溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“如何理解linux中的數值計算的語言”,在日常操作中,相信很多人在如何理解linux中的數值計算的語言問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”如何理解linux中的數值計算的語言”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
一、元組和數組
如果數值計算僅僅只是兩個標量之間的加減乘除,那就不需要我在這里浪費口舌了。向量啊、矩陣啊、多維數組啊什么,才是數值計算真正的主角。所以,適合做數值計算的編程語言必須有一個好的方式表示數組,特別是多維數組。哪種方式好呢?是這樣:
代碼如下:
int a[m][n][k];
還是這樣:
代碼如下:
int a[m,n,k];
看似沒有什么差別,但是如果你想獲取數組a的形狀呢?比如這樣:
代碼如下:
? = a.shape();
或者再更進一步,想改變數組a的形狀呢?比如這樣:
代碼如下:
a.reshape(?);
在上面的代碼中,“?”究竟應該用什么代替呢?
如果讓我給出答案,我會說:要用元組。很多編程語言中都有元組的概念,比如Python。元組就是用逗號隔開的幾個值,可以加圓括號,也可以不加。我覺得加上圓括號后可讀性更好。比如(a,b)是元組,(3,4,5)也是元組。如果寫成[3,4,5]那就是數組了,在Python中,也稱之為列表。不過Python的列表功能比數組要強大,因為數組只能保存同一種數據類型的值,而列表可以保存任何對象。數組一般情況下不能動態改變長度,而列表可以。Octave語言中使用cell array這個術語來表示可以保存不同類型對象的容器。Octave中的數組和矩陣是可以動態改變長度的。C語言的數組沒有動態改變長度這個功能,而如果使用C++的話,則必須使用vector<>模板類。
我認為,一個好的編程語言必須要有“元組”這個一個概念,必須能夠用好大括號、中括號和小括號。在有沒有元組這個問題上,很多語言做得不好,C語言沒有,C++也沒有,Java沒有,C#這個有很多新功能的語言也沒有,不要告訴我有Tuple<>模板類可以用,那個真的沒有語言內置的元組功能好。在能不能用好大中小括號這個問題上,C語言就做得不好。你看它不管是初始化數組,還是初始化struct,都是用大括號。而Python和JSON就做得很好嘛,初始化數組用中括號,初始化對象或字典的時候采用大括號。如果加上小括號表示元組,那就齊活兒了。
數值計算可以針對標量、一維數組、二維數組以及n維數組進行。數組可以如下組織,如下圖:
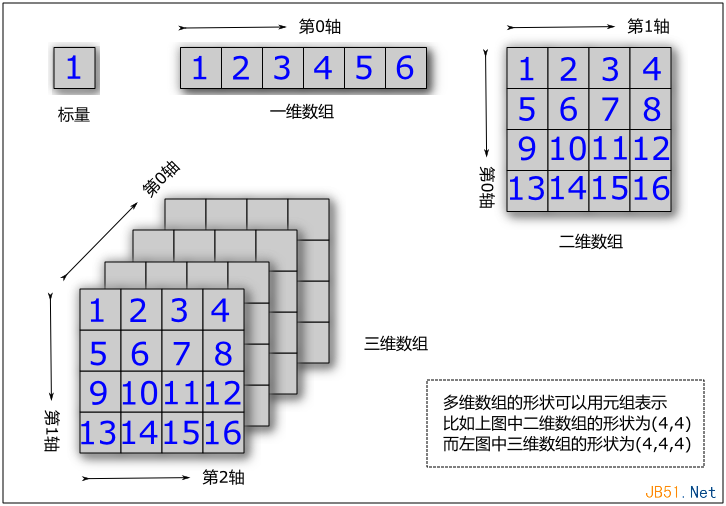
元組最大的用途就是可以用來表示數組的形狀了。比如一維數組的形狀為(n,),請注意其中的逗號不能省略。二維數組的形狀(m,n),三維數組的形狀(m,n,k),依次類推。另外,元組可以用來對數組中的元素進行索引。比如:
代碼如下:
a = [ [1,2,3,4], [5,6,7,8], [9,10,11,12], [13,14,15,16] ];b = a[2,3,3];
元組還有一個很大的用途,那就是可以讓一個函數返回多個值。C語言在這個方面是做得比較丑陋的,如果一個函數要返回多個值,只能給這個函數傳指針或者多重指針作為參數,C++可以傳引用,C#更加畫蛇添足,專門有一個out關鍵字用來修飾函數的參數。微軟你真是的,你既然能想到out,你就不能想到元組嗎?常見的例子,比如meshgrid()函數可以同時初始化兩個數組,peak()函數可以同時初始化三個數組。你看它們用元組多方便:
代碼如下:
(xx, yy) = meshgrid(x, y);(xx, yy, zz) = peak();
另外,元組還可以這樣用,比如交換兩個變量的值:
代碼如下:
(a,b) = (b,a);
二、數組初始化
在數值計算中,數組的初始化也是非常重要的一環。如果像C語言這樣寫:
代碼如下:
int a[100] = {1, 2, 3, 4, ... , 100};
估計很多人是要罵娘的。這樣寫:
代碼如下:
for(int i=0; i<100; i++){ a[i] = i+1;}
也不優雅。我只是想初始化一個數組而已,怎么就非得要寫一個循環呢?如果是二維數組呢,就得兩層循環,三維數組就得三層。真的是太鬧心了。
另外,如前所述,我也不喜歡在初始化數組的時候用大括號。我覺得中括號就是為數組而生。比如這樣:
代碼如下:
a = [1, 2, 3, 4];
這就是一個一維數組,但是如果這樣寫:
代碼如下:
a = [ [1, 2, 3, 4] ];
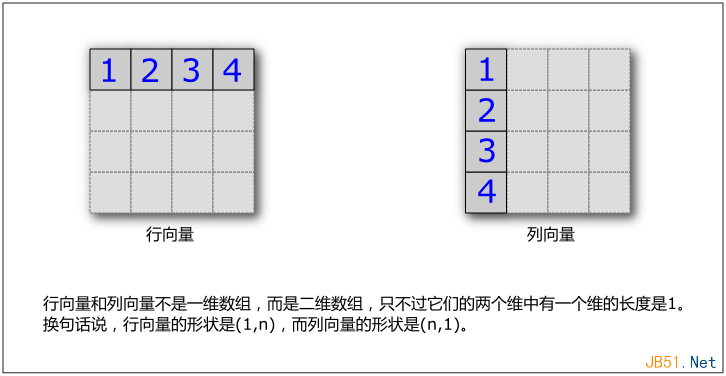
就是一個行向量。如果寫成這樣:
代碼如下:
a = [ [1], [2], [3], [4] ];
那么這就是一個列向量,如下圖:
當然,上面的示例只有四個數字,這么寫一寫無可厚非。如果是很多數字呢?或者很多維的數組呢?這時就必須得用到很多初始化函數了,而且這些初始化函數最好能接受元組作為參數來決定數組的形狀。比如這樣:
代碼如下:
a = xrange( 1, 60, (3,4,5) ); //用1到60的數字初始化一個3*4*5的數組
b = randn ( (3, 4, 5) ); //用隨機數初始化一個3*4*5的數組
其它的初始化函數還有linspace()、logspace()、ones()、zeros()、eyes()等等。這些函數還可以配合reshape()使用,比如這樣:
代碼如下:
c = linspace(0, 2*pi, 60).reshape(3, 4, 5);
在所有的這些初始化中,元組都是重要的組成部分。
三、range和切片
其實,range除了可以是一個函數,還可以更省點兒事,像這樣寫:
代碼如下:
r = 0:10:2; //0,2,4,6,8,10
s = 11:0:-3; //11,8,5,2
在某些語言中,也把這個功能叫切片。其實就是“:”的靈活運用,有標點符號可以用當然不能浪費嘛。使用切片,只需要指定起始值、終止值和步長,就可以獲得一個數字序列。
但是,“:”最大的用途并不是用來對數組進行初始化,而是對數組進行索引。比如,a是一個三維數組,可以通過切片來獲取其中的一部分數據。見下面的代碼:
代碼如下:
a = range(1, 60).reshape(3, 4, 5); // a是一個三維數組
b = a[1, 2:3, 1:4]; // b是一個二維數組,其值為[ [12, 13, 14, 15], [17, 18, 19, 20]]
切片除了可以指定起始值和終止值外,也可以指定步長。當然,也可以只用一個單獨的“:”,代表取這一整個軸。關于軸的概念,可以看我前面的圖片。見下面這樣的代碼:
代碼如下:
a = range(1, 60).reshape(3, 4, 5); // a是一個三維數組
b = a[1, :, :]; // b的值為二維數組[[1,2,3,4,5], [6,7,8,9,10], [11,12, 13, 14, 15], [16,17, 18, 19, 20]]
四、不寫循環
在對多維數組進行加減乘除的時候,如果使用傳統的像C這樣的語言,則避免不了要寫循環。比如要計算兩個多維數組的加法,不得不寫這樣的代碼:
代碼如下:
m = 10;
n = 20;
k = 30;
a = randn(m, n, k); //形狀為(m, n, k)的三維數組,初始化為隨機值
b = randn(m, n, k); //形狀為(m, n, k)的三維數組,初始化為隨機值
for(int i=0; i<m; i++){
for(int j=0; j<n; j++){
for(int p=0; p<k; p++){
c[i, j, p] = a[i, j, p] + b[i, j, p];
}
}
}
上面的代碼當然遠不如下面這樣的代碼簡潔:
代碼如下:
C = A + B;
所以不寫循環基本上就成了所有數值計算語言的標準配置。Matlab和Octave是這樣,NumPy是這樣,R語言也是這樣。C++也在追求這樣,因為C++中有運算符重載的功能,所以可以對矩陣類重載加減乘除運算符。但是C++中運算符的基礎設施有缺陷,比如它沒有乘方運算符(冪運算符),在Octave和NumPy中,都可以這樣計算$x^y$:x**y。但是在C++中,只有使用函數power(x, y)。不要想^運算符,它是一個位運算符,所以取冪只有使用**了。另外,多維數組運算還有特例,比如二維數組之間加減乘除,既可以是逐元素的加減乘除,也可以是矩陣的加減乘除。向量計算也有特例,既可以是逐元素加減乘除,也可能是向量內積(點乘)。如果正好是長度為3的向量,還可以計算叉乘。這些運算符都需要重新定義,所以雖然C++有重載運算符的機制,但是因為這些運算符完全超越了C++的基礎設施,所以C++也沒有辦法寫得很優雅。
不寫循環還有一個優點,那就是可以對運算速度進行優化。優化是編譯器或解釋器的責任,寫數值計算程序的人可以完全不用費心。編譯器或解釋器可采取的優化方式有可能是利用SSE等多媒體指令集,也可能是發揮多核CPU的多線程優勢,甚至是使用GPGPU計算都有可能。如果用戶非要寫成C語言那樣的循環,而他又不會內聯匯編或OpenMP的話,那么就談不上什么運算速度的優化了。
五、廣播
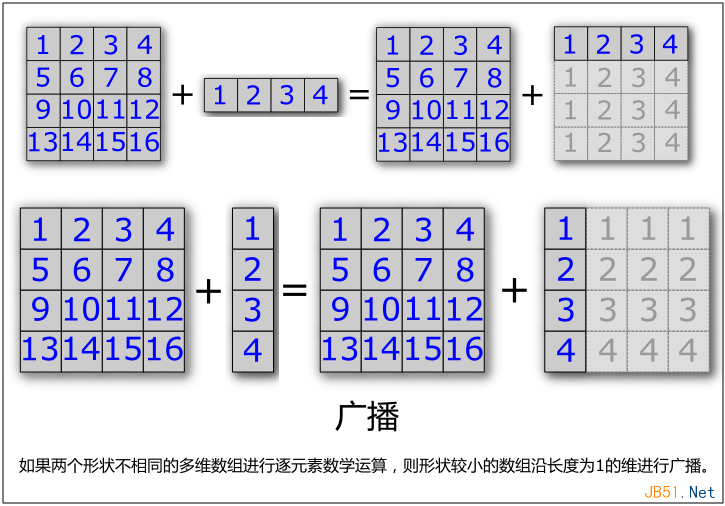
不寫循環,直接把兩個多維數組進行加減乘除當然省事。但是如果兩個數組的形狀不一樣呢?比如一個二維數組加一個行向量,或一個二維數組加一個列向量,甚至是數組加減乘除一個標量,會出現什么情況呢?
不用擔心,在面向數值計算的語言中,一般都有“廣播”這樣一個特性。當兩個數組的形狀不一樣時,形狀比較小的那個往往可以在長度為1的維度上進行廣播。如下圖:
六、奇異索引
Fancy indexing,有的書上翻譯成花式索引,但我認為叫奇異索引比較好。它就是指一個低維的數組,可以使用高維的數組進行索引,最后得到的結果是一個高維的數組。如果索引中含有切片,可能會得到一個更高維度的數組作為結果。
這個概念理解起來比較難。特別是再配合切片使用,更加增加其復雜性。所謂一圖勝千言,先看普通索引的情況:
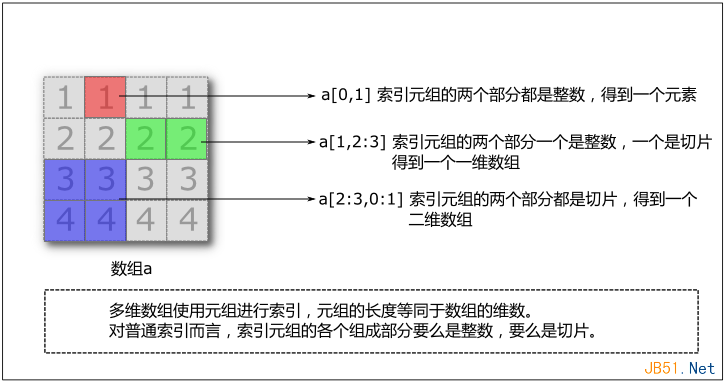
前面提到,對多維數組進行索引的時候需要用到元組,元組的長度等同于數組的維數。對于普通索引而言,元組的各個部分要么是整數,要么是切片。而對于奇異索引而言,索引元組的各個組成部分都可能是多維數組或者切片。如果是多維數組,則最后得到的數組的形狀和索引數組的形狀相同,如果配合切片,則可能得到更高維的數組。如下圖:
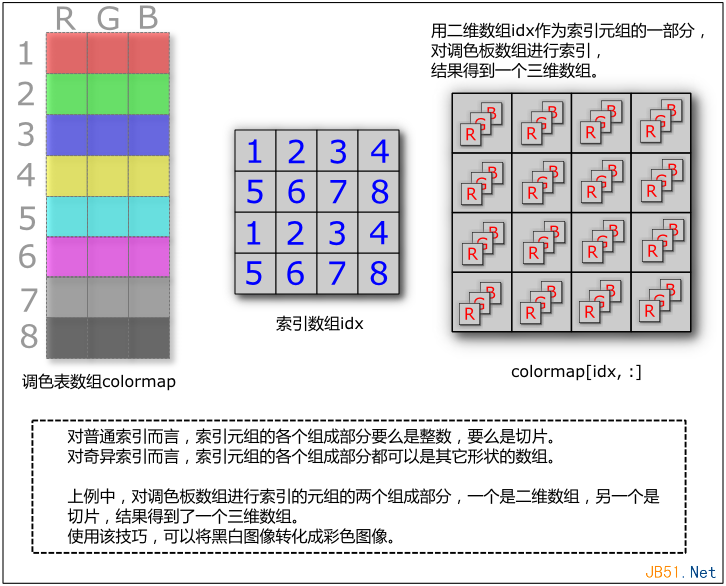
七、函數調用
編程語言發展這么多年,一直在進化,也一直在相互靠攏。對于一個編程語言來說,是應該面向過程還是面向對象?是靜態類型還是動態類型?這些都是值得思考的地方。但是在函數調用方面,有一些思想倒是可以學習。
在C語言這樣比較古老的語言中,對于函數的參數來說,只有位置參數一種。也就是說,像一個函數傳遞參數的時候,只能正確的參數放到正確的位置,而且參數的個數必須和函數定義的相同。這是最原始的函數調用思想。
緊接著,在某些編程語言如Java、C#中,有了可選參數這個概念。但是可選參數要放到參數列表的最后面,而且必須提供默認值。當調用函數時如果指定了這個參數,則使用調用時指定的值,否則使用默認值。
但是我覺得適合數值計算的語言必須還得更進一步,提供關鍵字參數的功能。什么是關鍵字參數呢?比如對數據進行繪圖的時候,需要指定線型、標簽、標題等各種屬性,可以這樣調用函數:
代碼如下:
plot(x, y, marker="*", color="r", line, title="...", legend="...", xlabel="...", ylabel="...");
每一個參數調用的時候都可以指定它的名字,這樣我們就不用去死記各個參數的位置,是不是很方便呢?
八、生態環境
對于一門編程語言而言,生態壞境很重要。在數值計算領域更是如此。因為很多數值計算的庫都是專業的人士寫給專業人士看的,比如物理專業的寫物理領域的算法,氣象專業的寫氣象專業的算法,所以不大可能有一個全面的官方的,像C或C++這樣一個由ANSI定義的庫。
廣泛接受開源社區的貢獻是一個比較好的辦法。Perl是這樣,Python也是這樣,新興的R語言也是這樣。Perl有CPAN,Python有PyPI,R語言也有CRAN。至于Matlab,那更是有各種各樣的工具包。
到此,關于“如何理解linux中的數值計算的語言”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





