溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹關于字體反爬的介紹,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
目前已知的幾個字體反爬的網站是貓眼,汽車之家,天眼查,起點中文網等等。
以前也看過這方面的文章,今天跟個老哥在交流的時候,終于實操了一把,弄懂了字體反爬是個啥玩意。下面聽我慢慢道來。
本文用到的第三方庫
fontTools
一、目標網站
url = “https://su.58.com/qztech/”
二、反爬蟲機制
網頁上看見的

后臺源代碼里面的
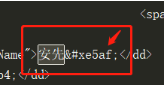
從上面可以看出,生這個字變成了亂碼,請大家特別注意箭頭所指的數字。
三、解決
1、確定反爬方法
在看了別人的解析文章之后,確定采取的是字體反爬機制,即網站定義了字體文件,然后進行相應的查找替換,在前端看起來,是沒有任何差異的。其實從審查元素的也是可以看到的:
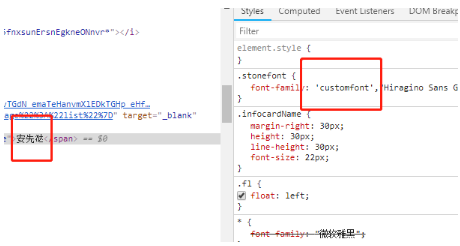
和大眾點評的反爬差不多,都是通過css搞得。
2、尋找字體文件
以上面方框里的”customfont“為關鍵詞搜了一下,發現就在源代碼里面:

而且還有base64,直接進行解密,但是解密出來的其實是亂碼,這個時候其實要做的很簡單,把解密后的內容保存為.ttf格式即可。
ttf文件: *.ttf是字體文件格式。TTF(TrueTypeFont)是Apple公司和Microsoft公司共同推出的字體文件格式,隨著windows的流行,已經變成最常用的一種字體文件表示方式。
@font-face 是CSS3中的一個模塊,主要是實現將自定義的Web字體嵌入到指定網頁中去。
因為我們要對字體進行研究,所以必須將它打開,這里我是用的是FontCreator,打開以后是這個樣子(其實很多字,在這里為了看的清楚,所以只截了下面的圖):

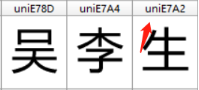
很明顯,每個字可以看到字形和字形編碼。
觀察現在箭頭指的地方和前面箭頭指的地方的數字是不是一樣啊,沒錯,就是通過這種方法進行映射的。
所以我們現在的思路似乎就是在源代碼里找到箭頭指的數字,然后再來字體里找到后替換就行了。
恭喜你,如果你也是這么想的,那你就掉坑里了。
因為每次訪問,字體字形是不變的,但字符的編碼確是變化的。因此,我們需要根據每次訪問,動態解析字體文件。
字體1:

字體2:
所以想通過寫死的方式也是行不通的。
這個時候我們就要對字體文件進行更深一步的研究了。
3、研究字體文件
剛剛的.ttf文件我們是看不到內部的東西的,所以這個時候我們要對字體文件進行轉換格式,將其轉換為xml格式,然后來查看:
具體操作如下:
from fontTools.ttLib import TTFont
font_1 = TTFont('58_font_1.ttf')
font_base.saveXML('font_1.xml')xml的格式如下:
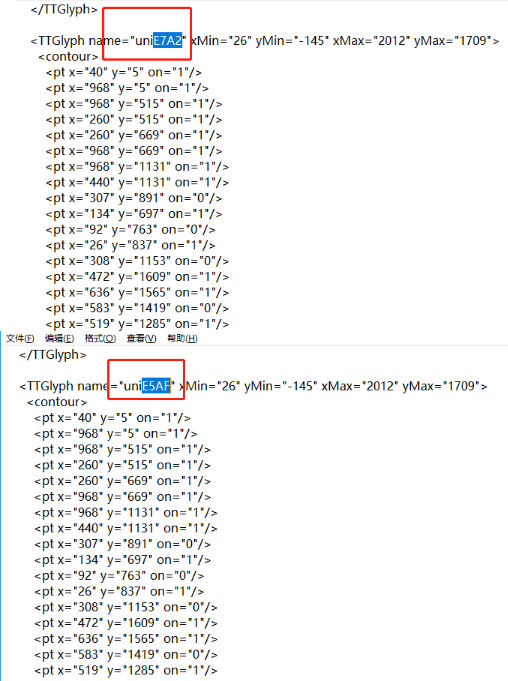
今天,我終于弄懂了字體反爬是個啥玩意!
文件很長,我只截取了一部分。
仔細的觀察一下,你會發現~這倆下面的x,y,on值都是一毛一樣的。所以我們的思路就是以一個已知的字體文件為基本,然后將獲取到的新的字體文件的每個文字對應的x,y,on值進行比較,如果相同,那么說明新的文字對就可以在基礎字體那里找到對應的文字,有點繞,下面舉個小例子。
假設:“我”在基本字體中的名為uni1,對應的x=1,y=1,n=1新的字體文件中,一個名為uni2對應的x,y,n分別于上面的相等,那么這個時候就可以確定uni2 對應的文字為“我”。
查資料的時候,發現在特殊情況下,有時候兩個字體中的文字對應的x,y不相等,但是差距都是在某一個閾值之內,處理方法差不多,只不過上面是相等,這種情況下就是要比較一下。
其實,如果你用畫圖工具按照上面的x與y值把點給連起來,你會發現,就是漢字的字形~
所以,到此總結一下:
一、將某次請求獲取到的字體文件保存到本地[基本字體]; 二、用軟件打開后,人工的找出每一個數字對應的編碼[一定要保證順序的正確,要不然會出事]; 三、我們以后訪問網頁時,需要保存新字體文件; 四、用Fonttools庫對基本字體與新字體進行處理,找到新的字體與基本字體之間的映射; 五、替換;
4、上代碼
微信里上代碼真的太丑了,
還是算了吧,微信后臺關鍵詞“字體加密” 即可獲取github地址。
看一下成果:

其實這個流程最大的問題就是我們人工錄入的基本字體的字典數據有可能是會發生變化的,這就導致我們后面還要手動去改。
現在,如果你已經看懂了本文,那么還不快去其他幾個網站試試?
以上是關于字體反爬的介紹的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





