溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了shell字符串匹配的實現方法,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
Bash Shell提供了很多字符串和文件處理的命令。如awk、expr、grep、sed等命令,還有文件的排序、合并和分割等一系列的操作命令。grep、sed和awk內容比較多故單獨列出,本文只涉及字符串的處理和部分文本處理命令。
expr引出通用求值表達式,可以實現算術操作、比較操作、字符串操作和邏輯操作等功能。
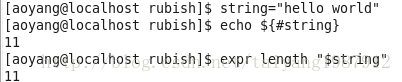
(1)計算字符串長度
字符串名為string,可以使用命令${#string}或expr length $string兩種方法來計算字符串的長度。若string包括空格,需用雙引號引起來(expr length后面只能跟一個參數,string有空格會當作多個參數處理)。
(2)子串匹配索引
expr的索引命令格式為:expr index $string $substring(子串),在字符串$string上匹配$substring中字符第一次出現的位置,匹配不到,expr index返回0。

"wo"在字符串string中雖然出現在第7,但還是返回o首次出現的位置5。
(3)子串匹配的長度
expr match $string $substring,在string的開頭匹配substring字符串,返回匹配到的substring字符串的長度,若string開頭匹配不到則返回0,其中substring可以是字符串也可以是正則表達式。
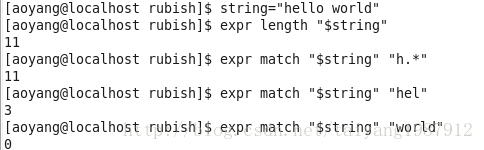
"world"盡管在string中出現,但是未出現在string的開頭處,因此返回0。
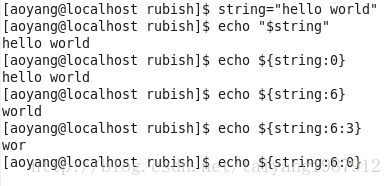
(4)抽取子串
Bash Shell提供兩種命令#{...}和expr實現抽取子串功能。
其中#{...}有兩種格式。
格式一:#{string:position}從名稱為$string的字符串的第$position個位置開始抽取子串,從0開始標號。
格式二:#{string:position:length}增加$length變量,表示從$string字符串的第$position個位置開始抽取長度為$length的子串。
(都是從string的左邊開始計數抽取子串)
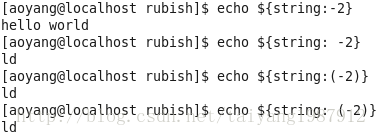
#{...}還提供了從string右邊開始計數抽取子串的功能。
格式一:#{string: -position},冒號與橫杠間有一個空格
格式二:#{string:(position)}
expr substr也能夠實現抽取子串功能,命令格式:expr substr $string $position $length,與#{...}最大不同是expr substr命令從1開始進行標號。

接著使用正則表達式抽取子串的命令,但只能抽取string開頭處或結尾處的子串。
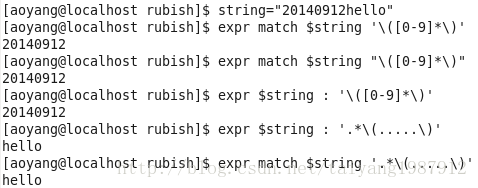
抽取字符串開頭處的子串,格式一:expr match $string ' $substring '。格式二:expr $string : ' $substring ',其中冒號前后都有一個空格。
抽取字符串結尾處的子串,格式一:expr match $string '.* $substring '。格式二:expr $string : '.* $substring '。.*表示任意字符的任意重復。
(5)刪除子串
刪除字串是指將原字符串中符合條件的子串刪除,命令只有${...}格式。
從string開頭處刪除子串,格式一:${string#substring},刪除開頭處與substring匹配的最短子串。格式二:${string##substring}刪除開頭處與substring匹配的最長子串。其中substring并非是正則表達式而是通配符。
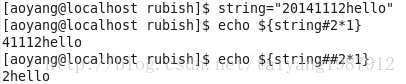
從string結尾處開始刪除,格式一:${string%substring},刪除結尾處與substring匹配的最短子串。格式二:${string%%substring}刪除結尾處與substring匹配的最長子串。與上述命令僅在#和%之間不同。
(5)替換子串
替換子串命令都是${...},可以在任意處、開頭處、結尾處替換滿足條件的子串。其中的substring都不是正則表達式而是通配符。
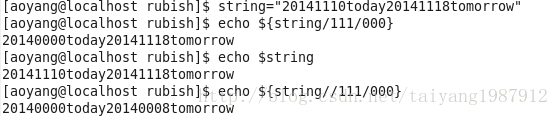
在任意處替換子串命令,格式一:${string/substring/replacement},僅替換第一次與substring相匹配的子串。格式二:${string//substring/replacement},替換所有與substring相匹配的子串。
在開頭處替換與substring相匹配的子串,格式為:${string/#substring/replacement}。
在結尾除替換與substring相匹配的子串,格式為:${string/%substring/replacement}。

文本處理命令包括sort命令、uniq命令、join命令、cut命令、paste命令、split命令、tr命令和tar命令,它們實現對文件記錄排序、統計、合并、提取、粘貼、分割、過濾、壓縮和解壓縮等功能,它們與sed和awk構成了Linux文本處理的所有命令和工具。
(1)sort命令
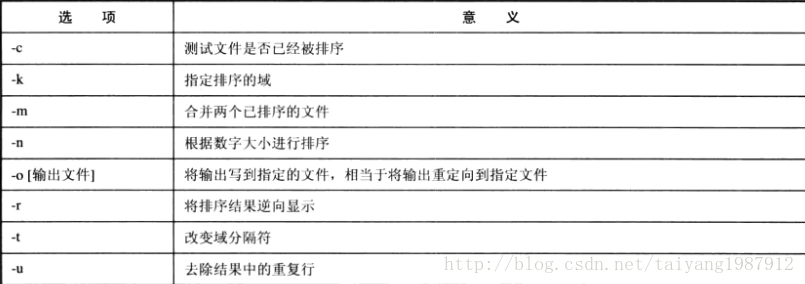
sort命令是一種對文本排序的工具,它將輸入文件看做由多條記錄組成的數據流,而記錄由可變寬度的字段組成,以換行符作為定界符。sort命令格式:sort [選項] [輸入文件]
sort命令默認的域分隔符是空格符,-t選項可用于設置分隔符。sort -t: test中-t與":"之間是沒有空格的。未指定-t分隔符是空格符,這時記錄內開頭與結尾的空格都將被忽略,如(空格):root:(空格)則只有一個域,-t:指定冒號則這條記錄就包含了三個域。
sort命令默認是按第1個域進行排序的,也可以通過-k選項指定某個域進行排序。例如:sort -t: -k3 test。
sort命令-n選項可以指定根據數字大小進行排序(不按字母順序排序)。
sort命令-r選項用于將排序結果逆向顯示,如使用-n按數字從小到大排序后,使用-r選項將結果逆向顯示。
sort命令-u選項去掉排序結果中的重復行。
sort命令-o選項加上文件名將結果保存到另一個文件中(sort默認將排序后的結果輸出到屏幕上)。
sort命令-m選項將兩個排好序的文件合并成一個排好序的文件,在文件合并前它們必須已經排好序。-m選項對未排序的文件合并是沒有任何意義的。
sort和awk都是分域處理文件的工具,兩者結合起來可以有效地對文本塊進行排序。
(2)uniq命令
uniq命令用于去除文本文件中的重復行,類似sort -u,但uniq命令去除的重復行必須是連續重復出現的行,中間不能夾雜任何其他文本行,而sort -u命令使所有的重復記錄都被去掉。
uniq命令有3個選項:

uniq -c test,打印每行在文本中重復出現的次數。
(3)join命令
join命令用于實現兩個文件中記錄的連接操作,將兩個文件中具有相通域的記錄選擇出來,再將這些記錄所有的域放在一行(包含來自兩個文件的所有域)。如join -t: a.txt b.txt,將a.txt和b.txt具有共同域的記錄連接到一起。
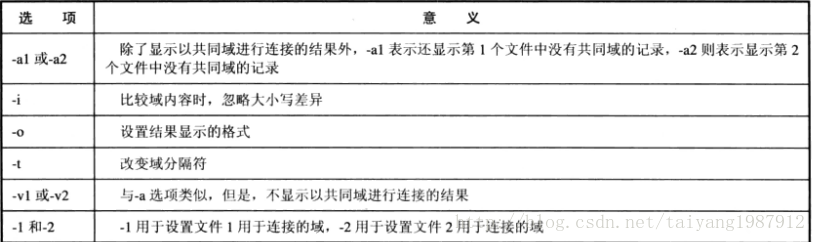
join命令的結果默認是不顯示這些未進行連接的記錄,-a和-v選項用于顯示這些未進行連接的記錄,-a1和-v1指顯示文件1中未連接的記錄,而-a2和-v2指顯示文件2中的未連接記錄。-a與-v的區別是:-a顯示以共同域進行連接的結果和未進行連接的記錄,而-v則不顯示以共同域進行連接的記錄。
join命令默認顯示連接記錄在兩個文件中的所有域,而且按順序。-o選項用于改變結果顯示的格式,可以指定顯示哪幾個域、按什么順序顯示這些域。例如:join -t: -o1.1 2.2 1.2 a.txt b.txt,其中-o1.1 2.2 1.2表示顯示格式依次顯示第1個文件中的第1個域、第2個文件中的第2個域、第1個文件中的第2個域,結果顯示三個域。
join -t: -i -1 3 -2 1 a.txt b.txt,文件1的第3個域和文件2的第1個域進行連接,-i忽略大小寫。join命令在對兩個文件進行連接時,兩個文件必須都是按照連接域排好序的。
(4)cut命令
cut命令用于從標準輸入或文本文件中按域或行提取文本,cut [選項] 文件,cut的選項如下:

cut -c1-5 a.txt,提取a.txt的第1~5個字符。-c有三種表示方式:-cn表示第n個字符、-cn,m表示第n個字符和第m個字符、-cn-m表示第n個字符到第m個字符。-c是按字符提取文本的,無須使用-d改變域分隔符,-f按域提取文本時就需要使用-d設置域分隔符了。-f同樣也可以用三種方式指定域數或域范圍。
cut可以靈活提取文本文件中的內容,默認將提取內容放在標準輸出上,也可以使用文件重定向來將內容保存到文件。
(5)paste命令
paste命令用于將文本文件或標準輸出中的內容粘貼到新的文件,它可以將來自不同文件的數據粘貼到一起,形成新的文件。paste命令格式:paste [選項] file1 file2,其選項如下:

paste FILE1 FILE2,粘貼FILE1和FILE2,FILE1在前,將FILE1的內容作為每行記錄的第1域、FILE2的內容作為第2域。可以使用-d設置域分隔符paste -d: FILE1 FILE2。
paste命令默認是將一個文件按列粘貼的,-s選項可以實現將一個文件按行粘貼。
ls | paste -d" " - - - -,從標準輸入中讀取數據時"-"選項才起作用,"-"表示讀取1次標準輸入數據即讀取到標準輸入數據中的一個域,- - - - 每行顯示4個文件名。
(6)split命令
split命令用于將大文件切割成小文件,split可以按照文件的行數、字節數切割文件,并能在輸出的多個小文件中自動加上編號。split命令格式:splite [選項] 待切割的大文件 輸出的小文件。

split -2 a.txt final.txt,按2行對a.txt進行切割,每2行記錄切割成1個文件。split命令在final.txt后面自動加上編號以區分不同的小文件,編號為aa~zz。
split -b100 a.txt,-b選項在切割文件時僅考慮了文件大小并未考慮記錄的完整性。split -C100 a.txt,按100B切割a.txt,按-C并不嚴格按照100B的大小進行切割,而是在切割時盡量維持每行的完整性。
(7)tr命令
tr命令實現字符轉換功能,類似于sed命令,tr能實現的功能sed命令都可以實現。tr [選項] buffer1 buffer2 < outputfile,其選項有三個,它只能從標準輸入讀取數據。

tr -d A-Z < a.txt,刪除a.txt文件中所有的大寫字母。
tr -d "[\n]" < a.txt,刪除a.txt文件中所有的換行符。
tr -s "[\n]" < a.txt,將重復出現的換行符壓縮成一個換行符。
tr命令也可以加上buffer1和buffer2,將buffer1用buffer2來替換,tr "[a-z]" "[A-Z]" < a.txt,將a.txt中的小寫字母替換成大寫字母。
(8)tar命令
tar命令是linux的歸檔命令,實現linux系統文件的壓縮和解壓縮。tar [選項] 文件名或目錄名,tar的常用選項如下:
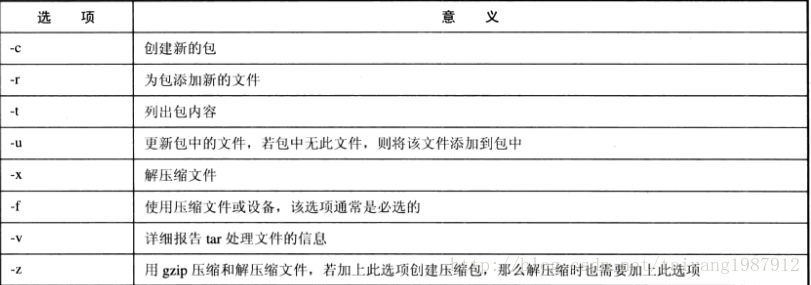
tar -cf a.tar *.txt,將所有的.txt結尾的文件放入壓縮包a.tar。-c表示創建新的包,-f通常是必選選項。
tar -tf a.tar,查看a.tar壓縮包的內容。-t列出包內容。
tar -rf a.tar log*,將以log開頭的文件添加到a.tar中,-u選項也可用于為包添加新的文件,-u選項完全能代替-r選項。
解壓非gzip格式的壓縮包:tar -xvf 壓縮包名稱
解壓gzip格式的壓縮包:tar -zxvf 壓縮包名稱
感謝你能夠認真閱讀完這篇文章,希望小編分享的“shell字符串匹配的實現方法”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





