溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Python數據分析 | pandas匯總和計算描述統計,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
1. 聚合計算
pandas對象擁有一組常用的數學和統計方法。它們大部分都屬于約簡和匯總統計,用于從Series中提取單個值(如sum或mean)或從DataFrame的行或列中提取一個Series。跟對應的NumPy數組方法相比,它們都是基于沒有缺失數據的假設而構建的。看一個簡單的DataFrame:
df = pd.DataFrame([[1.4, np.nan], [7.1, -4.5], [np.nan, np.nan], [0.75, -1.3]], index=['a', 'b', 'c', 'd'], columns=['one', 'two']) df

調用DataFrame的sum方法將會返回一個含有列的和的Series:
df.sum() #默認axis=0/'index'

傳入axis='columns'或axis=1將會按行進行求和運算:
df.sum(axis='columns') #axis=1

NA值會自動被排除,除非整個切片(這里指的是行或列)都是NA。通過skipna選項可以禁用該功能:
print(df)
print("-----")
print(df.mean(axis='columns', skipna=False)) #axis=1
print("-----")
print(df.mean(axis='columns')) #axis=1 自動跳過na
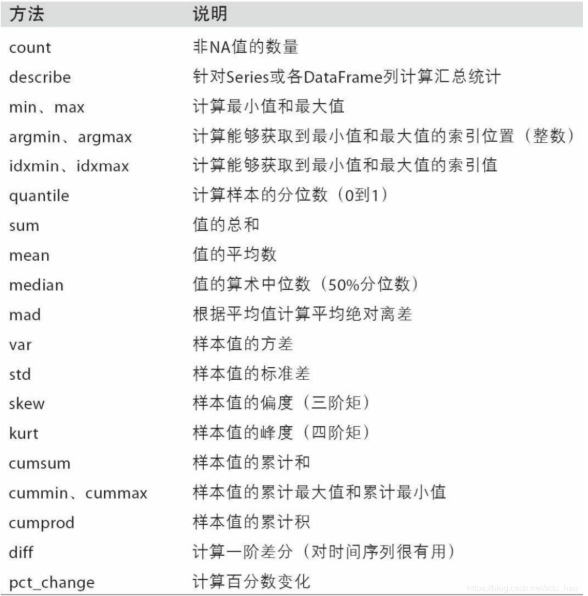
下表列出了這些約簡方法的常用選項:

有些方法(如idxmin和idxmax)返回的是間接統計(比如達到最小值或最大 值的索引):
print(df)
print("-------")
df.idxmax() #axis=0
另一些方法則是累計型的:
print(df)
print("-------")
df.cumsum() #axis=0
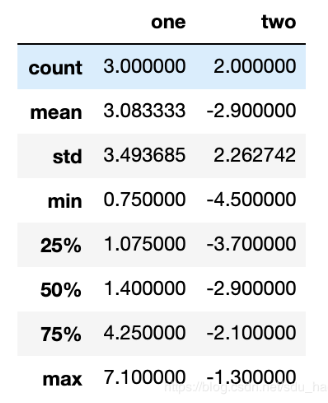
還有一種方法,它既不是約簡型也不是累計型。describe就是一個例子,它 用于一次性產生多個匯總統計:
df.describe() #默認忽略空值
對于非數值型數據,describe會產生另外一種匯總統計:
obj = pd.Series(['a', 'a', 'b', 'c'] * 4) obj.describe()

下表列出了所有與描述統計相關的方法。
2. 相關系數與協方差
有些匯總統計(如相關系數和協方差)是通過參數對計算出來的。我們來看 幾個DataFrame,它們的數據來自Yahoo!Finance的股票價格和成交量,使 用的是pandas-datareader包(可以用conda或pip安裝):
pip install pandas-datareader
我使用pandas_datareader模塊下載了一些股票數據:
import pandas_datareader.data as web
all_data = {ticker: web.get_data_yahoo(ticker) for ticker in ['AAPL', 'IBM', 'MSFT', 'GOOG']}
price = pd.DataFrame({ticker: data['Adj Close'] for ticker, data in all_data.items()})
volume = pd.DataFrame({ticker: data['Volume'] for ticker, data in all_data.items()})
print(price.head())
print(volume.head())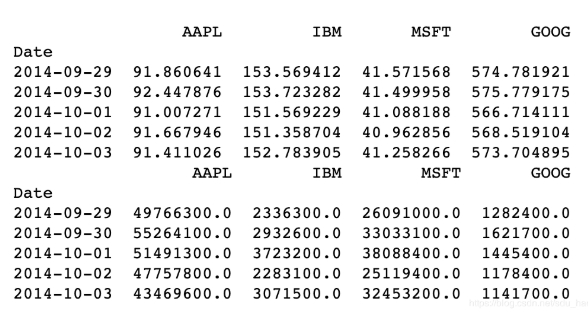
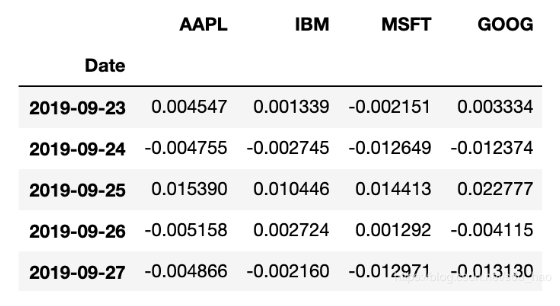
現在計算價格的百分數變化,時間序列的操作后續會介紹:
returns = price.pct_change() returns.tail()
Series的corr方法用于計算兩個Series中重疊的、非NA的、按索引對齊的值 的相關系數。與此類似,cov用于計算協方差:
print(returns['MSFT'].corr(returns['IBM'])) print(returns['MSFT'].cov(returns['IBM']))

因為MSTF是一個合理的Python屬性,我們還可以用更簡潔的語法選擇列:
returns.MSFT.corr(returns.IBM)
另一方面,DataFrame的corr和cov方法將以DataFrame的形式分別返回完整 的相關系數或協方差矩陣:
print(returns.corr())
print("-----------")
print(returns.cov())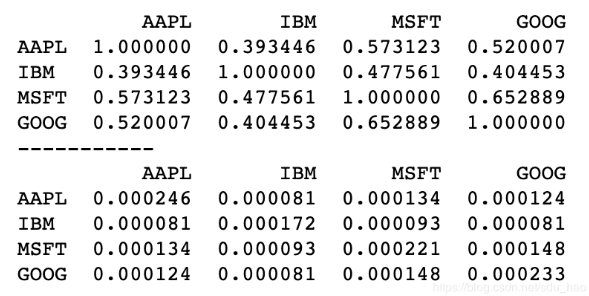
利用DataFrame的corrwith方法,你可以計算其列或行跟另一個Series或DataFrame之間的相關系數。傳入一個Series將會返回一個相關系數值Series(針對各列進行計算)
returns.corrwith(returns.IBM)

傳入一個DataFrame則會計算按列名配對的相關系數。這里,我計算百分比 變化與成交量的相關系數:
print(returns.head()) print(volume.head()) returns.corrwith(volume) #按列配對
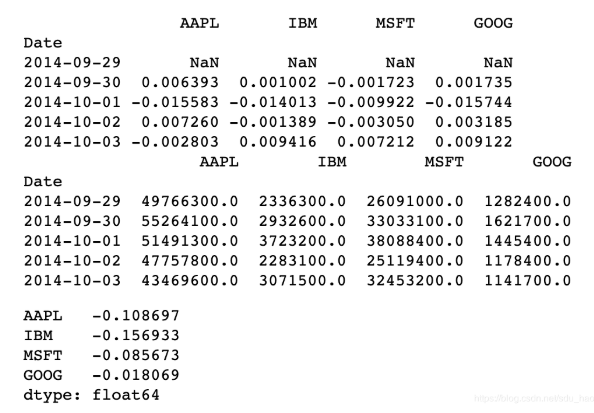
傳入axis='columns'/1即可按行進行計算。無論如何,在計算相關系數之前,所 有的數據項都會按標簽對齊。
3. 唯一值、值計數以及成員資格
還有一類方法可以從一維Series的值中抽取信息。看下面的例子:
obj = pd.Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c']) obj

第一個函數是unique,它可以得到Series中的唯一值數組:
uniques = obj.unique() uniques
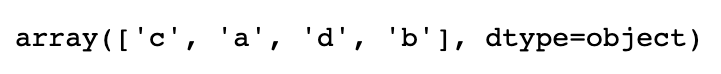
返回的唯一值是未排序的,如果需要的話,可以對結果再次進行排序 (uniques.sort())。相似的,value_counts用于計算一個Series中各值出現 的頻率:
obj.value_counts()

為了便于查看,結果Series是按值頻率降序排列的。value_counts還是一個 頂級pandas方法,可用于任何數組或序列:
pd.value_counts(obj.values, sort=False)

isin用于判斷矢量化集合的成員資格,可用于過濾Series中或DataFrame列中 數據的子集:
print(obj)
print("-----------")
mask = obj.isin(['b', 'c'])
print(mask)
print("-----------")
obj[mask]
與isin類似的是Index.get_indexer方法,它可以給你一個索引數組,從可能包 含重復值的數組到另一個不同值的數組:
to_match = pd.Series(['c', 'a', 'b', 'b', 'c', 'a']) unique_vals = pd.Series(['c', 'b', 'a']) pd.Index(unique_vals).get_indexer(to_match)
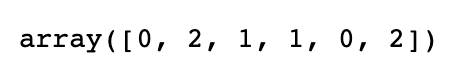
下表給出了這幾個方法的一些參考信息:

有時,你可能希望得到DataFrame中多個相關列的一張柱狀圖。例如:
data = pd.DataFrame({'Qu1': [1, 3, 4, 3, 4],
'Qu2': [2, 3, 1, 2, 3],
'Qu3': [1, 5, 2, 4, 4]})
data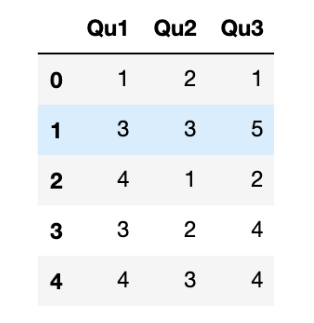
將pandas.value_counts傳給該DataFrame的apply函數,就會出現:
result = data.apply(pd.value_counts).fillna(0) result
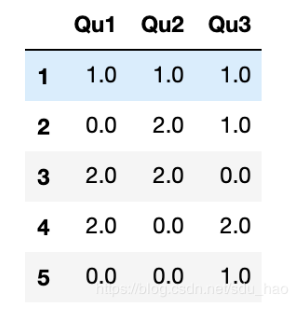
這里,結果中的行標簽是所有列的唯一值。后面的頻率值是每個列中這些值的相應計數。
上述就是小編為大家分享的Python數據分析 | pandas匯總和計算描述統計了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





