溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

手勢→預測→行動
您可以在此處找到Github項目存儲庫中的代碼,或在此處查看最終的演示文稿幻燈片。
(github傳送門:
https://github.com/athena15/project_kojak
PPT傳送門:
https://docs.google.com/presentation/d/1UY3uWE5sUjKRfV7u9DXqY0Cwk6sDNSalZoI2hbSD1o8/edit#slide=id.g49b784d7df_0_2488)
靈感
想象一下,你正在舉辦一個生日聚會,每個人都玩的很開心,音樂也嗨到了極限,我們經常在抖音上看到的大聲呼喚天貓精靈、小米小愛等智能音響的場景,在這種時候就不起作用了,很可能它們根本聽不到你的聲音,基本上你也找不到遙控器,但如果這個時候你在談話當中張開一只手,某個手勢,你的智能家居設備就可以識別這種姿勢,關閉音樂,然后調亮燈光打到生日壽星的臉上。那確實是有點浪漫,也有點酷的。
背景
很長時間我都對手勢檢測感到好奇。我記得當第一部微軟Kinect問世的時候- 我只用一揮手就可以玩游戲并控制屏幕。慢慢地,谷歌主頁和亞馬遜Alexa等設備發布,似乎手勢檢測失去了語音的雷達的支持。不過,隨著Facebook門戶網站和亞馬遜回聲秀(Amazon Echo Show)等視頻設備的推出,我想看看是否有可能構建一個能夠實時識別我的手勢的神經網絡,并運行我的智能家居設備!
數據和我的早期模型
我對這個想法感到很興奮,并迅速采取了行動,就像我被射出大炮一樣。我開始在Kaggle.com上使用手勢識別數據庫,并探索數據。它由20,000個標記的手勢組成,如下面所示。

奇怪的圖像,但標簽豐富
當我閱讀圖像時,我遇到的第一個問題是我的圖像是黑白的。這意味著NumPy陣列只有一個通道而不是三個通道(即每個陣列的形狀是(224,224,1))。因此,我無法將這些圖像與VGG-16預訓練模型一起使用,因為該模型需要RGB的3通道圖像。這是通過在圖像列表上使用np.stack解決的,X_data:

一旦我克服了這個障礙,我就開始建立一個模型,使用一個訓練-測試分割,完全顯示照片10個人中的2個。在重新運行基于VGG-16架構的模型后,我的模型獲得了總體0.74的F1分數。這是非常好的,因為超過10個類的隨機猜測平均只能得到10%的準確率。
但是,訓練模型以識別來自同質數據集的圖像是一回事。另一個方法是訓練它以識別以前從未見過的圖像是另一種。我嘗試調整照片的光線,并使用深色背景- 模仿模特訓練過的照片。
我也嘗試過圖像增強——翻轉、傾斜、旋轉等等。雖然這些圖像比以前做得更好,但我仍然無法預測,而且在我看來是不可接受的——結果。我需要重新思考這個問題,并提出一種創造性的方法來使這個項目發揮作用。
要點:訓練你的模型,讓它盡可能接近真實世界中的圖像
重新思考問題
我決定嘗試新的東西。在我看來,訓練數據的奇怪外觀與我的模型在現實生活中可能看到的圖像之間存在明顯的脫節。我決定嘗試構建自己的數據集。
我一直在使用OpenCV,一個開源計算機視覺庫,我需要一個工程師一個解決方案,從屏幕上抓取一個圖像,然后調整大小并將圖像轉換成我的模型可以理解的NumPy數組。我用來轉換數據的方法如下:
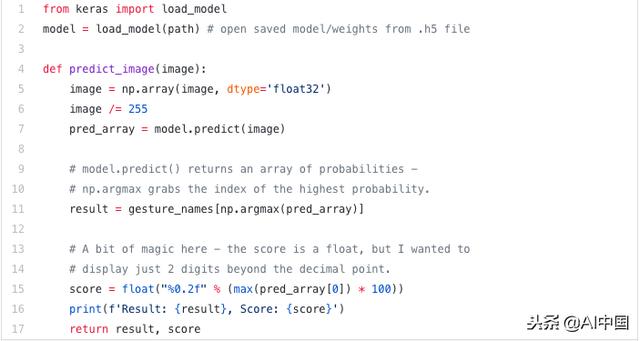
簡而言之,一旦您啟動并運行相機,您可以抓取框架,對其進行轉換,并從模型中獲取預測:
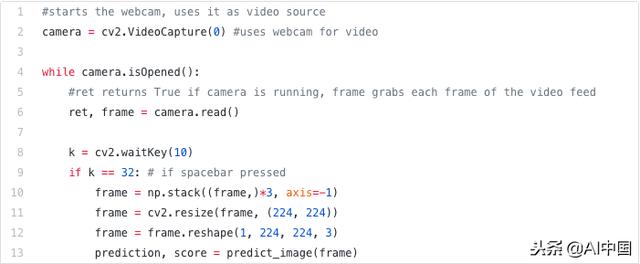
在網絡攝像頭和我的模型之間的連接管道取得了巨大成功。我開始思考什么是理想的圖像,輸入到我的模型之中。一個明顯的障礙是很難將感興趣的區域(在我們的例子中,一只手)與背景區分開來。
提取手勢
我采用的方法是任何熟悉Photoshop的人都熟悉的方法- 背景減法。從本質上講,如果你在你的手進入場景中先拍了一張照片,你可以創建一個“蒙版”,除了你的手之外,它將刪除新圖像中的所有內容。

背景掩蔽和二進制圖像閾值
一旦我從我的圖像中減去背景,然后我使用二進制閾值使目標手勢完全變白,背景完全變黑。我選擇這種方法有兩個原因:它使手的輪廓清晰明了,這使得模型更容易在不同膚色的用戶之間進行推廣。這創造了我最終訓練模型的照片“輪廓”般的照片。
構建新數據集
現在我可以準確地檢測到我的手中的圖像,我決定嘗試新的東西。我的舊模型沒有很好地概括,我的最終目標是建立一個能夠實時識別我的手勢的模型- 所以我決定建立自己的數據集!
我選擇專注于5個手勢:

我策略性地選擇了4個手勢,這些手勢也包含在Kaggle數據集中,所以我可以在以后對這些圖像交叉驗證我的模型。
從這里開始,我通過設置我的網絡攝像頭來構建數據集,并在OpenCV中創建一個點擊綁定來捕獲和保存具有唯一文件名的圖像。我試圖改變幀中手勢的位置和大小,這樣我的模型就會更完善。很快,我建立了一個每個包含550個輪廓圖像的數據集。是的,你沒看錯,我拍攝了超過2700張圖片。
訓練新模型
然后我使用Keras和TensorFlow構建了一個卷積神經網絡。我開始使用優秀的VGG-16預訓練模型,并在頂部添加了4個密集層和一個drop層。
然后,我采取了不尋常的步驟,選擇在我之前嘗試過的原始Kaggle數據集上交叉驗證我的模型。這是關鍵,如果我的新模型無法概括為之前沒有訓練過的其他人的手的圖像,那么它并不比我原來的模型好多少。
為了做到這一點,我將相同的變換應用到我應用于訓練數據的每個Kaggle圖像——背景減法和二進制閾值處理。這給了他們一個類似我的模型熟悉的“外觀”。
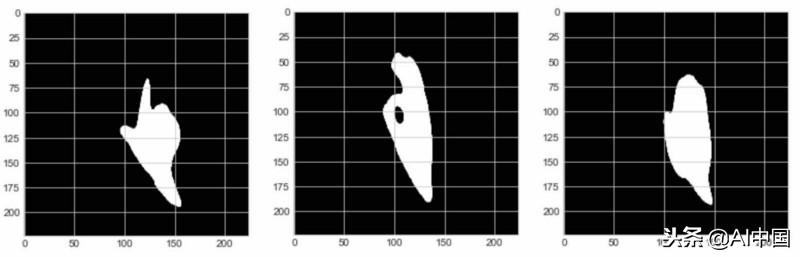
L,好吧,Palm轉換后的Kaggle數據集手勢
結果
該車型的性能超出了我的預期。它幾乎可以對測試集中的每個手勢進行正確分類,最終獲得98%的F1分數,以及98%的精確度和準確度分數。這是個好消息!
正如任何經驗豐富的研究人員所知道的那樣,在實驗室中表現良好而在現實生活中表現不佳的模型價值不大。在我的初始模型遇到同樣的失敗后,這個模型在實時手勢上表現良好。
智能家居集成
在測試我的模型之前,我想補充一點,我一直都是一個智能家居愛好者,我的愿景一直是用我的手勢控制我的Sonos(無線wifi音箱)和飛利浦Hue燈。為了方便地訪問Philips Hue和Sonos API,我分別使用了phue和SoCo庫。它們都非常簡單易用,如下所示:

使用SoCo通過Web API控制Sonos可以說更容易:

然后,我為不同的手勢創建了綁定,以便使用我的智能家居設備執行不同的操作:

當我最終實時測試我的模型時,我對結果非常滿意。模型在絕大部分時間都準確地預測了我的手勢,并且我能夠使用這些手勢來控制燈光和音樂。有關演示,請參閱:

來源:https://towardsdatascience.com/training-a-neural-network-to-detect-gestures-with-opencv-in-python-e09b0a12bdf1
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





