溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么在R語言中使用cut()函數?很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
R語言是用于統計分析、繪圖的語言和操作環境,屬于GNU系統的一個自由、免費、源代碼開放的軟件,它是一個用于統計計算和統計制圖的優秀工具。
cut()切割將x的范圍劃分為時間間隔,并根據其所處的時間間隔對x中的值進行編碼。
參數:breaks:兩個或更多個唯一切割點或單個數字(大于或等于2)的數字向量,給出x被切割的間隔的個數。
breaks采用fivenum():返回五個數據:最小值、下四分位數、中位數、上四分位數、最大值。
labels為區間數,打標簽
ordered_result 邏輯結果應該是一個有序的因素嗎?
先用fivenum求出5個數,再用labels為每兩個數之間,貼標簽,采用(]的區間, 再將各個數,對應區間,求出即可
>j1<-c(23,62,72,80,59,82,90,43,94)
break1<-fivenum(j1)
> break1
[1] 23 59 72 82 94
> labels = c("差", "中", "良", "優")
> j2<-cut(j1,break1,labels,ordered_result = T)
> j2
[1] <NA> 中 中 良 差 良 優 差 優
Levels: 差 < 中 < 良 < 優補充:R語言中使用CUT函數將數據進行分段重編碼
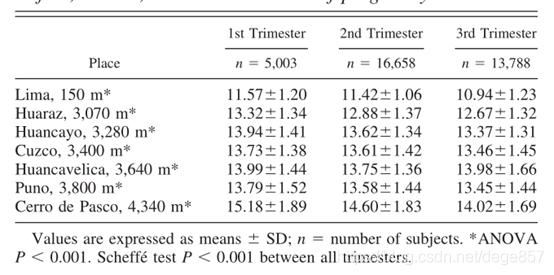
在很多SCI論文中,都會把連續變量進行分段比較,如年齡分為青年、中年、老年,或者把某一指標連續高,中,低分為幾等分再進行性分析,如下圖所示,把連續的孕周通過認為的分為早孕、中孕和晚孕
在R語言中,實現這種方法,我們需要把連續變量進行分段(也叫分箱)然后進行重編碼對數據進行分析,這一步很重要,這是為后面的分析做準備。今天我們通過使用R語言自帶的CUT函數來演示對數據的分段重編碼及數據整理。
我們今天使用SPSS軟件自帶的Breast cancer surviva的數據資料為演示,先打開Rstudiu把數據導入,并且刪除缺失值
library(foreign)#導入foreign包 bc <- read.spss(“E:/r/Breast cancer survival agec.sav”, use.value.labels=F, to.data.frame=T) bc <- na.omit(bc)
查看一下該數據
head(bc)

第二個指標是年齡,我們打算把年齡平局分為高中低三個區間
age1<-cut(bc$age,breaks = 3,labels = c(1,2,3))#平均分為3個區間,命名為1,2,3
dc<-cbind(bc,age1)#把變量加入表格
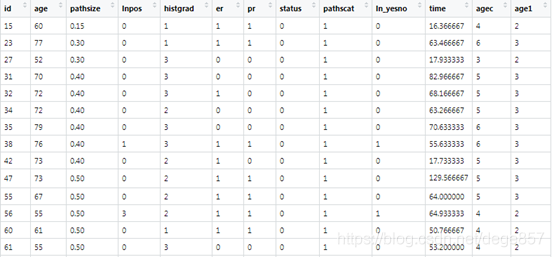
這樣就把年齡進行了分組重編碼。我們還可以對具體年齡段進行分組
age2<-cut(bc$age,breaks=c(0,20,60,100),include.lowest=T, labels = c(1,2,3))#把age劃分為0-20,20-60,60到100這樣3個區間 dd<-cbind(bc,age2)#把變量加入表格
也可以按百分位比把年齡進行分段
age3<-quantile(bc$age,c(0,.25,.50,.75,1)) dc<-cbind(bc,age3)#把變量加入表格
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





