溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Hadoop2.7.5+Spark2.2.1分布式集群怎么搭建”,在日常操作中,相信很多人在Hadoop2.7.5+Spark2.2.1分布式集群怎么搭建問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Hadoop2.7.5+Spark2.2.1分布式集群怎么搭建”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
一、運行環境
CentOS 6.5
Spark 2.2.1
Hadoop 2.7.5
Java JDK 1.8
Scala 2.12.5
二、節點IP及角色對應關系
| 節點名 | IP | Spark角色 | hadoop角色 |
| hyw-spark-1 | 10.39.60.221 | master、worker | master |
|
hyw-spark-2 | 10.39.60.222 | worker | slave |
| hyw-spark-3 | 10.39.60.223 | worker | slave |
三、基礎環境配置
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
四、jdk安裝(在hadoop用戶下執行)
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
五、scala安裝(在hadoop用戶下執行)
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
六、hadoop集群安裝(在hadoop用戶下執行)
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hyw-spark-1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
6.4.4、$vim hdfs-site.xml
將文件末尾修改為
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
6.4.5、$vim mapred-site.xml
將文件末尾 修改為
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6.4.6、$vim yarn-site.xml
將文件末尾修改為
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hyw-spark-1</value>
</property>
</configuration>
6.4.7、$vim slaves
添加如下內容
hyw-spark-1
hyw-spark-2
hyw-spark-3
6.4.8、拷貝文件到slave節點(總共7個文件)
$scp hadoop-env.sh yarn-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slave hadoop@hyw-spark-2:/usr/local/spark/etc/spark/
$scp hadoop-env.sh yarn-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slave hadoop@hyw-spark-3:/usr/local/spark/etc/spark/
6.5、啟動hadoop集群
6.5.1、格式化NameNode
在Master節點上,執行如下命令
$hdfs namenode -format
成功的話,會看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若為 “Exitting with status 1” 則是出錯。
6.5.2、啟動HDFS(NameNode、DataNode)
在Master節點上,執行如下命令
$start-dfs.sh
使用jps命令在Master上可以看到如下進程:
8757 SecondaryNameNode
7862 DataNode
7723 NameNode
8939 Jps
使用jps命令在兩個Slave上可以看到如下進程:
7556 Jps
7486 DataNode
6.5.3啟動Yarn(ResourceManager 、NodeManager)
在Master節點上,執行如下命令
$start-yarn.sh
使用jps命令在Master上可以看到如下進程:
9410 Jps
8757 SecondaryNameNode
8997 ResourceManager
7862 DataNode
9112 NodeManager
7723 NameNode
使用jps命令在兩個Slave上可以看到如下進程:
7718 Jps
7607 NodeManager
7486 DataNode
6.5.4通過瀏覽器查看HDFS信息
瀏覽器訪問http://10.39.60.221:50070,出現如下界面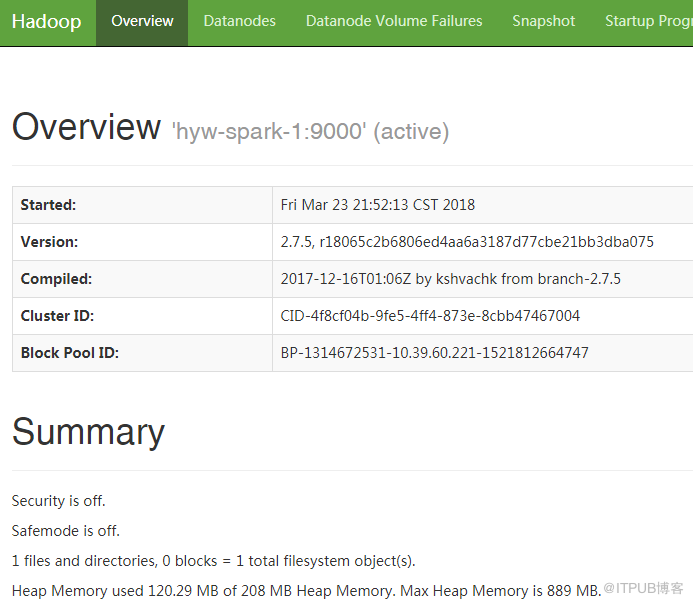
七、spark安裝(在hadoop用戶下執行)
7.1、下載文件到/opt目錄下,解壓文件到/usr/local
$cd /opt
$sudo tar -xzvf spark-2.2.1-bin-hadoop2.7.tgz -C /usr/local
$cd /usr/local
$sudo mv spark-2.2.1-bin-hadoop2.7/ spark
$sudo chown -R hadoop:hadoop spark
7.2、設置環境變量
$sudo vi /etc/profile
添加如下內容
export SPARK_HOME=/usr/local/spark
PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
更新環境變量
source /etc/profile
7.3、配置文件修改
以下操作均在master節點配置,配置完成后scp到slave節點
$cd /usr/local/spark/conf
7.3.1、$cp spark-env.sh.template spark-env.sh
$vim spark-env.sh
添加如下內容
export JAVA_HOME=/opt/jdk1.8
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SCALA_HOME=/usr/local/scala
export SPARK_MASTER_IP=10.39.60.221
export SPARK_WORKER_MEMORY=1g
7.3.2、$cp slaves.template slaves
$vim slaves
添加如下內容
hyw-spark-1
hyw-spark-2
hyw-spark-3
7.3.3拷貝文件到slave節點
$scp -r spark-env.sh slaves hadoop@hyw-spark-2:/usr/local/spark/conf/
$scp -r spark-env.sh slaves hadoop@hyw-spark-3:/usr/local/spark/conf/
7.4、啟動spark
7.4.1、啟動Master節點
Master節點上,執行如下命令:
$start-master.sh
使用jps命令在master節點上可以看到如下進程:
10016 Jps
8757 SecondaryNameNode
8997 ResourceManager
7862 DataNode
9112 NodeManager
9832 Master
7723 NameNode
7.4.2、啟動worker節點
Master節點上,執行如下命令:
$start-slaves.sh
使用jps命令在三個worker節點上可以看到如下進程:
7971 Worker
7486 DataNode
8030 Jps
7.5、通過瀏覽器查看spark信息
瀏覽器訪問http://10.39.60.221:8080,出現如下界面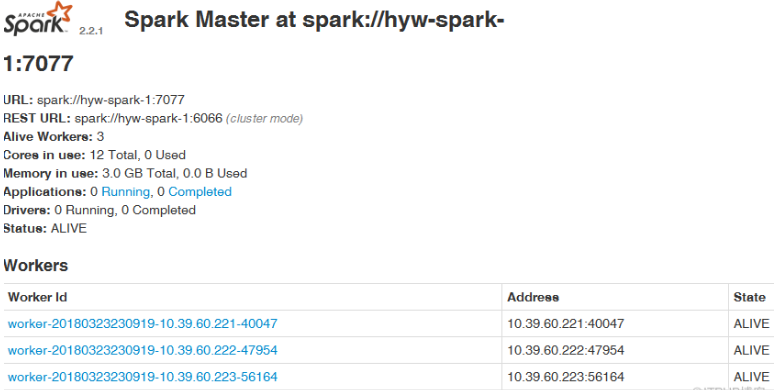
到此,關于“Hadoop2.7.5+Spark2.2.1分布式集群怎么搭建”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





