溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一條 SQL 在數據庫中是如何執行的呢 ?相信很多人都會對這個問題比較感興趣。但是,感興趣歸感興趣,你得去追呀,還臆想著她主動到你懷里來 ?
一條 SQL 在數據庫中的生命周期涵蓋了 SQL 的詞法解析、語法解析、權限檢查、查詢優化、SQL執行等一系列的步驟,是一個相當復雜的過程,不亞于你追她的艱苦歷程,不是只言片語就說的完的。但是,大家先別緊張,上面說的那些了,今天一個也不講,氣不氣 ?
今天和大家一起來看一下 SQL 生命周期中比較有意思的一個環節
給定一條 SQL,如何提取其中的 where 條件 ??
where 條件中的每個子條件,在 SQL 執行的過程中有分別起著什么樣的作用 ?
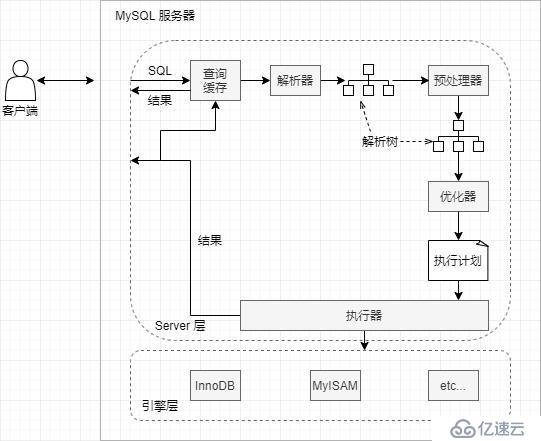
這是 MySQL 數據庫中 SQL 的執行流程,其他數據庫應該類似
關系型數據庫中,數據組織涉及到兩個最基本的結構:表與索引。表中存儲的是完整數據記錄,分為堆表和聚簇索引表;堆表中所有的記錄無序存儲,聚簇索引表中所有的記錄則是按照記錄主鍵進行排序存儲。索引中存儲的是完整記錄的一個子集,用于加速記錄的查詢速度,索引的組織形式,一般均為B+樹結構
MySQL 的 InnoDB 采用的是聚簇索引表,數據記錄和索引是一起存儲的,類似如下
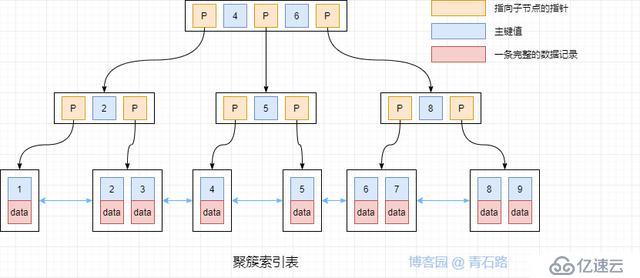
InnoDB 二級索引(非聚簇索引)的結構與聚集索引的結構基本相同,只是葉子節點有些許差別,二級索引的葉子節點存的是索引值 + 主鍵值,而聚簇索引的葉子節點存的是索引值 + 完整的數據記錄,所以通過二級索引查找的過程是先找到該索引值對應的聚集索引的值,然后再通過該聚簇索引值到聚簇索引樹上查找對應的完整數據記錄,這個過程稱為回表!當然也有不需要回表的情況,這里就不展開了
Oracle、DB2、PostgreSQL,MySQL 的 MyISAM 引擎,采用的是堆表形式來存儲數據,索引和數據是分開存儲的,類似如下
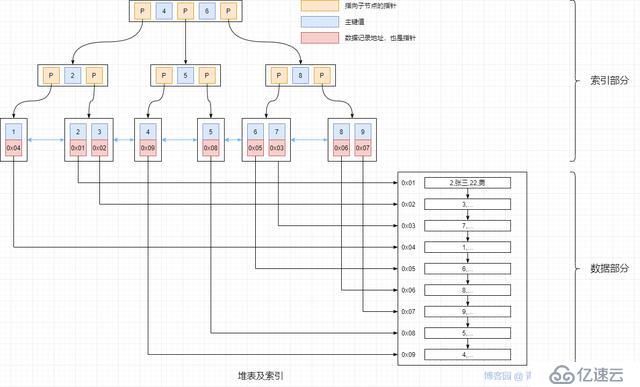
堆表結構中的聚簇索引和二級索引基本就沒什么區別了,可以簡單的認為聚簇索引的結構和二級索引中的唯一索引的結構是一樣的
其實表結構采用何種形式并不重要,因為下面講的內容在任何表結構中均適用
建表 tbl_test 并初始化數據
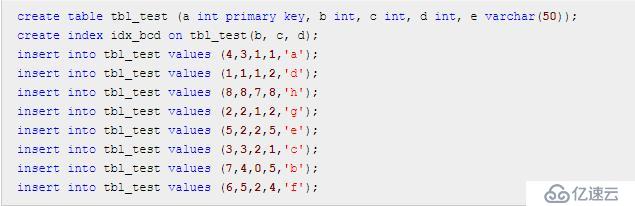
假設數據數據結構是堆表形式,那么 idx_bcd 索引的結構圖大致如下(聚簇索引不一樣,類比一下應該可以畫出來,我就偷個懶不畫了)
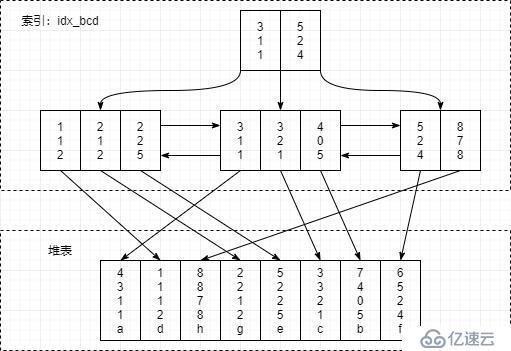
組合索引 idx_bcd 上有 b,c,d 三個字段,不包括 a,e 字段,它是先按照 b 字段排序,b 字段相同,則按照 c 字段排序,以此類推
針對上表,我們分析下 SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a'; 此 SQL 中 WHERE 條件用到了 b,c,d,e 四個字段,而索引 idx_bcd 剛好是建立在 b,c,d 三個字段上,那么走 idx_bcd 索引進行條件過濾應該能提高查詢效率,既然走 idx_bcd 索引進行條件過濾,那么我們來思考下以下幾個關鍵問題
1、上述 SQL,覆蓋了 idx_bcd 索引的哪個范圍 ?
起始點由 b >= 2,c > 0 決定,所以 2,1,2 是第一個需要檢查的索引項
終止點由 b < 7 決定,所以 8,7,8 是第一個不需要檢查的索引項, 8,7,8 后面的也無需檢索
2、范圍確定后,SQL 中還有哪些條件可以使用 idx_bcd 索引來過濾 ?
上面我們已經確認了范圍 2,1,2 ~ 8,7,8 ,那么在這個范圍內的每一個索引項是不是都滿足 WHERE 條件了 ? 很顯然不是, 4,0,5 不滿足 c > 0 , 2,1,2 不滿足 d != 2 ;所以 c,d 列的 where 條件可以通過索引 idx_bcd 來過濾
3、當 idx_bcd 索引物盡其用后,還有哪些條件是無法通過 idx_bcd 索引過濾的 ?
這個很明顯, e != 'a' 無法在索引 idx_bcd 上進行過濾,因為索引并未包含 e 列;e 列只在堆表上存在,所以需要將已經滿足索引查詢條件的記錄回表,取出對應的完整數據記錄,然后看該數據記錄中 e 列值是否滿足 e != 'a' 條件
有些小伙伴可能覺得上述 WHERE 條件的抽取具有特殊性,不具普遍性,那么我們抽象出一套放置于所有 SQL 語句皆準的 WHERE 查詢條件的提取規則:Index Key (First Key & Last Key),Index Filter,Table Filter,我們們往下仔細看
用于確定 SQL 查詢在索引中的連續范圍(起始點 + 終止點)的查詢條件,被稱之為Index Key;由于一個范圍,至少包含一個起始條件與一個終止條件,因此 Index Key 也被拆分為 Index First Key 和 Index Last Key,分別用于定位索引查找的起始點以終止點
Index First Key
用于確定索引查詢范圍的起始點;提取規則:從索引的第一個鍵值開始,檢查其在 where 條件中是否存在,若存在并且條件是 =、>=,則將對應的條件加入Index First Key之中,繼續讀取索引的下一個鍵值,使用同樣的提取規則;若存在并且條件是 >,則將對應的條件加入 Index First Key 中,同時終止 Index First Key 的提取;若不存在,同樣終止 Index First Key 的提取
針對 SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',應用這個提取規則,提取出來的 Index First Key 為 b >= 2, c > 0 ,由于 c 的條件為 >,提取結束
Index Last Key
用于確定索引查詢范圍的終止點,與 Index First Key 正好相反;提取規則:從索引的第一個鍵值開始,檢查其在 where 條件中是否存在,若存在并且條件是 =、<=,則將對應條件加入到 Index Last Key 中,繼續提取索引的下一個鍵值,使用同樣的提取規則;若存在并且條件是 < ,則將條件加入到 Index Last Key 中,同時終止提取;若不存在,同樣終止Index Last Key的提取
針對 SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',應用這個提取規則,提取出來的 Index Last Key為 b < 7 ,由于是 < 符號,提取結束
在完成 Index Key 的提取之后,我們根據 where 條件固定了索引的查詢范圍,那么是不是在范圍內的每一個索引項都滿足 WHERE 條件了 ? 很明顯 4,0,5 , 2,1,2 均屬于范圍中,但是又均不滿足SQL 的查詢條件
所以 Index Filter 用于索引范圍確定后,確定 SQL 中還有哪些條件可以使用索引來過濾;提取規則:從索引列的第一列開始,檢查其在 where 條件中是否存在,若存在并且 where 條件僅為 =,則跳過第一列繼續檢查索引下一列,下一索引列采取與索引第一列同樣的提取規則;若 where 條件為 >=、>、<、<= 其中的幾種,則跳過索引第一列,將其余 where 條件中索引相關列全部加入到 Index Filter 之中;若索引第一列的 where 條件包含 =、>=、>、<、<= 之外的條件,則將此條件以及其余 where 條件中索引相關列全部加入到 Index Filter 之中;若第一列不包含查詢條件,則將所有索引相關條件均加入到 Index Filter之中
針對 SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',應用這個提取規則,提取出來的 Index Filter 為 c > 0 and d != 2 ,因為索引第一列只包含 >=、< 兩個條件,因此第一列跳過,將余下的 c、d 兩列加入到 Index Filter 中,提取結束
這個就比較簡單了,where 中不能被索引過濾的條件都歸為此中;提取規則:所有不屬于索引列的查詢條件,均歸為 Table Filter 之中
針對 SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',應用這個提取規則,那么 Table Filter 就為 e != 'a'
是不是有點感覺了 ? 相信此刻,大家對 where 條件的提取基本清楚了,但怎么應用了 ?
SQL 語句中的 where 條件,最終都會被提取到 Index Key (First Key & Last Key),Index Filter 與 Table Filter 之中,那么 where 條件的應用,其實就是 Index Key (First Key & Last Key),Index Filter 與Table Filter 的應用
Index First Key,只是用來定位索引的起始點,因此只在索引第一次Search Path(沿著索引B+樹的根節點一直遍歷,到索引正確的葉節點位置)時使用,只會判斷一次
Index Last Key,用來定位索引的終止點,因此對于起始點之后讀到的每一條索引記錄,均需要判斷是否滿足 Index Last Key,若不滿足,則當前查詢結束
Index Filter,用于過濾索引范圍中不滿足條件的索引項,因此對于索引范圍中的每一條索引項,均需要與 Index Filter 進行匹對,若不滿足 Index Filter 則直接丟棄,繼續讀取索引下一條記錄
Table Filter,用于過濾不能被索引過濾的條件,此時的索引項已經滿足了 Index First Key 與 Index Last Key 構成的范圍,并且滿足 Index Filter 的條件,但是索引項無法過濾 Table Filter 中的條件,所以回表讀取完整的數據記錄,判斷完整記錄是否滿足 Table Filter 中的查詢條件,若不滿足,跳過當前記錄,繼續讀取索引項的下一條索引項,若滿足,則返回記錄,此記錄滿足了 where 的所有條件,可以返回給客戶端
1、SQL 語句中的 where 條件,最終都會被提取到 Index Key (First Key & Last Key),Index Filter 與 Table Filter ,提取規則需要大家好好體會下
2、數據庫中 where 條件的過濾是 one by one(一條一條)的方式進行的,聯表查詢其實也是 one by one 的方式進行的;雖然我們在開發中感覺到不是 one by one,那其實是數據庫驅動做了處理
3、Index Key 的提取,需要考慮到間隙鎖,避免幻讀問題,有興趣的小伙伴可以去琢磨下
4、MySQL 5.6 中引入的 Index Condition Pushdown,究竟是 Push Down 了什么,從哪 Push Down 到哪 ? 大家可以先去了解下,我們下篇詳細講解
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





