溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python3爬蟲實戰mitmdump爬取App電子書信息的操作流程,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
mitmdump 爬取 “得到” App 電子書信息
“得到” App 是羅輯思維出品的一款碎片時間學習的 App,其官方網站為 https://www.igetget.com,App 內有很多學習資源。不過 “得到” App 沒有對應的網頁版,所以信息必須要通過 App 才可以獲取。這次我們通過抓取其 App 來練習 mitmdump 的用法。
1. 爬取目標
我們的爬取目標是 App 內電子書版塊的電子書信息,并將信息保存到 MongoDB,如圖 11-30 所示。
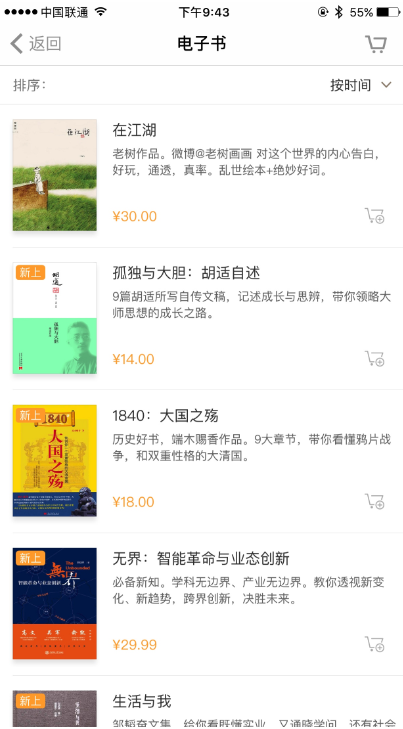
我們要把圖書的名稱、簡介、封面、價格爬取下來,不過這次爬取的側重點還是了解 mitmdump 工具的用法,所以暫不涉及自動化爬取,App 的操作還是手動進行。mitmdump 負責捕捉響應并將數據提取保存。
2. 準備工作
請確保已經正確安裝好了 mitmproxy 和 mitmdump,手機和 PC 處于同一個局域網下,同時配置好了 mitmproxy 的 CA 證書,安裝好 MongoDB 并運行其服務,安裝 PyMongo 庫,具體的配置可以參考第 1 章的說明。
3. 抓取分析
首先探尋一下當前頁面的 URL 和返回內容,我們編寫一個腳本如下所示:
def response(flow): print(flow.request.url) print(flow.response.text)
這里只輸出了請求的 URL 和響應的 Body 內容,也就是請求鏈接和響應內容這兩個最關鍵的部分。腳本保存名稱為 script.py。
接下來運行 mitmdump,命令如下所示:
mitmdump -s script.py
打開 “得到” App 的電子書頁面,便可以看到 PC 端控制臺有相應輸出。接著滑動頁面加載更多電子書,控制臺新出現的輸出內容就是 App 發出的新的加載請求,包含了下一頁的電子書內容。控制臺輸出結果示例如圖 11-31 所示。
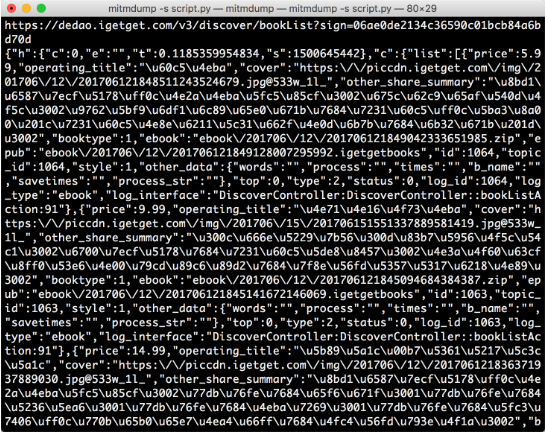
圖 11-31 控制臺輸出
可以看到 URL 為 https://dedao.igetget.com/v3/discover/bookList 的接口,其后面還加了一個 sign 參數。通過 URL 的名稱,可以確定這就是獲取電子書列表的接口。在 URL 的下方輸出的是響應內容,是一個 JSON 格式的字符串,我們將它格式化,如圖 11-32 所示。
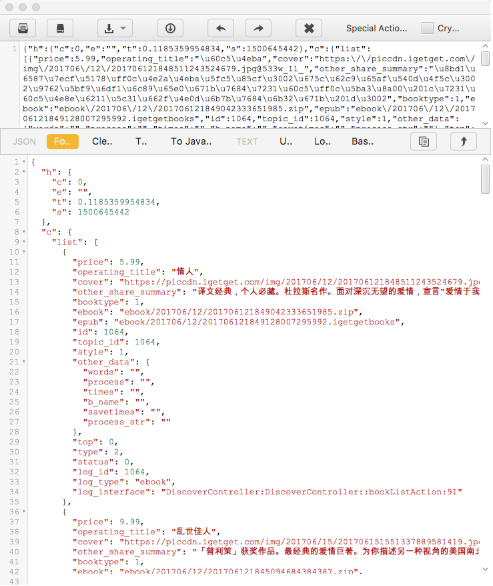
圖 11-32 格式化結果
格式化后的內容包含一個 c 字段、一個 list 字段,list 的每個元素都包含價格、標題、描述等內容。第一個返回結果是電子書《情人》,而此時 App 的內容也是這本電子書,描述的內容和價格也是完全匹配的,App 頁面如圖 11-33 所示。

圖 11-33 APP 頁面
這就說明當前接口就是獲取電子書信息的接口,我們只需要從這個接口來獲取內容就好了。然后解析返回結果,將結果保存到數據庫。
4. 數據抓取
接下來我們需要對接口做過濾限制,抓取如上分析的接口,再提取結果中的對應字段。
這里,我們修改腳本如下所示:
import json
from mitmproxy import ctx
def response(flow):
url = 'https://dedao.igetget.com/v3/discover/bookList'
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
ctx.log.info(str(book))重新滑動電子書頁面,在 PC 端控制臺觀察輸出,如圖 11-34 所示。
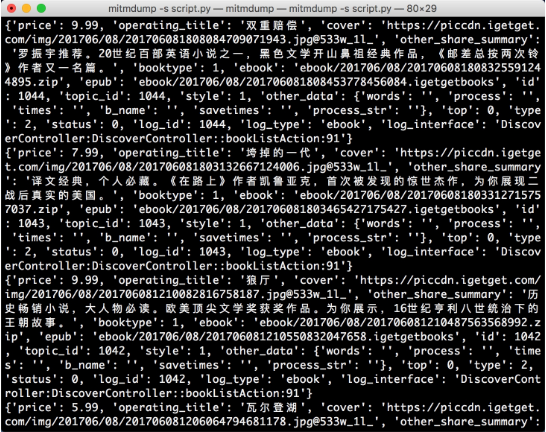
圖 11-34 控制臺輸出
現在輸出了圖書的全部信息,一本圖書信息對應一條 JSON 格式的數據。
5. 提取保存
接下來我們需要提取信息,再把信息保存到數據庫中。方便起見,我們選擇 MongoDB 數據庫。
腳本還可以增加提取信息和保存信息的部分,修改代碼如下所示:
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/discover/bookList'
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)重新滑動頁面,控制臺便會輸出信息,如圖 11-35 所示。
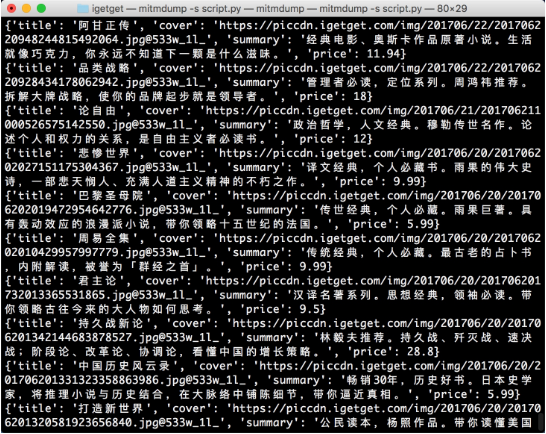
圖 11-35 控制臺輸出
現在輸出的每一條內容都是經過提取之后的內容,包含了電子書的標題、封面、描述、價格信息。
最開始我們聲明了 MongoDB 的數據庫連接,提取出信息之后調用該對象的 insert() 方法將數據插入到數據庫即可。
滑動幾頁,發現所有圖書信息都被保存到 MongoDB 中,如圖 11-36 所示。
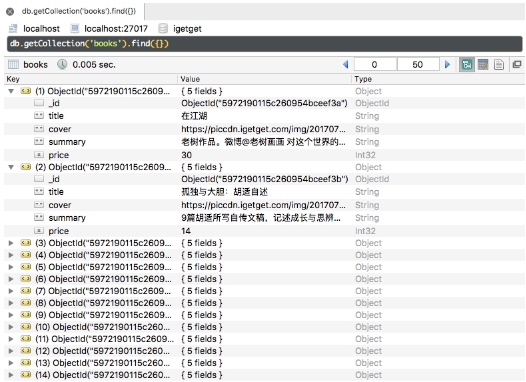
目前為止,我們利用一個非常簡單的腳本把 “得到” App 的電子書信息保存下來。
看完了這篇文章,相信你對Python3爬蟲實戰mitmdump爬取App電子書信息的操作流程有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





