溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹SparkSQL基礎知識都有哪些,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。

一個sql 過來 解析成unresolved,只拿出來字段名和表名 但是不知道字段名和表名在哪個位置 需要通過Schema 確定表的位置等信息, 生成邏輯執行計劃,Logical,知道數據從哪里來了 通過一些列優化過濾生成物理執行計劃Physical 最后把物理執行計劃放到spark集群上運行

Spark SQL就是寫SQL,這是錯誤的觀點 Spark SQL不是SQL,超出SQL,因為SQL是其一部分 Spark SQL 是處理結構化數據的,只是Spark中的一個模塊 Spark SQL 與 Hive on Spark 不是一個東西 Spark SQL 是spark里面的 Hive on Spark 的功能是比Spark SQL多的 Hive on Spark 穩定性不是很好
關系數據庫集群成本很高,還是有限的 SQL : schema + file 使用sql的前提就是有schema ,作用到文件上去 hive是進程的 hive2.0 默認引擎是Tez Hive on Spark 就是把hive執行引擎改成spark
mr spark Tez
spark sql 可以跨數據源進行join,例如hdfs與mysql里表內容join Spark SQL運行可以不用hive,只要你連接到hive的metastore就可以
hiveserver2開啟可以用JDBC或者ODBC直接連接

spark-sql 與 spark-shell ,thriftserver thriftserver對應hive里面的hiveserver2
./beeline -u jdbc:hive2://localhost:10000 -n root
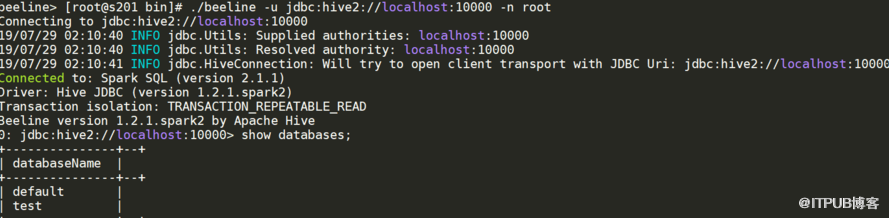
spark-shell、spark-sql 都是是一個獨立的 spark application, 啟動幾個就要幾個application,非常耗資源 用thriftserver,無論啟動多少個客戶端(beeline)連接在一個thriftserver, 是一個獨立的spark application, 后面不用在重新申請資源。前一個beeline緩存的,下一個beeline也可以用 用thriftserver,可在ui看執行計劃,優化有優勢
這個要起來,要不spark-shell, spark-sql,連接不上,這個跟hive一樣

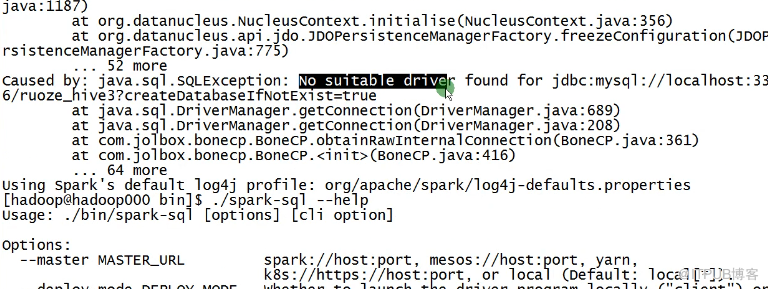
spark-shell --master local[2] --jars /soft/hive/lib/mysql-connector-java-8.0.12.jar 這樣啟動不起來 你可以試試把mysql-connector-java-8.0.12.jar 放到spark的jars里

關于SparkSQL基礎知識都有哪些就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





