溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何正確的使用python爬蟲調度器,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
我們可以編寫幾個元件,每個元件完成一項功能,下圖中的藍底白字就是對這一流程的抽象:
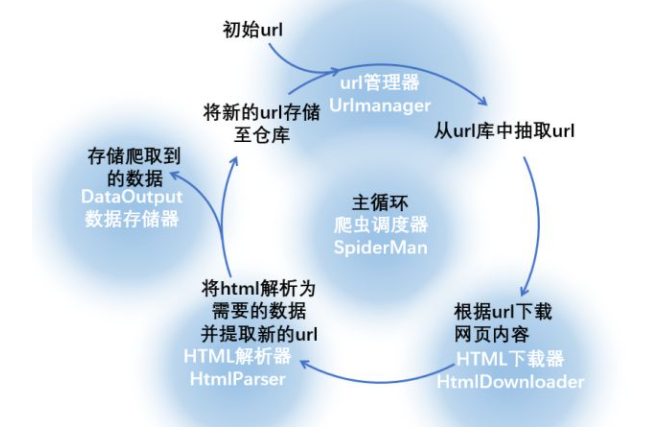
UrlManager:將存儲和獲取url以及url去重的幾個步驟在url管理器中完成(當然也可以針對每一步分別編寫相應的函數,但是這樣更直觀)。url管理器要有兩個url倉庫,一個存儲未爬取的url,一個存儲已爬取的url,除了倉庫之外,還應該具有一些完成特定功能的函數,如存儲url、url去重、從倉庫中挑選并返回一個url等
HtmlDownloader:將下載網頁內容的功能在HTML下載器中完成,下載器的功能較為單一,不多解釋。但從整個爬蟲的角度上來說,下載器是爬蟲的核心,在實際操作的過程中,下載器要和目標網站的各種反爬蟲手段斗智斗勇(各種表單、隱藏字段和假鏈接、驗證碼、IP限制等等),這也是最耗費大腦的步驟
HtmlParser:解析提取數據的功能在HTML解析器中完成,解析器內的函數應該分別具有返回數據和新url的功能
DAtaOutput:存儲數據的功能由數據存儲器完成
SpiderMan:主循環由爬蟲調度器來完成,調度器為整個程序的入口,將其余四個元件有序執行
爬蟲調度器將要完成整個循環,下面寫出python下爬蟲調度器的程序:
# coding: utf-8
new_urls = set()
data = {}
class SpiderMan(object):
def __init__(self):
#調度器內包含其它四個元件,在初始化調度器的時候也要建立四個元件對象的實例
self.manager = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.output = DataOutput()
def spider(self, origin_url):
#添加初始url
self.manager.add_new_url(origin_url)
#下面進入主循環,暫定爬取頁面總數小于100
num = 0
while(self.manager.has_new_url() and self.manager.old_url_size()<100):
try:
num = num + 1
print "正在處理第{}個鏈接".format(num)
#從新url倉庫中獲取url
new_url = self.manager.get_new_url()
#調用html下載器下載頁面
html = self.downloader.download(new_url)
#調用解析器解析頁面,返回新的url和data
try:
new_urls, data = self.parser.parser(new_url, html)
except Exception, e:
print e
for url in new_urls:
self.manager.add_new_url(url)
#將已經爬取過的這個url添加至老url倉庫中
self.manager.add_old_url(new_url)
#將返回的數據存儲至文件
self.output.store_data(data)
print "store data succefully"
print "第{}個鏈接已經抓取完成".format(self.manager.old_url_size())
except Exception, e:
print e
#爬取循環結束的時候將存儲的數據輸出至文件
self.output.output_html()關于如何正確的使用python爬蟲調度器就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





