正則的方式提取了虎撲列表新聞的新聞標題和詳情頁鏈接。當然這里還有很多沒有完成,比如采集詳情頁信息存入數據庫等。
以上是“Java網絡爬蟲的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





