溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關怎么在R語言中使用dplyr包對數據進行處理,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
1、數據篩選函數:
#可使用filter()函數篩選/查找特定條件的行或者樣本
#filter(.data=,condition_1,condition_2)#將返回相匹配的數據
#同時可以多條件匹配multiple condition,當采用多條件匹配時可直接condition1,condition2或者condition1&condition2
#其他邏輯表達還有:==,>,>=等,&,|,!,xor(),is.na,between,near
#filter延展的相關函數filter_all()、filter_if()、filter_at()
#以iris數據集為例:
filter(.data=iris,Sepal.Length>3,Sepal.Width<3.5) filter(.data=iris,Sepal.Length>3,Species=="virginica")
輸出情況: 輸出情況:


#要使用filter_all()、filter_if()、filter_at()需要先去掉Species列(非數值型列)
iris_data<-iris%>% select(-Species)
#篩選所有屬性小于6的行
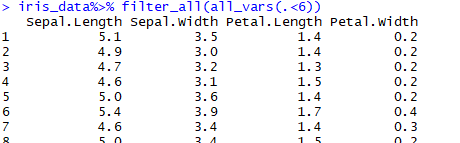
iris_data%>% filter_all(all_vars(.<6))
部分輸出情況:
#篩選任意一個屬性大于3的行
iris_data%>% filter_all(any_vars(.>3))
#篩選以sep開頭的屬性任一大于3的行
iris_data%>% filter_at(vars(starts_with("Sep")), any_vars(. >3))#R中自帶數據集mtcars,篩選任意一個屬性大于150的行
filter_all(mtcars, any_vars(. > 150))
#篩選以d開頭的屬性任一可被2整除的行
filter_at(mtcars, vars(starts_with("d")), any_vars((. %% 2) == 0))其他延展函數 group_by_all、group_by_if、group_by_at(將在后續文章中解析)
group_by函數按照某個變量分組,對于數據集本身并不會發生什么變化,只有在與mutate(), arrange() 和 summarise() 函數結合應用的時候會體現出它的優越性,將會對這些 tbl 類數據執行分組操作 (R語言泛型函數的優越性).
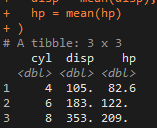
mtcars_cyl <- mtcars %>% group_by(cyl) mtcars_cyl %>% summarise( disp = mean(disp), hp = mean(hp) )
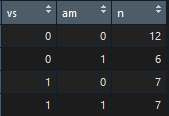
mtcars_vs_am <- mtcars %>% group_by(vs, am) mtcars_vs <- mtcars_vs_am %>% summarise(n = n())
可用的相關參數、邏輯:
? +, - 等等
? log()
? lead(), lag()
? dense_rank(), min_rank(), percent_rank(), row_number(), cume_dist(), ntile()
? cumsum(), cummean(), cummin(), cummax(), cumany(), cumall()
? na_if(), coalesce()
? if_else(), recode(), case_when()
相關延展函數:transmute、mutate_all、mutate_if、mutate_at(后期文章分享)
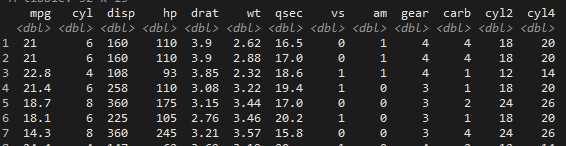
mtcars %>% as_tibble() %>% mutate( cyl2 = cyl*3, cyl4 = cyl2+2 )
上述就是小編為大家分享的怎么在R語言中使用dplyr包對數據進行處理了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





