溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“SparkSQL指的是什么”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“SparkSQL指的是什么”這篇文章吧。
一、 Spark SQL介紹
Spark SQL是Apache Spark's的一個模塊,用來處理結構化數據,1.0后產生;SQL語句主要體現在關系型數據庫上,大數據中基于Hadoop的SQL有Hive(SQL on Hadoop)但是MapReduce計算過程中大量的磁盤落地過程消耗了大量I/O,降低運行效率,簡單說就是穩定性高,計算慢,離線批處理的框架,因此其他的SQL on Hadoop工具產生。
SQL on Hadoop
Hive -- 把HQL語句轉換MapReduce作業 提交到Yarn執行(元數據重要性)
Impala -- 開源的交互式SQL查詢引擎,基于內存處理
Presto -- 分布式SQL查詢引擎
Shark -- SQL語句翻譯Spark作業,Hive跑在Spark之上,依賴Hive與Hive兼容性差
Drill -- 查詢引擎包括SQL/FILE/HDFS/S3
Phoenix -- 基于Hbase上的SQL引擎
Hive on SQL是社區發展另外一個路線,屬于Hive發展計劃,把Spark作為Hive的執行引擎;之前我們說的HIve作業跑在Hadoop的MapReduce上的;現在Hive不受限于一個引擎,可以采用MapReduce、Tez、Spark等引擎。
二、 Spark SQL特性
集成性-SQL查詢與應用程序對接
統一的數據訪問-連接各種數據源(Hive, Avro, Parquet, ORC, JSON, and JDBC)
與Hive的集成性,不需要Hive,使用Hive存在Metastores即可或者使用Hive-site文件
通過JDBC和ODBC連接,start-thriftserver底層走的也是Thrift協議(Hive_server2底層基于Thrift協議,)
Spark SQL不僅僅是SQL,遠超出SQL
三、 Spark SQL優勢
A:內存列存儲(In-Memory Columnar Storage)
Spark SQL的表數據在內存中的存儲采用是內存列式存儲,而不是原生態JVM對象存儲方式。
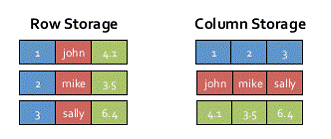
Spark SQL列式存儲將數據類型相同列采用原生數組來存儲,將Hive支持的復雜數據類型(如array、map等)先序化后并接成一個字節數組來存儲。這樣,每個列創建一個JVM對象,從而導致可以快速的GC和緊湊的數據存儲;額外的,還可以使用低廉CPU開銷的高效壓縮方法(如字典編碼、行長度編碼等壓縮方法)降低內存開銷;更有趣的是,對于分析查詢中頻繁使用的聚合特定列,性能會得到很大的提高,原因就是這些列的數據放在一起,更容易讀入內存進行計算
B:字節碼生成技術(bytecode generation,即CG)
數據庫查詢中有一個昂貴的操作是查詢語句中的表達式,主要是由于JVM的內存模型引起的。比如如下一個查詢:
中有一個昂在這個查詢里,如果采用通用的SQL語法途徑去處理,會先生成一個表達式樹。
select a+b from table

在物理處理這個表達式樹的時候,將會如圖所示的7個步驟
1. 調用虛函數Add.eval(),需要確認Add兩邊的數據類型
2. 調用虛函數a.eval(),需要確認a的數據類型
3. 確定a的數據類型是Int,裝箱
4. 調用虛函數b.eval(),需要確認b的數據類型
5. 確定b的數據類型是Int,裝箱
6. 調用Int類型的Add
7. 返回裝箱后的計算結果
C:Scala代碼優化
...............
四、 Spark SQL運行架構
Catalyst就SparkSQL核心部分,性能的優劣影響整體的性能,由于發展時間短,虛線部分是以后版本要實現功能,實現部分是已經實現功能。
Unresolved Logical Plan:未解析的邏輯執行計劃
Schema Catalog:元數據管理套用Unresolved Logical Plan生成Logical Plan
Logical Plan:生成邏輯執行計劃
Optimized Logical Plan:對生生成的Logical Plan進行優化,生成物理邏計劃
Physical Plans:物理邏輯計劃,可能是多個,根據Cost Model生成最佳的物理邏輯化
以上是“SparkSQL指的是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





