溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么理解Oracle集群因子”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
集群因子(ClusteringFactor)是如果通過一個索引掃描一張表,需要訪問的表的數據塊的數量。衡量通過索引掃描,通過ROWID 回表的時候,物理讀有多大。
集群因子是索引與它所基于的表相比較而得出的有序性度量,它用于檢查在索引訪問之后執行的表查找的成本(將集群因子與選擇性相乘即可得到該操作的成本)。集群因子記錄在掃描索引時將讀取的塊數量。
如果使用的索引具有較大的集群因子,則必須訪問更多的表數據塊才可以獲得每個索引塊中的行(因為鄰近行位于不同的塊中)。
如果集群因子接近于表中的塊數量,則表示索引適當排序;但是,如果集群因子接近于表中的行數量,則表示索引沒有適當排序
(1) 掃描一個索引;
(2) 比較某行的ROWID和前一行的ROWID,如果這兩個ROWID不屬于同一個數據塊,那么ClusteringFactor增加1;
(3) 整個索引掃描完畢后,就得到了該索引的ClusteringFactor。
如果ClusteringFactor接近于表存儲的塊數,說明這張表是按照索引字段的順序存儲的。
如果集群因子接近于行的數量,那說明這張表不是按索引字段順序存儲的。
在計算索引訪問成本時,集群因子十分有用。Clustering Factor乘以選擇性參數(selectivity)就是訪問索引的開銷。
如果這個統計數據不能反映出索引的真實情況,那么可能會造成優化器錯誤地選擇執行計劃。另外,如果某張表上的大多數訪問是按照某個索引做索引掃描,那么將該表的數據按照索引字段的順序重新組織,可以提高該表的訪問性能。
集群因子對執行范圍掃描的SQL語句產生影響,如果集群因子接近數據塊數量,滿足查詢要求的數據塊的數量就可以少很多,這樣也增加了數據塊已經存在于內存中的可能性。相對于數據塊數量大很多的集群因子,基于索引列的范圍查詢需要掃描更多的數據塊。
我們知道可以通過dbms_rowid.rowid_block_number(rowid)找到記錄對應的block 號。索引中記錄了rowid,因此oracle 就可以根據索引中的rowid來判斷記錄是否是在同一個block 中。
舉個例子,比如說索引中有a,b,c,d,e五個記錄,首先比較a,b 是否在同一個block,如果不在同一個block 那么Clustering Factor +1,然后繼續比較b,c 同理,如果b,c 不在同一個block,那么Clustering Factor+1,這樣一直進行下去,直到比較了所有的記錄。
根據算法我們就可以知道clustering factor 的值介于block 數和表行數之間。如果clustering factor 接近block 數,說明表的存儲和索引存儲排序接近,也就是說表中的記錄很有序,這樣在做index range scan 的時候能,讀取少量的data block 就能得到我們想要的數據,代價比較小。如果clustering factor 接近表記錄數,說明表的存儲和索引排序差異很大,在做index range scan 的時候,會額外讀取多個block,因為表記錄分散,代價較高。
Clustering_factor列是user_indexes,dba_indexes視圖中的一列,該列反應了數據相對已索引的列是否顯得有序。
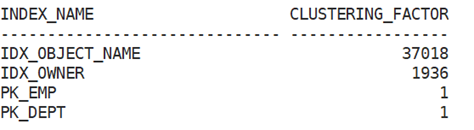 SQL> select index_name,CLUSTERING_FACTOR from user_indexes;
SQL> select index_name,CLUSTERING_FACTOR from user_indexes;
實驗參考
https://blog.csdn.net/zhaoyangjian724/article/details/71082379
“怎么理解Oracle集群因子”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





