溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
隨著國內首款Cloud Native自研數據庫POLARDB精彩亮相ICDE 2018的同時,作為其核心支撐和使能平臺的PolarFS文件系統的相關論文"PolarFS: An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database"也被數據庫頂級會議VLDB 2018錄用。8月,阿里云數據庫團隊亮相于巴西里約召開的VLDB 2018,對整個業界起到了非常積極的影響。
VLDB(Very Large Data Base)和另外兩大數據庫會議SIGMOD、ICDE構成了數據庫領域的三個頂級會議。VLDB國際會議于1975在美國的弗雷明漢馬 (Framingham MA) 成立,是數據庫研究人員,供應商,參與者,應用開發者,以及用戶一年一度的頂級國際論壇。
VLDB主要由四個主題構成,分別為:Core Database Technology (核心數據庫技術),Infrastructure for Information Systems (基礎設施信息系統),Industrial Applications and Experience (工業應用與經驗) 以及 Experiments and Analyses(實驗和分析)。
從09年至今的數據分析來看,VLDB的論文接受率總體是比較低,其中,核心數據庫主題中的論文接受率大概為16.7%;基礎設施信息系統方面的論文接受率大約為17.9%;工業應用與經驗的論文接收比例近視為18%;而實驗和分析部分的為19%左右。由此可見,論文被VLDB接收不是件容易的事情,必須是創新性很高,貢獻很大的論文才有機會被錄用。
本文著重介紹PolarFS的系統設計與實現。
如同Oracle存在與之匹配的OCFS2,POLARDB作為存儲與計算分離結構的一款數據庫,PolarFS承擔著發揮POLARDB特性至關重要的角色。PolarFS是一款具有超低延遲和高可用能力的分布式文件系統,其采用了輕量的用戶空間網絡和I/O棧構建,而棄用了對應的內核棧,目的是充分發揮RDMA和NVMe SSD等新興硬件的潛力,極大地降低分布式非易失數據訪問的端到端延遲。目前,PolarFS的3副本跨節點寫入的訪問總延遲已經非常接近單機本地PCIe SSD的延遲水平,成功地使得POLARDB在分布式多副本架構下仍然能夠發揮出極致的性能。
針對數據庫設計分布式文件系統會帶來以下幾點好處:
計算節點和存儲節點可以使用不同的服務器硬件,并能獨立地進行定制。例如,計算節點不需要考慮存儲容量和內存容量的比例,其嚴重依賴于應用場景并且難以預測。
多個節點上的存儲資源能夠形成單一的存儲池,這能降低存儲空間碎化、節點間負載不均衡和空間浪費的風險,存儲容量和系統吞吐量也能容易地進行水平擴展。
數據庫應用的持久狀態可下移至分布式文件系統,由分布式存儲提供較高的數據可用性和可靠性。因此數據庫的高可用處理可被簡化,也利于數據庫實例在計算節點上靈活快速地遷移。
此外,云數據庫服務也會因此帶來額外的收益:
云數據庫可以采用虛擬計算環境如KVM等部署形態,其更安全、更易擴展和更易升級管理。
一些關鍵的數據庫特性,如一寫多讀實例、數據庫快照等可以通過分布式文件系統的數據共享、檢查點等技術而得以增強。
cdn.com/d089eef647b6416cfd15480ad2b6a40618d1be07.png">
系統組件
PolarFS系統內部主要分為兩層管理:
存儲資源的虛擬化管理,其負責為每個數據庫實例提供一個邏輯存儲空間。
文件系統元數據的管理,其負責在該邏輯存儲空間上實現文件管理,并負責文件并發訪問的同步和互斥。
PolarFS的系統結構如圖所示:
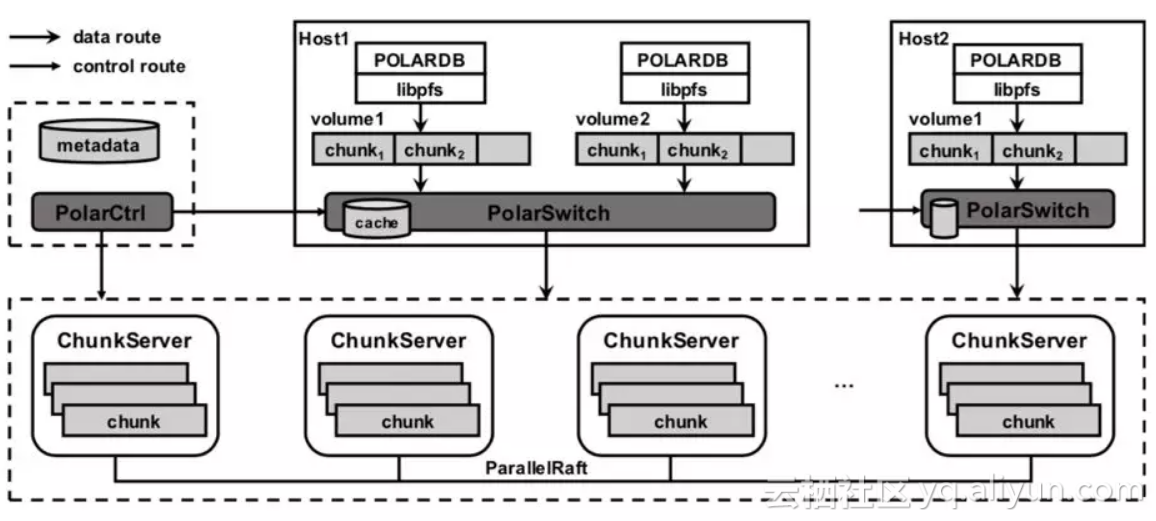
libpfs 是一個用戶空間文件系統庫,負責數據庫的I/O接入。
PolarSwitch 運行在計算節點上,用于轉發數據庫的I/O請求。
ChunkServer 部署在存儲節點上,用于處理I/O請求和節點內的存儲資源分布。
PolarCtrl 是系統的控制平面,它包含了一組實現為微服務的管理者,相應地Agent代理被部署到所有的計算和存儲節點上。
在進一步介紹各部分之前,我們先來了解下PolarFS存儲資源的組織方法:
PolarFS的存儲資源管理單元分為3層:Volume、Chunk、Block。
Volume
Volume是為每個數據庫提供的獨立邏輯存儲空間,其上建立了具體文件系統供此數據庫使用,其大小為10GB至100TB,可充分適用于典型云數據庫實例的容量要求。
在Volume上存放了具體文件系統實例的元數據。文件系統元數據包括inode、directory entry和空閑資源塊等對象。由于POLARDB采用的是共享文件存儲架構,我們在文件層面實現了文件系統元數據一致性,在每個文件系統中除DB建立的數據文件之外,我們還有用于元數據更新的Journal文件和一個Paxos文件。我們將文件系統元數據的更新首先記錄在Journal文件中,并基于Paxos文件以disk paxos算法實現多個實例對Journal文件的互斥寫訪問。
Chunk
每個Volume內部被劃分為多個Chunk,Chunk是數據分布的最小粒度,每個Chunk只存放于存儲節點的單個NVMe SSD盤上,其目的是利于數據高可靠和高可用的管理。典型的Chunk大小為10GB,這遠大于其他類似的系統,例如GFS的64MB。
這樣做的優勢是能夠有效地減少Volume的第一級映射元數據量的大小(例如,100TB的Volume只包含10K個映射項)。一方面,全局元數據的存放和管理會更容易;另一方面,這使得元數據可以方便地緩存在內存中,從而有效避免關鍵I/O路徑上的額外元數據訪問開銷。
但這樣做的潛在問題是,當上層數據庫應用出現區域級熱點訪問時,Chunk內熱點無法進一步打散,但是由于我們的每個存儲節點提供的Chunk數量往往遠大于節點數量(節點:Chunk在1:1000量級),PolarFS可支持Chunk的在線遷移,并且服務于大量數據庫實例,因此可以將不同實例的熱點以及同一實例跨Chunk的熱點分布到不同節點以獲得整體的負載均衡。
Block
在ChunkServer內,Chunk會被進一步劃分為多個Block,其典型大小為64KB。Blocks動態映射到Chunk 中來實現按需分配。Chunk至Block的映射信息由ChunkServer自行管理和保存,除數據Block之外,每個Chunk還包含一些額外Block用來實現Write Ahead Log。我們也將本地映射元數據全部緩存在ChunkServer的內存中,使得用戶數據的I/O訪問能夠全速推進。
下面我們詳細介紹PolarFS的各個系統組件。
libpfs
libpfs是一個輕量級的用戶空間庫,PolarFS采用了編譯到數據庫的形態,替換標準的文件系統接口,這使得全部的I/O路徑都在用戶空間中,數據處理在用戶空間完成,盡可能減少數據的拷貝。這樣做的目的是避免傳統文件系統從內核空間至用戶空間的消息傳遞開銷,尤其數據拷貝的開銷。這對于低延遲硬件的性能發揮尤為重要。
其提供了類Posix的文件系統接口(見下表),因而付出很小的修改代價即可完成數據庫的用戶空間化。

PolarSwitch
PolarSwitch是部署在計算節點的Daemon,它負責I/O請求映射到具體的后端節點。數據庫通過libpfs將I/O請求發送給PolarSwitch,每個請求包含了數據庫實例所在的Volume ID、起始偏移和長度。PolarSwitch將其劃分為對應的一到多個Chunk,并將請求發往Chunk所屬的ChunkServer完成訪問。
ChunkServer
ChunkServer部署在后端存儲節點上。一個存儲節點可以有多個ChunkServer。每個ChunkServer綁定到一個CPU核,并管理一個獨立的NVMe SSD盤,因此ChunkServer之間沒有資源爭搶。
ChunkServer負責Chunk內的資源映射和讀寫。每個Chunk都包括一個WAL,對Chunk的修改會先進Log再修改,保證數據的原子性和持久性。ChunkServer使用了3DXPoint SSD和普通NVMe SSD混合型WAL buffer,Log會優先存放到更快的3DXPoint SSD中。
ChunkServer會復制寫請求到對應的Chunk副本(其他ChunkServer)上,我們通過自己定義的Parallel Raft一致性協議來保證Chunk副本之間在各類故障狀況下數據正確同步和保障已Commit數據不丟失。
PolarCtrl
PolarCtrl是PolarFS集群的控制核心。其主要職責包括:
監控ChunkServer的健康狀況,確定哪些ChunkServer有權屬于PolarFS集群;
Volume創建及Chunk的布局管理(即Chunk分配到哪些ChunkServer);
Volume至Chunk的元數據信息維護;
向PolarSwitch推送元信息緩存更新;
監控Volume和Chunk的I/O性能;
周期性地發起副本內和副本間的CRC數據校驗。
PolarCtrl使用了一個關系數據庫云服務用于管理上述metadata。
分布式系統的設計有兩種范式:中心化和去中心化。中心化的系統包括GFS和HDFS,其包含單中心點,負責維護元數據和集群成員管理。這樣的系統實現相對簡單,但從可用性和擴展性的角度而言,單中心可能會成為全系統的瓶頸。去中心化的系統如Dynamo完全相反,節點間是對等關系,元數據被切分并冗余放置在所有的節點上。去中心化的系統被認為更可靠,但設計和實現會更復雜。
PolarFS在這兩種設計方式上做了一定權衡,采用了中心統控,局部自治的方式:PolarCtrl是一個中心化的master,其負責管理任務,如資源管理和處理控制平面的請求如創建Volume。ChunkServer負責Chunk內部映射的管理,以及Chunk間的數據復制。當ChunkServer彼此交互時,通過ParallelRaft一致性協議來處理故障并自動發起Leader選舉,這個過程無需PolarCtrl參與。
PolarCtrl服務由于不直接處理高并發的I/O流,其狀態更新頻率相對較低,因而可采用典型的多節點高可用架構來提供PolarCtrl服務的持續性,當PolarCtrl因崩潰恢復出現的短暫故障間隙,由于PolarSwitch的緩存以及ChunkServer數據平面的局部元數據管理和自主leader選舉的緣故,PolarFS能夠盡量保證絕大部分數據I/O仍能正常服務。
下面我們通過一個I/O的處理來說明各組件的互動過程。
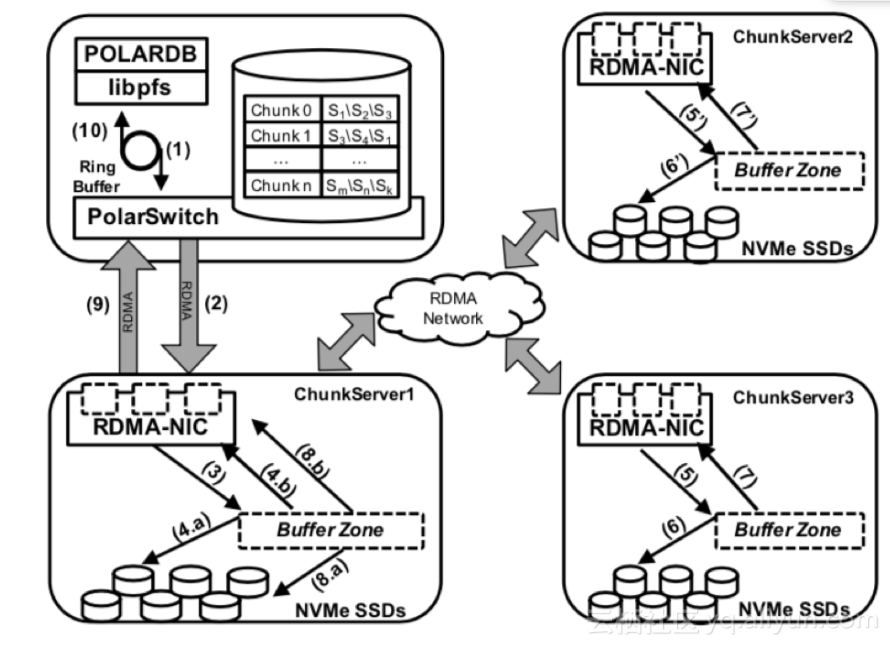
PolarFS執行寫I/O請求的過程如上圖所示:
POLARDB通過libpfs發送一個寫請求,經由ring buffer發送到PolarSwitch。
PolarSwitch根據本地緩存的元數據,將該請求發送至對應Chunk的主節點。
新寫請求到達后,主節點上的RDMA NIC將寫請求放到一個提前分好的buffer中,并將該請求項加到請求隊列。一個I/O輪詢線程不斷輪詢這個請求隊列,一旦發現新請求到來,它就立即開始處理。
請求通過SPDK寫到硬盤的日志block,并通過RDMA發向副本節點。這些操作都是異步調用,數據傳輸是并發進行的。
當副本請求到達副本節點,副本節點的RDMA NIC同樣會將其放到預分buffer中并加入到復制隊列。
副本節點上的I/O輪詢線程被觸發,請求通過SPDK異步地寫入Chunk的日志。
當副本節點的寫請求成功回調后,會通過RDMA向主節點發送一個應答響應。
主節點收到一個復制組中大多數節點的成功返回后,主節點通過SPDK將寫請求應用到數據塊上。
隨后,主節點通過RDMA向PolarSwitch返回。
PolarSwitch標記請求成功并通知上層的POLARDB。
ParallelRaft協議設計動機
一個產品級別的分布式存儲系統需要確保所有提交的修改在各種邊界情況下均不丟失。PolarFS在Chunk層面引入一致性協議來保證文件系統數據的可靠性和一致性。設計之初,從工程實現的成熟度考慮,我們選擇了Raft算法,但對于我們構建的超低延遲的高并發存儲系統而言,很快就遇到了一些坑。
Raft為了簡單性和協議的可理解性,采用了高度串行化的設計。日志在leader和follower上都不允許有空洞,其意味著所有log項會按照順序被follower確認、被leader提交并apply到所有副本上。因此當有大量并發寫請求執行時,會按順序依次提交。處于隊列尾部的請求,必需等待所有之前的請求已被持久化到硬盤并返回后才會被提交和返回,這增加了平均延遲也降低了吞吐量。我們發現當并發I/O深度從8升到32時,I/O吞吐量會降低一半。
Raft并不十分適用于多連接的在高并發環境。實際中leader和follower使用多條連接來傳送日志很常見。當一個鏈接阻塞或者變慢,log項到達follower的順序就會變亂,也即是說,一些次序靠后的log項會比次序靠前的log項先到。但是,Raft的follower必需按次序接收log項,這就意味著這些log項即使被記錄到硬盤也只能等到前面所有缺失的log項到達后才能返回。并且假如大多數follower都因一些缺失的項被阻塞時,leader也會出現卡頓。我們希望有一個更好的協議可以適應這樣的情形。
由于PolarFS之上運行的是Database事務處理系統,它們在數據庫邏輯層面的并行控制算法使得事務可以交錯或亂序執行的同時還能生成可串行化的結果。這些應用天然就需要容忍標準存儲語義可能出現的I/O亂序完成情況,并由應用自身進一步保證數據一致性。因此我們可以利用這一特點,在PolarFS中依照存儲語義放開Raft一致性協議的某些約束,從而獲得一種更適合高I/O并發能力發揮的一致性協議。
我們在Raft的基礎上,提供了一種改進型的一致性協議ParallelRaft。ParallelRaft的結構與Raft一致,只是放開了其嚴格有序化的約束。
亂序日志復制
Raft通過兩個方面保障串行化:
當leader發送一個log項給follower,follower需要返回ack來確認該log項已經被收到且記錄,同時也隱式地表明所有之前的log項均已收到且保存完畢。
當leader提交一個log項并廣播至所有follower,它也同時確認了所有之前的log項都已被提交了。ParallelRaft打破了這兩個限制,并讓這些步驟可亂序執行。
因此,ParallelRaft與Raft最根本的不同在于,當某個entry提交成功時,并不意味著之前的所有entry都已成功提交。因此我們需要保證:
在這種情況下,單個存儲的狀態不會違反存儲語義的正確性;
所有已提交的entry在各種邊界情況下均不會丟失;
有了這兩點,結合數據庫或其他應用普遍存在的對存儲I/O亂序完成的默認容忍能力,就可以保證它們在PolarFS上的正常運轉,并獲得PolarFS提供的數據可靠性。
ParallelRaft的亂序執行遵循如下原則:
當寫入的Log項彼此的存儲范圍沒有交疊,那么就認為Log項無沖突可以亂序執行;
否則,沖突的Log項將按照寫入次序依次完成。
容易知道,依照此原則完成的I/O不會違反傳統存儲語義的正確性。
接下來我們來看log的ack-commit-apply環節是如何因此得到優化并且保持一致性的。
亂序確認(ack):當收到來自leader的一個log項后,Raft follower會在它及其所有之前的log項都持久化后,才發送ack。ParallelRaft則不同,任何log entry成功持久化后均能立即返回,這樣就優化了系統的平均延遲。
亂序提交(commit):Raft leader串行提交log項,一個log項只有之前的所有項提交之后才能提交。而ParallelRaft的leader在一個log項的多數副本已經確認之后即可提交。這符合存儲系統的語義,例如,NVMe SSD驅動并不檢查讀寫命令的LBA來保證并行命令的次序,對命令的完成次序也沒有任何保證。
亂序應用(apply):對于Raft,所有log項都按嚴格的次序apply,因此所有副本的數據文件都是一致的。但是,ParallelRaft由于亂序的確認和提交,各副本的log都可能在不同位置出現空洞,這里的挑戰是,如何保證前面log項有缺失時,安全地apply一個log項?
ParallelRaft引入了一種新型的數據結構look behind buffer來解決apply中的問題。
ParallelRaft的每個log項都附帶有一個look behind buffer。look behind buffer存放了前N個log項修改的LBA摘要信息。
look behind buffer的作用就像log空洞上架設的橋梁,N表示橋梁的寬度,也就是允許單個空洞的最大長度,N的具體取值可根據網絡連續缺失log項的概率大小,靜態地調整為合適的值,以保證log橋梁的連續性。
通過look behind buffer,follower能夠知道一個log項是否沖突,也就是說是否有缺失的前序log項修改了范圍重疊的LBAs。沒有沖突的log項能被安全apply。如有沖突,它們會被加到一個pending list,待之前缺失的沖突log項apply之后,才會接著apply。
通過上述的異步ack、異步commit和異步apply,PolarFS的chunk log entry的寫入和提交避免了次序造成的額外等待時間,從而有效縮減了高并發3副本寫的平均時延。
ParallelRaft協議正確性
我們在ParallelRaft的設計中,確保了Raft協議關鍵特性不丟失,從而保障了新協議的正確性。
ParallelRaft協議的設計繼承了原有Raft協議的Election Safety、 Leader Append-Only及Log Matching 特性。
沖突log會以嚴格的次序提交,因此協議的State Machine Safety特性能夠最終得以保證。
我們在Leader選舉階段額外引入了一個Merge階段,填補Leader中log的空洞,能夠有效保障協議的Leader Completeness特性。
文件系統多副本高速寫入——數據庫單實例的超高TPS,數據高可靠
PolarFS設計中采用了如下技術以充分發揮I/O性能:
PolarFS采用了綁定CPU的單線程有限狀態機的方式處理I/O,避免了多線程I/O pipeline方式的上下文切換開銷。
PolarFS優化了內存的分配,采用MemoryPool減少內存對象構造和析構的開銷,采用巨頁來降低分頁和TLB更新的開銷。
PolarFS通過中心加局部自治的結構,所有元數據均緩存在系統各部件的內存中,基本完全避免了額外的元數據I/O。
PolarFS采用了全用戶空間I/O棧,包括RDMA和SPDK,避免了內核網絡棧和存儲棧的開銷。
在相同硬件環境下的對比測試,PolarFS中數據塊3副本寫入性能接近于單副本本地SSD的延遲性能。從而在保障數據可靠性的同時,極大地提升POLARDB的單實例TPS性能。
下圖是我們采用Sysbench對不同負載進行的初步測試比較。
POLARDB on PolarFS
Alibaba MySQL Cloud Service RDS
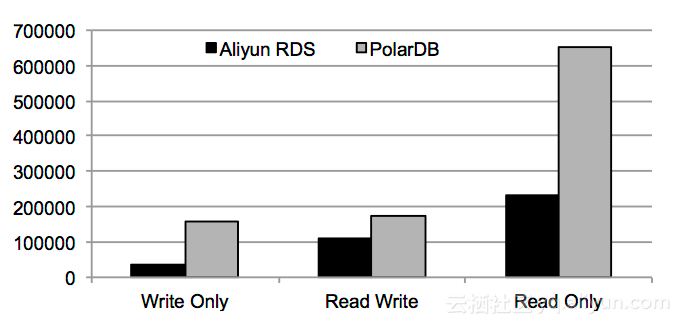
用例負載:OLTP,只讀、只寫(update : delete : insert = 2:1:1)、讀寫混合(read : write = 7:2)。數據庫測試集數據量為500GB。
可以發現POLARDB在PolarFS下取得了較好的性能,PolarFS同時支持了POLARDB的高TPS和數據的高可靠性。
文件系統共享訪問——寫多讀的數據庫QPS強擴展,數據庫實例的Failover
PolarFS是共享訪問的分布式文件系統,每個文件系統實例都有相應的Journal文件和與之對應的Paxos文件。Journal文件記錄了metadata的修改歷史,是共享實例之間元數據同步的中心。Journal文件邏輯上是一個固定大小的循環buffer。PolarFS會根據水位來回收journal。Paxos文件基于Disk Paxos實現了分布式互斥鎖。
由于journal對于PolarFS非常關鍵,它們的修改必需被Paxos互斥鎖保護。如果一個節點希望在journal中追加項,其必需使用DiskPaxos算法來獲取Paxos文件中的鎖。通常,鎖的使用者會在記錄持久化后馬上釋放鎖。但是一些故障情況下使用者不釋放鎖。為此在Paxos互斥鎖上分配有一個租約lease。其他競爭者可以重啟競爭過程。當PolarFS當節點開始同步其他節點修改的元數據時,它從上次掃描的位置掃描到journal末尾,將新entry更新到memory cache中。
下圖展示了文件系統元數據更新和同步的過程。
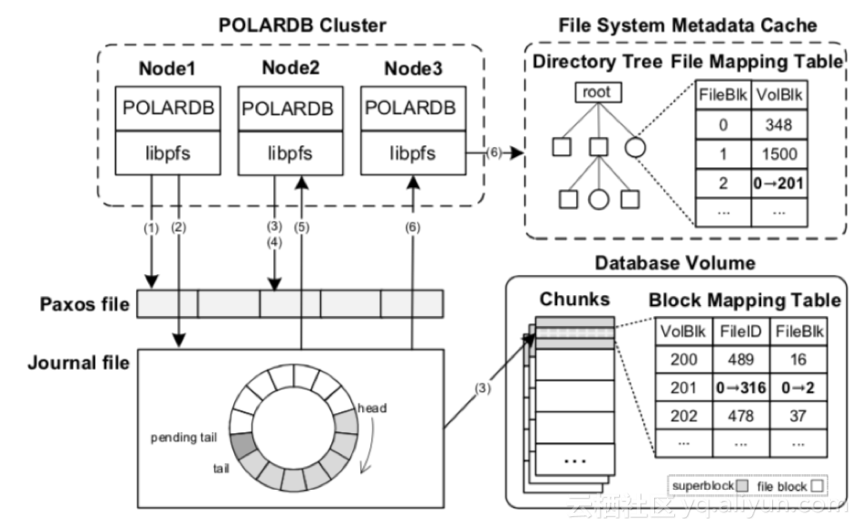
節點1分配塊201至文件316后,請求互斥鎖,并獲得。
Node 1開始記錄事務至journal中。最后寫入項標記為pending tail。當所有的項記錄之后,pending tail變成journal的有效tail。
Node1更新superblock,記錄修改的元數據。與此同時,node2嘗試獲取node1擁有的互斥鎖,Node2會失敗重試。
Node2在Node1釋放lock后拿到鎖,但journal中node1追加的新項決定了node2的本地元數據是過時的。
Node2掃描新項后釋放lock。然后node2回滾未記錄的事務并更新本地metadata。最后Node2進行事務重試。
Node3開始自動同步元數據,它只需要load增量項并在它本地重放即可。
PolarFS的上述共享機制非常適合POLARDB一寫多讀的典型應用擴展模式。一寫多讀模式下沒有鎖爭用開銷,只讀實例可以通過原子I/O無鎖獲取Journal信息,從而使得POLARDB可以提供近線性的QPS性能擴展。
由于PolarFS支持了基本的多寫一致性保障,當可寫實例出現故障時,POLARDB能夠方便地將只讀實例升級為可寫實例,而不必擔心底層存儲產生不一致問題,因而方便地提供了數據庫實例Failover的功能。
文件系統級快照——POLARDB的瞬時邏輯備份
對于百TB級超大數據庫實例的備份而言,數據庫快照是必須支持的功能。
PolarFS采用了自有的專利快照技術,能夠基于位于底層的多個ChunkServer的局部快照,構建Volume上的統一的文件系統即時映像。POLARDB利用自身數據庫的日志,能夠基于此文件系統映像快速構建出此具體時點的數據庫快照,從而有效支持數據庫備份和數據分析的需求。
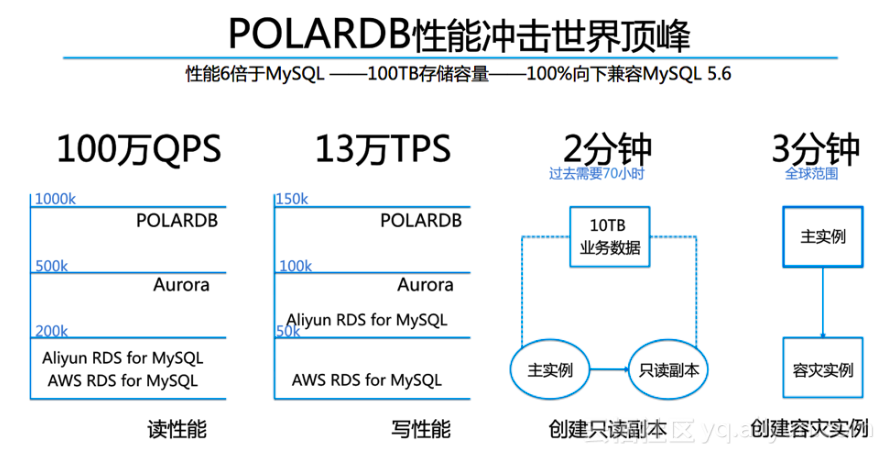
可以發現,POLARDB的高性能、強擴展、輕運維等具備競爭優勢的優異特性,與PolarFS的緊密協作息息相關,PolarFS發揮了強大的使能作用。
PolarFS是一個專為云數據庫而設計的分布式文件系統,其能夠支持跨節點高可靠性同時提供極致的性能。PolarFS采用了新興硬件和先進的優化技術,例如OS-bypass和zero-copy,使得PolarFS中數據塊3副本寫入性能接近于單副本本地SSD的延遲性能。PolarFS在用戶空間實現了POSIX兼容接口,使得POLARDB等數據庫服務能夠盡量少地修改即可獲得PolarFS帶來的高性能的優勢。
可以看到,面向數據庫的專有文件系統,是保障未來數據庫技術領先的一個不可或缺的關鍵一環。數據庫內核技術的進展及其專有文件系統的使能,是一個相輔相成的演進過程,二者的結合也會隨著當今系統技術的進步而愈加緊密。
未來我們將探索NVM和FPGA等新硬件,以期通過文件系統與數據庫的深度結合來進一步優化POLARDB數據庫的性能。
作者:鳴嵩,弘然,明書,旭危,寧進,文義,韓逸,翊云
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





