溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Appium+mitmdump爬取京東商品的方法,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
Appium+mitmdump 爬取京東商品
在前文中,我們曾經用 Charles 分析過京東商品的評論數據,但是可以發現其參數相當復雜,Form 表單有很多加密參數。如果我們只用 Charles 探測到這個接口鏈接和參數,還是無法直接構造請求的參數,構造的過程涉及一些加密算法,也就無法直接還原抓取過程。
我們了解了 mitmproxy 的用法,利用它的 mitmdump 組件,可以直接對接 Python 腳本對抓取的數據包進行處理,用 Python 腳本對請求和響應直接進行處理。這樣我們可以繞過請求的參數構造過程,直接監聽響應進行處理即可。但是這個過程并不是自動化的,抓取 App 的時候實際是人工模擬了這個拖動過程。如果這個操作可以用程序來實現就更好了。
我們又了解了 Appium 的用法,它可以指定自動化腳本模擬實現 App 的一系列動作,如點擊、拖動等,也可以提取 App 中呈現的信息。經過上節爬取微信朋友圈的實例,我們知道解析過程比較煩瑣,而且速度要加以限制。如果內容沒有顯示出來解析就會失敗,而且還會導致重復提取的問題。更重要的是,它只可以獲取在 App 中看到的信息,無法直接提取接口獲取的真實數據,而接口的數據往往是最易提取且信息量最全的。
綜合以上幾點,我們就可以確定出一個解決方案了。如果我們用 mitmdump 去監聽接口數據,用 Appium 去模擬 App 的操作,就可以繞過復雜的接口參數又可以實現自動化抓取了!這種方式應是抓取 App 數據的最佳方式。某些特殊情況除外,如微信朋友圈數據又經過了一次加密無法解析,而只能用 Appium 提取。但是對于大多數 App 來說,此種方法是奏效的。本節我們用一個實例感受一下這種抓取方式的便捷之處。
1. 本節目標
以抓取京東 App 的商品信息和評論為例,實現 Appium 和 mitmdump 二者結合的抓取。抓取的數據分為兩部分:一部分是商品信息,我們需要獲取商品的 ID、名稱和圖片,將它們組成一條商品數據;另一部分是商品的評論信息,我們將評論人的昵稱、評論正文、評論日期、發表圖片都提取,然后加入商品 ID 字段,將它們組成一條評論數據。最后數據保存到 MongoDB 數據庫。
2. 準備工作
請確保 PC 已經安裝好 Charles、mitmdump、Appium、Android 開發環境,以及 Python 版本的 Appium API。Android 手機安裝好京東 App。另外,安裝好 MongoDB 并運行其服務,安裝 PyMongo 庫。具體的配置過程可以參考第 1 章。
3. Charles 抓包分析
首先,我們將手機代理設置到 Charles 上,用 Charles 抓包分析獲取商品詳情和商品評論的接口。
獲取商品詳情的接口,這里提取到的接口是來自 cdnware.m.jd.com 的鏈接,返回結果是一個 JSON 字符串,里面包含了商品的 ID 和商品名稱,如圖 11-47 和圖 11-48 所示。
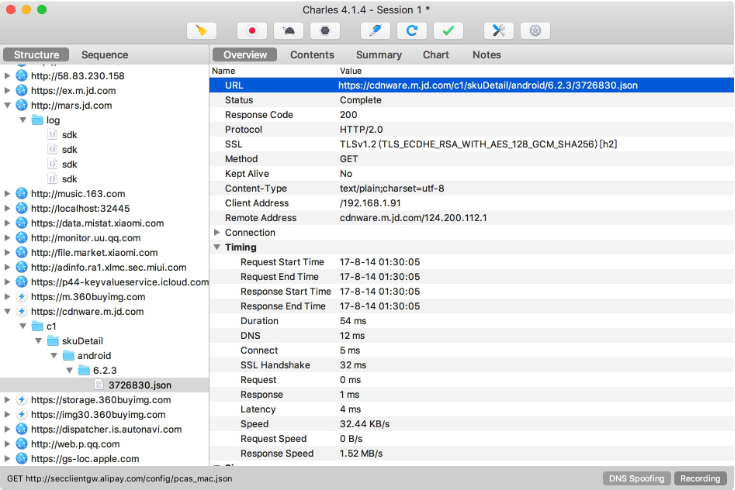
圖 11-47 請求概覽
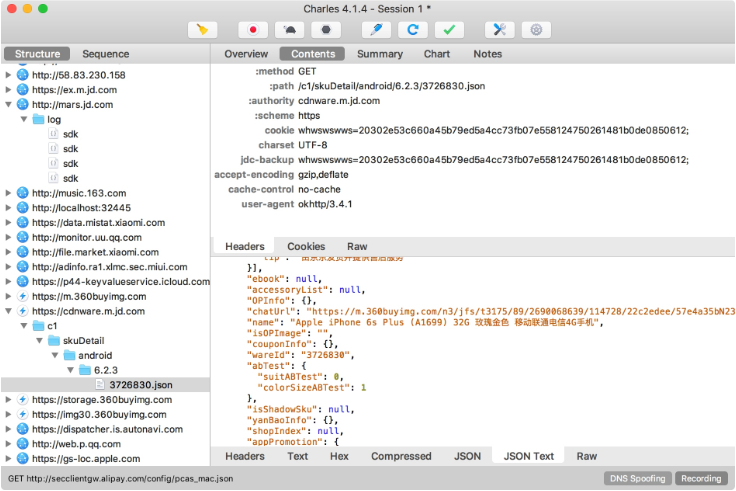
圖 11-48 響應結果
再獲取商品評論的接口,這個過程在前文已提到,在此不再贅述。這個接口來自 api.m.jd.com,返回結果也是 JSON 字符串,里面包含了商品的數條評論信息。
之后我們可以用 mitmdump 對接一個 Python 腳本來實現數據的抓取。
4. mitmdump 抓取
新建一個腳本文件,然后實現這個腳本以提取這兩個接口的數據。首先提取商品的信息,代碼如下所示:
def response(flow):
url = 'cdnware.m.jd.com'
if url in flow.request.url:
text = flow.response.text
data = json.loads(text)
if data.get('wareInfo') and data.get('wareInfo').get('basicInfo'):
info = data.get('wareInfo').get('basicInfo')
id = info.get('wareId')
name = info.get('name')
images = info.get('wareImage')
print(id, name, images)這里聲明了接口的部分鏈接內容,然后與請求的 URL 作比較。如果該鏈接出現在當前的 URL 中,那就證明當前的響應就是商品詳情的響應,然后提取對應的 JSON 信息即可。在這里我們將商品的 ID、名稱和圖片提取出來,這就是一條商品數據。
再提取評論的數據,代碼實現如下所示:
# 提取評論數據
url = 'api.m.jd.com/client.action'
if url in flow.request.url:
pattern = re.compile('sku".*?"(d+)"')
# Request 請求參數中包含商品 ID
body = unquote(flow.request.text)
# 提取商品 ID
id = re.search(pattern, body).group(1) if re.search(pattern, body) else None
# 提取 Response Body
text = flow.response.text
data = json.loads(text)
comments = data.get('commentInfoList') or []
# 提取評論數據
for comment in comments:
if comment.get('commentInfo') and comment.get('commentInfo').get('commentData'):
info = comment.get('commentInfo')
text = info.get('commentData')
date = info.get('commentDate')
nickname = info.get('userNickName')
pictures = info.get('pictureInfoList')
print(id, nickname, text, date, pictures)這里指定了接口的部分鏈接內容,以判斷當前請求的 URL 是不是獲取評論的 URL。如果滿足條件,那么就提取商品的 ID 和評論信息。
商品的 ID 實際上隱藏在請求中,我們需要提取請求的表單內容來提取商品的 ID,這里直接用了正則表達式。
商品的評論信息在響應中,我們像剛才一樣提取了響應的內容,然后對 JSON 進行解析,最后提取出商品評論人的昵稱、評論正文、評論日期和圖片信息。這些信息和商品的 ID 組合起來,形成一條評論數據。
最后用 MongoDB 將兩部分數據分開保存到兩個 Collection,在此不再贅述。
運行此腳本,命令如下所示:
mitmdump -s script.py
手機的代理設置到 mitmdump 上。我們在京東 App 中打開某個商品,下拉商品評論部分,即可看到控制臺輸出兩部分的抓取結果,結果成功保存到 MongoDB 數據庫,如圖 11-49 所示。
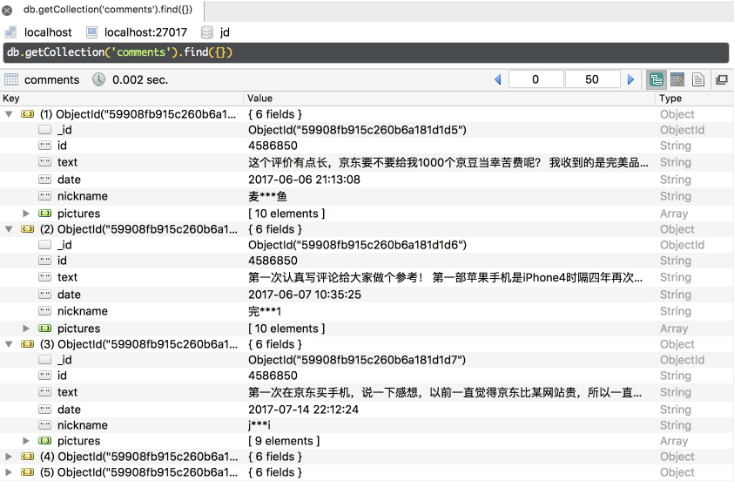
圖 11-49 保存結果
如果我們手動操作京東 App 就可以做到京東商品評論的抓取了,下一步要做的就是實現自動滾動刷新。
5. Appium 自動化
將 Appium 對接到手機上,用 Appium 驅動 App 完成一系列動作。進入 App 后,我們需要做的操作有點擊搜索框、輸入搜索的商品名稱、點擊進入商品詳情、進入評論頁面、自動滾動刷新,基本的操作邏輯和爬取微信朋友圈的相同。
京東 App 的 Desired Capabilities 配置如下所示:
{
'platformName': 'Android',
'deviceName': 'MI_NOTE_Pro',
'appPackage': 'com.jingdong.app.mall',
'appActivity': 'main.MainActivity'
}首先用 Appium 內置的驅動打開京東 App,如圖 11-50 所示。
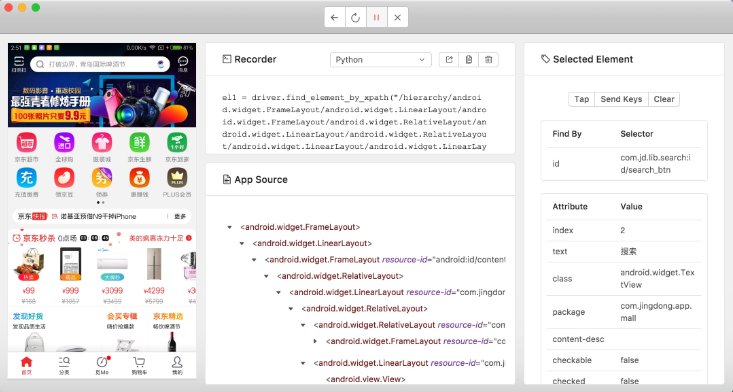
圖 11-50 調試界面
這里進行一系動作操作并錄制下來,找到各個頁面的組件的 ID 并做好記錄,最后再改寫成完整的代碼。參考代碼實現如下所示:
from appium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
class Action():
def __init__(self):
# 驅動配置
self.desired_caps = {
'platformName': PLATFORM,
'deviceName': DEVICE_NAME,
'appPackage': 'com.jingdong.app.mall',
'appActivity': 'main.MainActivity'
}
self.driver = webdriver.Remote(DRIVER_SERVER, self.desired_caps)
self.wait = WebDriverWait(self.driver, TIMEOUT)
def comments(self):
# 點擊進入搜索頁面
search = self.wait.until(EC.presence_of_element_located((By.ID, 'com.jingdong.app.mall:id/mp')))
search.click()
# 輸入搜索文本
box = self.wait.until(EC.presence_of_element_located((By.ID, 'com.jd.lib.search:id/search_box_layout')))
box.set_text(KEYWORD)
# 點擊搜索按鈕
button = self.wait.until(EC.presence_of_element_located((By.ID, 'com.jd.lib.search:id/search_btn')))
button.click()
# 點擊進入商品詳情
view = self.wait.until(EC.presence_of_element_located((By.ID, 'com.jd.lib.search:id/product_list_item')))
view.click()
# 進入評論詳情
tab = self.wait.until(EC.presence_of_element_located((By.ID, 'com.jd.lib.productdetail:id/pd_tab3')))
tab.click()
def scroll(self):
while True:
# 模擬拖動
self.driver.swipe(FLICK_START_X, FLICK_START_Y + FLICK_DISTANCE, FLICK_START_X, FLICK_START_Y)
sleep(SCROLL_SLEEP_TIME)
def main(self):
self.comments()
self.scroll()
if __name__ == '__main__':
action = Action()
action.main()代碼實現比較簡單,邏輯與上一節微信朋友圈的抓取類似。注意,由于 App 版本更新的原因,交互流程和元素 ID 可能有更改,這里的代碼僅做參考。
下拉過程已經省去了用 Appium 提取數據的過程,因為這個過程我們已經用 mitmdump 幫助實現了。
代碼運行之后便會啟動京東 App,進入商品的詳情頁,然后進入評論頁再無限滾動,這樣就代替了人工操作。Appium 實現模擬滾動,mitmdump 進行抓取,這樣 App 的數據就會保存到數據庫中。
看完了這篇文章,相信你對Appium+mitmdump爬取京東商品的方法有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





