溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“hadoop分布式集群的搭建過程”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“hadoop分布式集群的搭建過程”吧!
[hadoop@hadoop01 home]$ put c:/hadoop-2.6.5-centos-6.7.tar.gz
[hadoop@hadoop01 home]$tar -zxvf hadoop-2.6.5-centos-6.7.tar.gz -C /home/hadoop/apps
[hadoop@hadoop01 home]$ cd /home/hadoop/apps/hadoop-2.6.5/hadoop/etc
這里需要修改6個配置文件:
hadoop-env.sh:
加入:export JAVA_HOME=/usr/java/jdk1.8.0_73
core-site.xml:
<property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/hadoopdata</value> </property>
hdfs-site.xml:
<property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/hadoopdata/name</value> <description>為了保證元數據的安全一般配置多個不同目錄</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/hadoopdata/data</value> <description>datanode 的數據存儲目錄</description> </property> <property> <name>dfs.replication</name> <value>2</value> <description>HDFS 的數據塊的副本存儲個數</description> </property> <property> <name>dfs.secondary.http.address</name> <value>hadoop02:50090</value> <description>secondarynamenode 運行節點的信息,和 namenode 不同節點</description> </property>
mapred-site.xml:
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
yarn-site.xml:
<property> <name>yarn.resourcemanager.hostname</name> <value>hadoop03</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>YARN 集群為 MapReduce 程序提供的 shuffle 服務</description> </property>
slaves:
hadoop01 hadoop02 hadoop03
[hadoop@hadoop01 etc]$scp -r hadoop-2.6.5 hadoop02:$PWD
[hadoop@hadoop01 etc]$scp -r hadoop-2.6.5 hadoop03:$PWD
[hadoop@hadoop01 etc]$sudo vim /etc/profile:
加入:
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.5/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[hadoop@hadoop01 etc]$source /etc/profile
[hadoop@hadoop01 etc]$hadoop namenode -format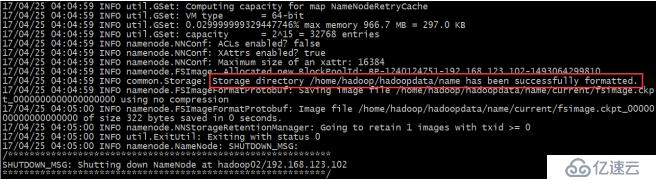
[hadoop@hadoop01 etc]$start-dfs.sh
[hadoop@hadoop01 etc]$sbin/start-yarn.sh
補充:
hdfs的web界面是: http://hadoop01:50070
yarn的web界面是: http://hadoop03:8088
查看集群的狀態:hdfs dfsadmin -report
1、啟動 namenode 或者 datenode
sbin/hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start secondarynamenode
2、啟動 yarn nodemanager
sbin/yarn-daemon.sh start nodemanager
sbin/yarn-daemon.sh start resourcemanager
感謝各位的閱讀,以上就是“hadoop分布式集群的搭建過程”的內容了,經過本文的學習后,相信大家對hadoop分布式集群的搭建過程這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





