溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何掌握圖計算平臺GraphScope”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何掌握圖計算平臺GraphScope”吧!
圖數據對一組對象(頂點)及其關系(邊)進行建模,可以直觀、自然地表示現實世界中各種實體對象以及它們之間的關系。在大數據場景下,社交網絡、交易數據、知識圖譜、交通和通信網絡、供應鏈和物流規劃等都是典型的以圖建模的例子。圖 1 顯示了阿里巴巴在電商場景下的圖數據,其中有各種類型的頂點(消費者、賣家、物品和設備)和邊(表示了購買、查看、評論等關系)。此外,每個頂點還有豐富的屬性信息相關聯。
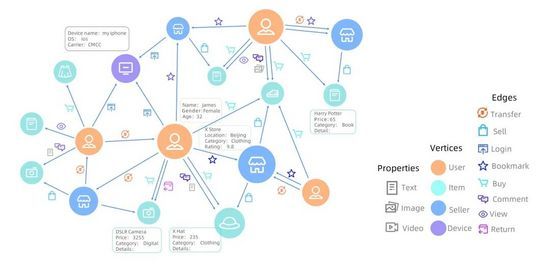
圖 1:阿里巴巴電商場景圖數據示例
實際場景中的這種圖數據通常包含數十億個頂點和數萬億條邊。除了規模大之外,這個圖的持續更新速度也非常快,每秒可能有近百萬的更新。隨著近年來圖數據應用規模的不斷增長,探索圖數據內部關系以及在圖數據上的計算受到了越來越多的關注。根據圖計算的不同目標,大致可以分為交互查詢、圖分析和基于圖的機器學習三類任務。
1 圖的交互查詢
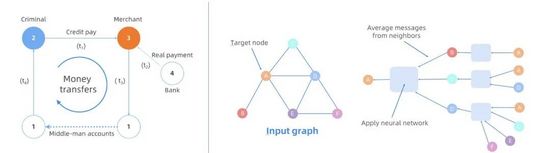
圖 2:左,金融反欺詐示例;右,圖學習示例。
在圖計算的應用中,業務通常需要以探索的方式來查看圖數據,以進行一些問題的及時定位和分析某個深入的信息,如 圖 2 (左)中的(簡化)圖模型可被用于金融反欺詐(信用卡非法套現)檢測。 通過使用偽造的標識符,“犯罪分子”可以從銀行獲得短期信用(頂點 4)。 他嘗試通過商家(頂點3)的幫助,以虛假購買( 邊 2->3)來兌現貨幣。 一旦從銀行(頂點4)收到付款(邊 4->3),商家再通過其名下的多個帳戶將錢(通過邊 3->1 和 1->2)退還給“犯罪分子”。 這種模式最終形成一個圖上的閉環(2->3->1...->2)。 真實場景中,圖數據在線上的規模可能包含數十億個頂點(例如,用戶)和數千億至萬億條邊(例如,支付交易),并且整個欺詐過程可能涉及到許多實體之間包含各種約束的動態交易鏈,因此需要復雜的實時交互分析才能很好的識別。
2 圖分析
關于圖分析計算的研究已經持續了數十年,產生了很多圖分析的算法。典型的圖分析算法包括經典圖算法(例如,PageRank、最短路徑和最大流),社區檢測算法(例如,最大團/clique、聯通量計算、Louvain 和標簽傳播),圖挖掘算法(例如,頻繁集挖掘和圖的模式匹配)。由于圖分析算法的多樣性和分布式計算的復雜性,分布式圖分析算法往往需要遵循一定的編程模型。當前的編程模型有點中心模型“Think-like-vertex”,基于矩陣的模型和基于子圖的模型等。在這些模型下,涌現出各種圖分析系統,如 Apache Giraph、Pregel、PowerGraph、Spark GraphX、GRAPE 等。
3 基于圖的機器學習
經典的 Graph Embedding 技術,例如 Node2Vec 和 LINE,已在各種機器學習場景中廣泛使用。近年來提出的圖神經網絡(GNN),更是將圖中的結構和屬性信息與深度學習中的特征相結合。GNN 可以為圖中的任何圖結構(例如,頂點,邊或整個圖)學習低維表征,并且生成的表征可以被許多下游圖相關的機器學習任務進行分類、鏈路預測、聚類等。圖學習技術已被證明在許多與圖相關的任務上具有令人信服的性能。與傳統的機器學習任務不同,圖學習任務涉及圖和神經網絡的相關操作(見圖 2 右),圖中的每個頂點都使用與圖相關的操作來選擇其鄰居,并將其鄰居的特征與神經網絡操作進行聚合。
不僅僅是阿里巴巴,近年來圖數據和計算技術一直是學術界和工業界的熱點。特別是,在過去的十年中,圖計算系統的性能已提高了 10~100 倍,并且系統仍在變得越來越高效,這使得通過圖計算來加速AI和大數據任務成為了可能。實際上,由于圖能十分自然地表達各種復雜類型的數據,并且可以為常見的機器學習模型提供抽象。與密集張量相比,圖能提供更豐富的語義和更全面的優化功能。此外,圖是稀疏高維數據的自然表達,并且圖卷積網絡(GCN)和圖神經網絡(GNN)中越來越多的研究證明,圖計算是對機器學習的有效補充,在結果的可解釋性、深層次推理因果等方面將扮演越來越重要的作用。
圖 3:圖計算在AI各個領域具有廣闊的應用前景
可以預見,圖計算將在下一代人工智能的各種應用中發揮重要作用,包括反欺詐,智能物流,城市大腦,生物信息學,公共安全,公共衛生,城市規劃,反洗錢,基礎設施,推薦系統,金融技術和供應鏈等領域。
經過這些年的發展,已有針對各種圖計算需求的多種系統和工具。例如在交互查詢方面,有圖數據庫Neo4j、ArangoDB和OrientDB等、也有分布式系統和服務JanusGraph、Amazon Neptune和Azure Cosmos DB等;在圖分析方面,有 Pregel、Apache Giraph、Spark GraphX、PowerGraph 等系統;在圖學習上有 DGL、pytorch geometric 等。盡管如此,面對豐富的圖數據和多樣化的圖場景,有效利用圖計算增強業務效果依然面臨著巨大的挑戰:
現實生活中的圖計算場景多樣,且通常非常復雜,涉及到多種類型的圖計算。現有的系統主要是為特定類型的圖計算任務設計的。因此,用戶必須將復雜的任務分解為涉及許多系統的多個作業。在系統之間可能會產生大量例如集成、IO、格式轉換、網絡和存儲方面的額外開銷。
難以開發大型圖計算的應用。為了開發圖計算的應用,用戶通常使用簡單易用的工具(例如 Python 中的 NetworkX 和 TinkerPop)在一臺機器上從小規模圖數據開始。但是,對于普通用戶而言,擴展其單機解決方案到并行環境處理大規模圖是極其困難的。現有的用于大規模圖的分布式系統通常遵循不同的編程模型,并且缺乏單機庫(例如 NetworkX)中豐富的即用算法/插件庫。這使得分布式圖計算的門檻過高。
處理大圖的規模和效率仍然有限。例如,由于游歷模式的高度復雜性,現有的交互式圖查詢系統無法并行執行 Gremlin 查詢。對于圖分析系統,傳統的點中心編程模型使圖級別的現有優化技術不再可用。此外,許多現有系統也基本未在編譯器級別上做過優化。
下面我們通過一個具體的示例看看現有系統的局限性。
1 示例:論文分類預測
數據集 ogbn-mag 是一個來自于微軟學術的數據集。數據中包含四種類型的點,分別表示論文、作者、機構、研究領域;在這些點之間有表示關系的四種邊:分別是作者 “ 撰寫 ” 了論文,論文 “ 引用 ” 了另一篇論文,作者 “ 隸屬于 ” 某個機構,和論文 “ 屬于 ” 某個研究領域。這個數據很自然的可以用圖來建模。
一個用戶期望在這個圖上對 2014-2020 年間發表的 “ 論文 ” 做一個分類任務,期望能根據論文在數據圖中的結構屬性、自身的主題特征、以及 kcore、三角計數 triangle-counting 等團聚度的衡量參數,將其歸類并預測文章的主題類別。實際上,這是一個十分常見和有意義的任務,這個預測由于考慮了論文的引用關系和論文的主題,可以幫助研究人員更好的發現領域內的潛在合作和研究熱點。
讓我們分解一下這個計算任務:首先我們需要對論文及其相關的點邊做一個根據年份的篩選,再需要在這個圖上計算 kcore、triangle-counting 等全圖計算,最后將這兩個參數和圖上的原始特征一起,放入一個機器學習框架進行分類訓練和預測。我們發現當前已有的系統并不能很好的端到端解決這個問題,我們只能通過將多個系統組織成一個 pipeline 的形式運行:
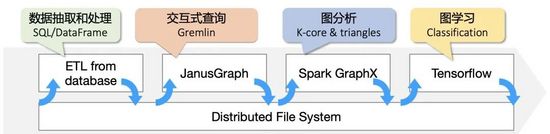
圖 4:論文分類預測多系統組成的工作流
這個任務看起來是解決了,實際上這樣流水線的方案背后隱藏著許多問題。例如多個系統之間互相獨立和割裂,中間數據頻繁落盤進行系統間的數據傳遞;圖分析的程序不是聲明性語言,沒有固定范式;圖的規模影響機器學習框架的效率等等。這些都是我們在現實圖計算場景中常遇到的問題,總結一下可以概括為以下三點:
圖計算問題十分復雜,計算模式多樣,解決方案碎片化。
圖計算學習難度強,成本大,門檻高。
圖的規模和數據量大,計算復雜,效率低。
為了解決以上的問題,我們設計并研發了一站式開源圖計算系統:GraphScope。
GraphScope 是阿里巴巴達摩院智能計算實驗室研發并開源的一站式圖計算平臺。依托于阿里海量數據和豐富場景,與達摩院的高水平研究,GraphScope 致力于針對實際生產中圖計算的上述挑戰,提供一站式高效的解決方案。
GraphScope 提供 Python 客戶端,能十分方便的對接上下游工作流,具有一站式、開發便捷、性能極致等特點。它具有高效的跨引擎內存管理,在業界首次支持 Gremlin 分布式編譯優化,同時支持算法的自動并行化和支持自動增量化處理動態圖更新,提供了企業級場景的極致性能。在阿里巴巴內部和外部的應用中,GraphScope 已經證明在多個關鍵互聯網領域(如風控,電商推薦,廣告,網絡安全,知識圖譜等)實現重要的業務新價值。
GraphScope 集合了達摩院的多項學術研究成果,其中的核心技術曾獲得數據庫領域頂級學術會議 SIGMOD2017 最佳論文獎、VLDB2017 最佳演示獎、VLDB2020 最佳論文提名獎、世界人工智能創新大賽SAIL獎。GraphScope 的交互查詢引擎的論文也已被 NSDI 2021 錄用,即將發表。還有其它圍繞 GraphScope 的十多項研究成果發表在領域頂級的學術會議或期刊上,如 TODS、SIGMOD、VLDB、KDD 等。
1 架構介紹
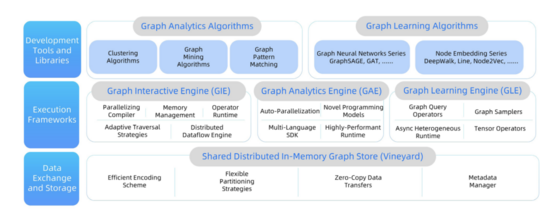
圖 5:GraphScope 系統架構圖
GraphScope 的底層是一個分布式內存數據管理系統 vineyard[1]。vineyard 也是我們開源的一個項目,它提供了高效和豐富的 IO 接口負責與更底層的文件系統交互,它提供了高效和高層次的數據抽象(包括但不限于圖,tensor,vector 等),支持管理數據的分區、元數據等,可以為上層應用提供本機零拷貝的數據讀取。正是這一點支持了 GraphScope 的一站式能力:在跨引擎之間,圖數據按分區的形式存在于 vineyard,由 vineyard 統一管理。
中間是引擎層,分別由交互式查詢引擎 GIE,圖分析引擎 GAE,和圖學習引擎 GLE 組成,我們將在后續的章節中詳細介紹。
最上層是開發工具和算法庫。GraphScope 提供了各類常用的分析算法,包括連通性計算類、社區發現類和 PageRank、中心度等數值計算類的算法,后續會不斷擴展算法包,在超大規模圖上提供與 NetworkX 算法庫兼容的分析能力。此外也提供了豐富的圖學習算法包,內置支持 GraphSage、DeepWalk、LINE、Node2Vec 等算法。
2 重解問題:論文分類預測
有了一站式計算平臺 GraphScope,我們可以用一種更簡單的方式解決前面示例中的問題。
GraphScope 提供 Python客戶端, 讓數據科學家可以在自己熟悉的環境中完成所有圖計算相關的工作。打開 Python 后,我們首先需要建立一個 GraphScope 會話。
import graphscope from graphscope.dataset.ogbn_mag import load_ogbn_mag sess = graphscope.sesson() g = load_ogbn_mag(sess, "/testingdata/ogbn_mag/")
在上面的代碼中,我們建立了一個 GraphScope 的 session,并載入了圖數據。
GraphScope 面向云原生設計,一個 session 的背后對應了一組 k8s 的資源,該session 負責這個會話中所有資源的申請和管理。具體來說,在用戶這行代碼的背后,session首先會請求一個后端總入口 Coordinator 的 pod。Coordinator 負責跟 Python 客戶端的所有通信,在完成自身的初始化后,它會拉起一組引擎 pod。這組 pod 中每一個 pod 都有一個 vineyard 實例,共同組成一個分布式內存管理層;同時,每一個 pod 中都有 GIE、GAE、GLE 三個引擎,它們的啟停狀態由 Coordinator 在后續按需管理。當這組 pod 拉起并與 Coordinator 建立穩定連接、完成健康檢查后,Coordinator 會返回狀態到客戶端,告訴用戶,session 已拉起成功,資源就緒可以開始載圖或計算了。
interactive = sess.gremlin(g) # count the number of papers two authors (with id 2 and 4307) have co-authored papers = interactive.execute("g.V().has('author', 'id', 2).out('writes').where(__.in('writes').has('id', 4307)).count()").one()首先我們在圖 g 上建立了一個交互式查詢對象 interactive 。這個對象在引擎 pod 中拉起了一組交互式查詢引擎 GIE。接著下面是一個標準的 Gremlin 查詢語句,用戶想在這個數據中查看兩個具體作者的合作論文。這個 Gremlin 語句會發送給 GIE 引擎進行拆解和執行。
GIE 引擎由并行化 Compiler、內存和調度管理、Operator 運行時、自適應的游歷策略和分布式 Dataflow 引擎等核心組件組成。在收到交互式查詢的語句后,該語句首先會被 Compiler 拆分,編譯成多個運行算子。這些算子再以分布式數據流的模型被驅動和執行,在這個過程中,每一個持有分區數據的計算節點都跑一份該數據流的拷貝,并行處理本分區的數據,并在過程中按需進行數據交換,從而并行化的執行 Gremlin 查詢。
Gremlin 復雜的語法下,游歷策略至關重要并影響著查詢的并行度,它的選擇直接影響著資源的占用和查詢的性能。只靠簡單的 BFS 或是 DFS 在現實中并不能滿足需求。最優的游歷策略往往需要根據具體的數據和查詢動態調整和選擇。GIE 引擎提供了自適應的游歷策略配置,根據查詢數據、拆解的 Op 和 Cost 模型選擇游歷策略,以達到算子執行的高效性。
# extract a subgraph of publication within a time range sub_graph = interactive.subgraph("g.V().has('year', inside(2014, 2020)).outE('cites')") # project the projected graph to simple graph. simple_g = sub_graph.project_to_simple(v_label="paper", e_label="cites") ret1 = graphscope.k_core(simple_g, k=5) ret2 = graphscope.triangles(simple_g) # add the results as new columns to the citation graph sub_graph = sub_graph.add_column(ret1, {"kcore": "r"}) sub_graph = sub_graph.add_column(ret2, {"tc": "r"})在通過一系列單點查看的交互式查詢后,用戶通過以上語句開始做圖分析任務。
首先它通過一個 subgraph 的操作子從原圖中根據篩選條件抽取了一個子圖。這個操作子的背后,是交互式引擎 GIE 執行了一個查詢,再將結果圖寫入了 vineyard。
然后用戶在這個新圖上抽取了 label 為論文的點和他們之間關系為引用(cites)的邊,產出了一張同構圖,并在上面調用了 GAE 的內置算法 k-core 和三角計數 triangles 在全圖做了分析型計算。產出結果后,這兩個結果被作為點上的屬性加回了原圖。這里,借助于 vineyard 元數據管理和高層數據抽象,新的 sub_graph 是通過原圖上新增一列的變換來生成的,不需要重建整張圖的全部數據。
GAE 引擎核心繼承了曾獲得 SIGMOD2017 最佳論文獎的 GRAPE 系統[2]。它由高性能運行時、自動并行化組件、多語言支持的 SDK 等組件組成。上面的例子用到了 GAE 自帶的算法,此外,GAE 也支持用戶十分簡單的編寫自己的算法并在其上即插即用。用戶以基于子圖編程的 PIE 模型編寫算法,或者重用已有圖算法,而不用考慮分布式細節,由 GAE 來做自動并行化,大幅降低了分布式圖計算對用戶的高門檻。目前,GAE 支持用戶通過C++、Python(后續將支持 Java)等多語言編寫自己的算法邏輯,即插即用在分布式環境。GAE 的高性能運行時基于 MPI,對通訊、數據排布,硬件特征做了十分細致的優化,以達到極致性能。
# define the features for learning paper_features = [] for i in range(128): paper_features.append("feat_" + str(i)) paper_features.append("kcore") paper_features.append("tc") # launch a learning engine. lg = sess.learning(sub_graph, nodes=[("paper", paper_features)], edges=[("paper", "cites", "paper")], gen_labels=[ ("train", "paper", 100, (1, 75)), ("val", "paper", 100, (75, 85)), ("test", "paper", 100, (85, 100)) ])接下來我們開始用圖學習引擎為論文分類。首先我們配置將數據中論文類節點的 128 維特征以及我們在上一步中計算出的 kcore 和 triangles 兩個屬性共同作為訓練特征。然后我們從 session 中拉起圖學習引擎 GIE。在拉起 GIE中 圖 lg 時,我們配置了圖數據,特征屬性,指定了哪一類的邊,以及將點集劃分為了訓練集、驗證集和測試集。
from graphscope.learning.examples import GCN from graphscope.learning.graphlearn.python.model.tf.trainer import LocalTFTrainer from graphscope.learning.graphlearn.python.model.tf.optimizer import get_tf_optimizer # supervised GCN. def train_and_test(config, graph): def model_fn(): return GCN(graph, config["class_num"], ...) trainer = LocalTFTrainer(model_fn, epoch=config["epoch"]...) trainer.train_and_evaluate() config = {...} train_and_test(config, lg)然后我們通過上面的代碼選用模型以及做一些訓練相關的參數配置就可以十分便捷的用 GLE 開始做圖分類任務。
GLE 引擎包含 Graph 與 Tensor 兩部分,分別由各種 Operator 構成。Graph 部分涉及圖數據與深度學習的對接,如按 Batch 迭代、采樣和負采樣等,支持同構圖和異構圖。Tensor 部分則由各類深度學習算子構成。在計算模塊中,圖學習任務被拆解成一個個算子,算子再被運行時分布式的執行。為了進一步優化采樣性能,GLE 將緩存遠程鄰居、經常訪問的點、屬性索引等,以加快每個分區中頂點及其屬性的查找。GLE 采用支持異構硬件的異步執行引擎,這使 GLE 可以有效地重疊大量并發操作,例如 I/O、采樣和張量計算。GLE 將異構計算硬件抽象為資源池(例如 CPU 線程池和 GPU 流池),并協作調度細粒度的并發任務。
GraphScope 不僅在易用性上一站式的解決了圖計算問題,在性能上也達到極致,滿足了企業級需求。我們使用 LDBC Benchmark 對 GraphScope 的性能進行了評估和對比測試。
如圖 6 所示,在交互式查詢測試 LDBC SNB Benchmark上,單節點部署的 GraphScope 與開源系統 JanusGraph 相比,多數查詢快一個數量級以上;在分布式部署下,GraphScope 的交互式查詢基本能達到線性加速的擴展性。
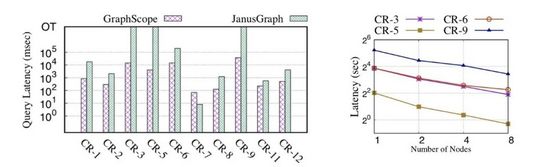
圖 6:GraphScope 交互式查詢性能
在圖分析測試 LDBC GraphAnalytics Benchmark 上,GraphScope 與 PowerGraph 以及其他最新系統比較,幾乎在所有算法和數據集的組合中居于領先水平。在某些算法和數據集上,跟其他平臺比較最低也有五倍的性能優勢。局部數據見下圖。
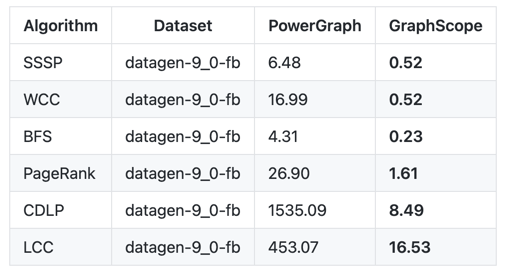
圖 7:GraphScope 圖分析性能
關于實驗的設定、重現和完整的性能比較可以參見交互式查詢性能[3]和圖分析性能[4]。
GraphScope 的白皮書、代碼已經在 github.com/alibaba/graphscope 開源[5],項目遵守 Apache License 2.0。 歡迎大家 star、試用,參與到圖計算 中來。 也歡迎大家貢獻代碼,一起打造業界最好的圖計算系統。 我們的目標是持續更新該項目,不斷提升功能的完整性和系統的穩定性。 也歡迎大家關注網站 graphscope.io 來跟進項目的最新狀態。
到此,相信大家對“如何掌握圖計算平臺GraphScope”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





