溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下利用Python分析《慶余年》人物圖譜和微博傳播路徑的方法,相信大部分人都還不怎么了解,因此分享這篇文章給大家學習,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去學習方法吧!
利用Python分析《慶余年》人物圖譜和微博傳播路徑
慶余年電視劇終于在前兩天上了,這兩天趕緊爬取微博數據看一下它的表現。
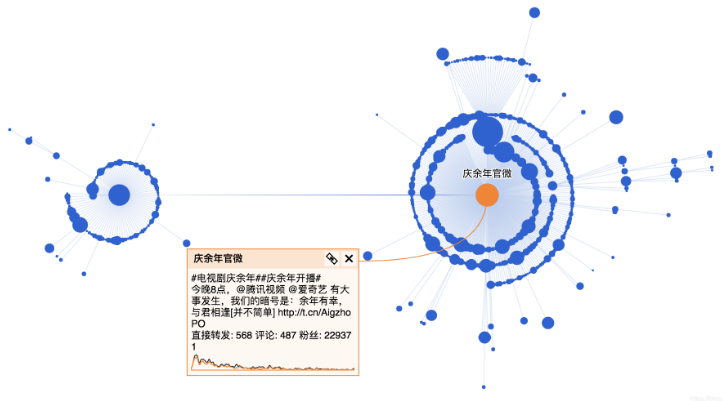
慶余年
《慶余年》是作家貓膩的小說。這部從2007年就開更的作品擁有固定的書迷群體,也在文學IP價值榜上有名。

期待已久的影視版的《慶余年》終于播出了,一直很擔心它會走一遍《盜墓筆記》的老路。
在《慶余年》電視劇上線后,就第一時間去看了,真香。

慶余年微博傳播分析
《慶余年》在微博上一直霸占熱搜榜,去微博看一下大家都在討論啥:
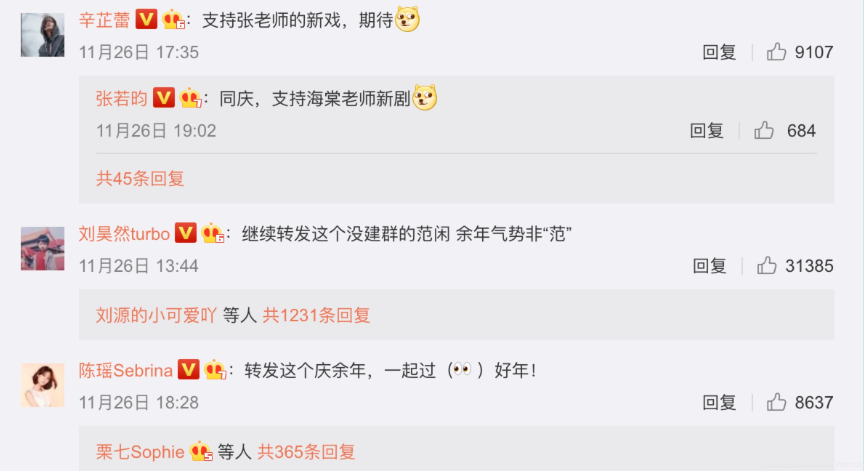
一條條看顯然不符合數據分析師身份。
于是爬取了微博超話頁面,然后找到相關人員,分別去爬取相關人員的微博評論,看看大家都在討論啥。
import re
import time
import copy
import pickle
import requests
import argparse
'''微博爬蟲類'''
class weibo():
def __init__(self, **kwargs):
self.login_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome
/72.0.3626.109 Safari/537.36',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Origin': 'https://passport.weibo.cn',
'Referer': 'https://passport.weibo.cn/signin/login?entry=mweibo&r=https%3A%2F%2Fweibo.cn%2F&backTitle=%CE%A2%B2%A9&vt='
}
self.login_url = 'https://passport.weibo.cn/sso/login'
self.home_url = 'https://weibo.com/'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome
/72.0.3626.109 Safari/537.36',
}
self.session = requests.Session()
self.time_interval = 1.5
'''獲取評論數據'''
def getComments(self, url, url_type='pc', max_page='all', savename=None, is_print=True, **kwargs):
# 判斷max_page參數是否正確
if not isinstance(max_page, int):
if max_page != 'all':
raise ValueError('[max_page] error, weibo.getComments -> [max_page] should be <number(int) larger than 0>
or <all>')
else:
if max_page < 1:
raise ValueError('[max_page] error, weibo.getComments -> [max_page] should be <number(int) larger than 0>
or <all>')
# 判斷鏈接類型
if url_type == 'phone':
mid = url.split('/')[-1]
elif url_type == 'pc':
mid = self.__getMid(url)
else:
raise ValueError('[url_type] error, weibo.getComments -> [url_type] should be <pc> or <phone>')
# 數據爬取
headers = copy.deepcopy(self.headers)
headers['Accept'] = 'application/json, text/plain, */*'
headers['MWeibo-Pwa'] = '1'
headers['Referer'] = 'https://m.weibo.cn/detail/%s' % mid
headers['X-Requested-With'] = 'XMLHttpRequest'
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0'.format(mid, mid)
num_page = 0
comments_data = {}
while True:
num_page += 1
print('[INFO]: Start to get the comment data of page%d...' % num_page)
if num_page > 1:
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id={}&max_id_type={}'.format(mid, mid, max_id,
max_id_type)
res = self.session.get(url, headers=headers)
comments_data[num_page] = res.json()
if is_print:
print(res.json())
try:
max_id = res.json()['data']['max_id']
max_id_type = res.json()['data']['max_id_type']
except:
break
if isinstance(max_page, int):
if num_page < max_page:
time.sleep(self.time_interval)
else:
break
else:
if int(float(max_id)) != 0:
time.sleep(self.time_interval)
else:
break
if savename is None:
savename = 'comments_%s.pkl' % str(int(time.time()))
with open(savename, 'wb') as f:
pickle.dump(comments_data, f)
return True
'''模擬登陸'''
def login(self, username, password):
data = {
'username': username,
'password': password,
'savestate': '1',
'r': 'https://weibo.cn/',
'ec': '0',
'pagerefer': 'https://weibo.cn/pub/',
'entry': 'mweibo',
'wentry': '',
'loginfrom': '',
'client_id': '',
'code': '',
'qq': '',
'mainpageflag': '1',
'hff': '',
'hfp': ''
}
res = self.session.post(self.login_url, headers=self.login_headers, data=data)
if res.json()['retcode'] == 20000000:
self.session.headers.update(self.login_headers)
print('[INFO]: Account -> %s, login successfully...' % username)
return True
else:
raise RuntimeError('[INFO]: Account -> %s, fail to login, username or password error...' % username)
'''獲取PC端某條微博的mid'''
def __getMid(self, pc_url):
headers = copy.deepcopy(self.headers)
headers['Cookie'] = 'SUB=_2AkMrLtDRf8NxqwJRmfgQzWzkZI11ygzEieKdciEKJRMxHRl-yj83qhAHtRB6AK7-PqkF1Dj9vq59_dD6uw4ZKE
_AJB3c;'
res = requests.get(pc_url, headers=headers)
mid = re.findall(r'mblog&act=(\d+)\\', res.text)[0]
return mid
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser(description="weibo comments spider")
parser.add_argument('-u', dest='username', help='weibo username', default='')
parser.add_argument('-p', dest='password', help='weibo password', default='')
parser.add_argument('-m', dest='max_page', help='max number of comment pages to crawl(number<int> larger
than 0 or all)', default=100)
parser.add_argument('-l', dest='link', help='weibo comment link', default='')
parser.add_argument('-t', dest='url_type', help='weibo comment link type(pc or phone)', default='pc')
args = parser.parse_args()
wb = weibo()
username = args.username
password = args.password
try:
max_page = int(float(args.max_page))
except:
pass
**加粗樣式**url = args.link
url_type = args.url_type
if not username or not password or not max_page or not url or not url_type:
raise ValueError('argument error')
wb.login(username, password)
wb.getComments(url, url_type, max_page)爬取到微博評論后,老規矩,詞云展示一下,不同主角的評論內容差別還是挺大的
微博評論詞云分析
不同主演的評論風格差異較大,也與微博內容息息相關。
張若昀:

李沁:

肖戰:
emmm…算了吧

從目前大家的評論來看,情緒比較正向,評價較高,相信《慶余年》會越來越火的。
這部劇在微博熱度這么高,都是誰在傳播呢?
于是我進一步點擊用戶頭像獲取轉發用戶的公開信息。
看了一下幾位主演的相關微博,都是幾十萬的評論和轉發,尤其是肖戰有百萬級的轉發,嘗試爬了一下肖戰的微博,執行了6個小時只爬了十分之一。
最終還是敗給了各位小飛俠,之后有結果再同步給大家。

于是我只能挑軟柿子捏,換成官微的微博。
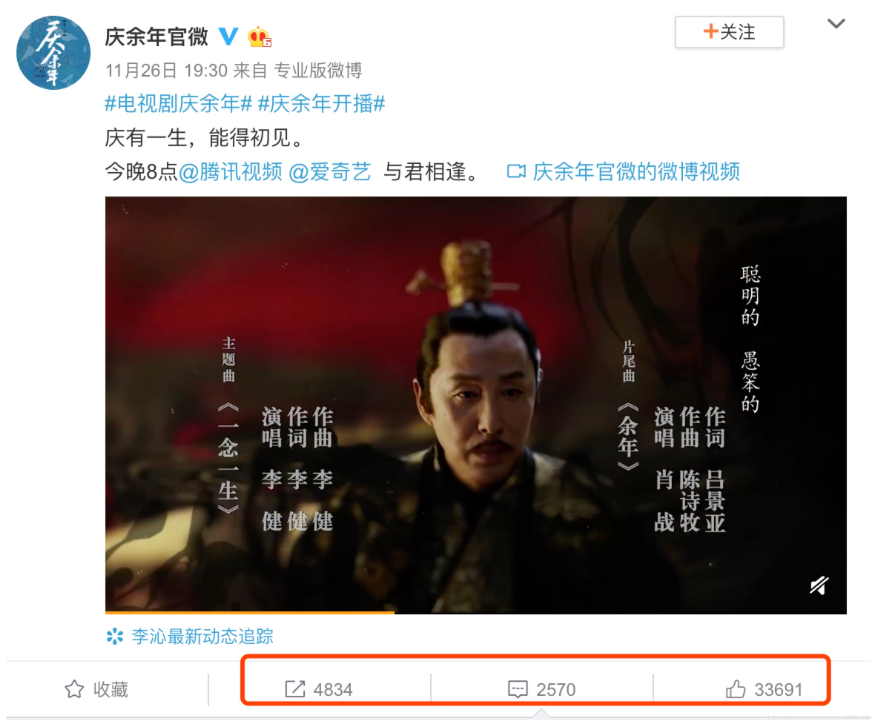
這條微博發布時間是26號,經過一段時間已經有比較好的傳播,其中有幾個關鍵節點進一步引爆話題。
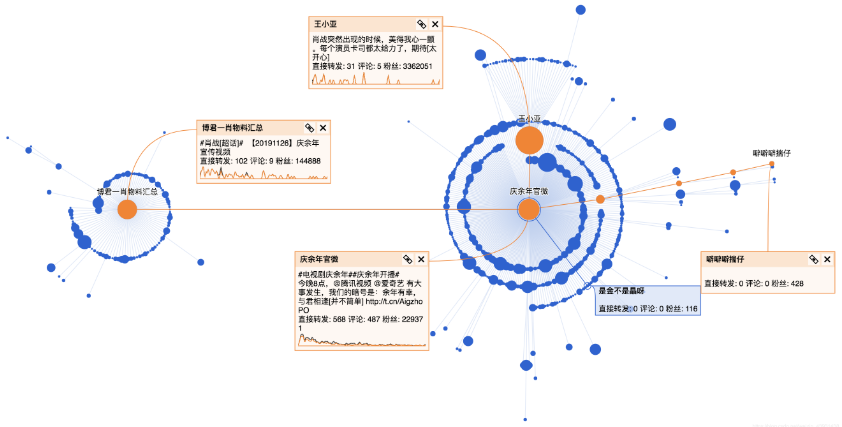
經過幾個關鍵節點后,進一步獲得傳播,這幾個關鍵節點分別是:
肖戰的超話:https://weibo.com/1081273845/Ii1ztr1BH
王小亞的微博:https://weibo.com/6475144268/Ii1rDEN6q
繼續看一下轉發該微博的用戶分析:
進一步了解轉發微博的受眾,掌握傳播范圍和深度。
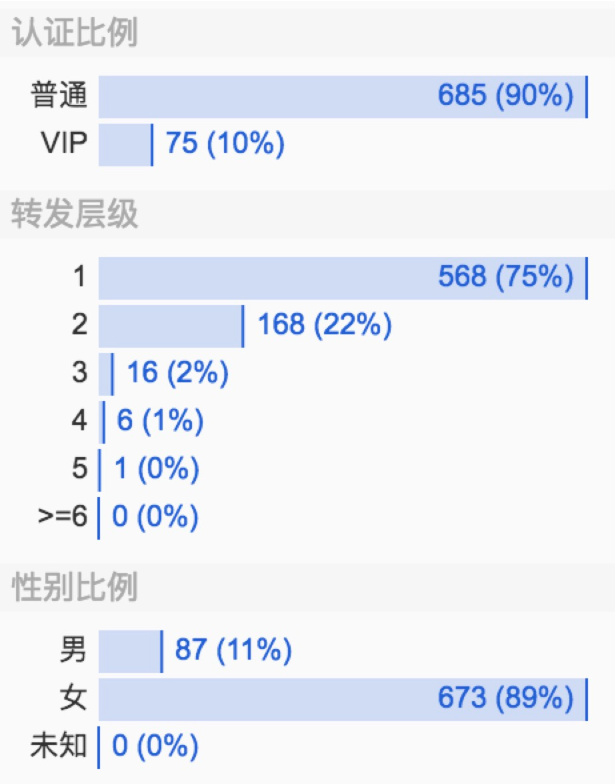
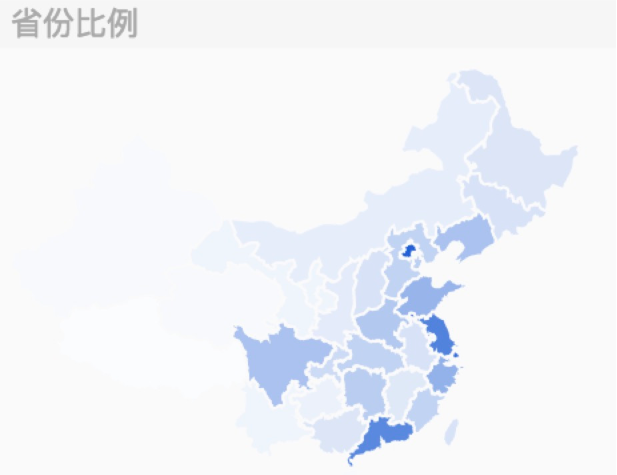
整體看下來,慶余年官微的這條微博90%都是普通用戶的轉發,這部劇轉發層級達到5層,傳播范圍廣,在微博上的討論女性居多(占比89%),大部分集中在一二線城市。
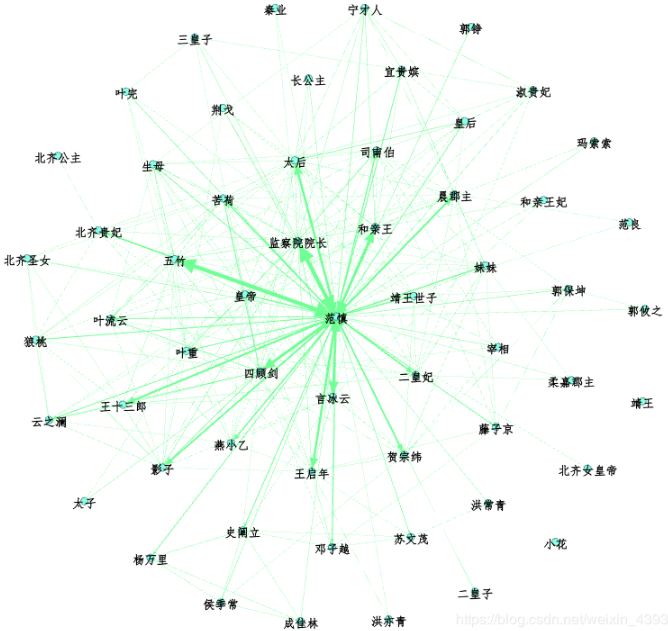
原著人物關系圖譜
如果只看微博,不分析原著,那就不是一個合格的書粉。
于是我去下載了原著畫一下人物關系圖譜。

先給大家看一下原著的人物關系圖譜:
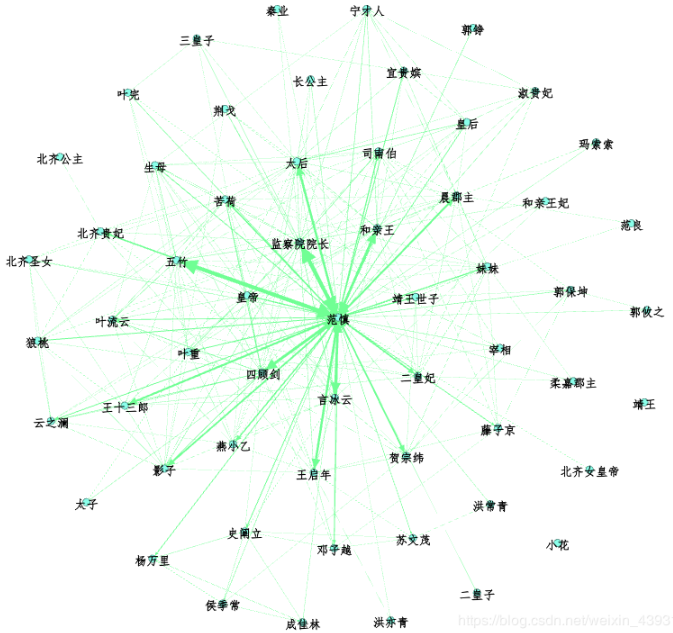
emmm…確實挺丑的,大家可以去Gephi上調整。
首先我需要從原著里洗出人物名,嘗試用jieba分詞庫來清洗:
import jieba
test= 'temp.txt' #設置要分析的文本路徑
text = open(test, 'r', 'utf-8')
seg_list = jieba.cut(text, cut_all=True, HMM=False)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式生成一個適合你的列表
發現并不能很好的切分出所有人名,最簡單的方法是直接準備好人物名稱和他們的別名,這樣就能準確定位到人物關系。
存儲好人物表,以及他們對應的別名(建立成字典)
def synonymous_names(synonymous_dict_path):
with codecs.open(synonymous_dict_path, 'r', 'utf-8') as f:
lines = f.read().split('\n')
for l in lines:
synonymous_dict[l.split(' ')[0]] = l.split(' ')[1]
return synonymous_dict接下來,清理文本數據:
def clean_text(text):
new_text = []
text_comment = []
with open(text, encoding='gb18030') as f:
para = f.read().split('\r\n')
para = para[0].split('\u3000')
for i in range(len(para)):
if para[i] != '':
new_text.append(para[i])
for i in range(len(new_text)):
new_text[i] = new_text[i].replace('\n', '')
new_text[i] = new_text[i].replace(' ', '')
text_comment.append(new_text[i])
return text_comment我們需要進一步統計人物出現次數,以及不同人物間的共現次數:
text_node = []
for name, times in person_counter.items():
text_node.append([])
text_node[-1].append(name)
text_node[-1].append(name)
text_node[-1].append(str(times))
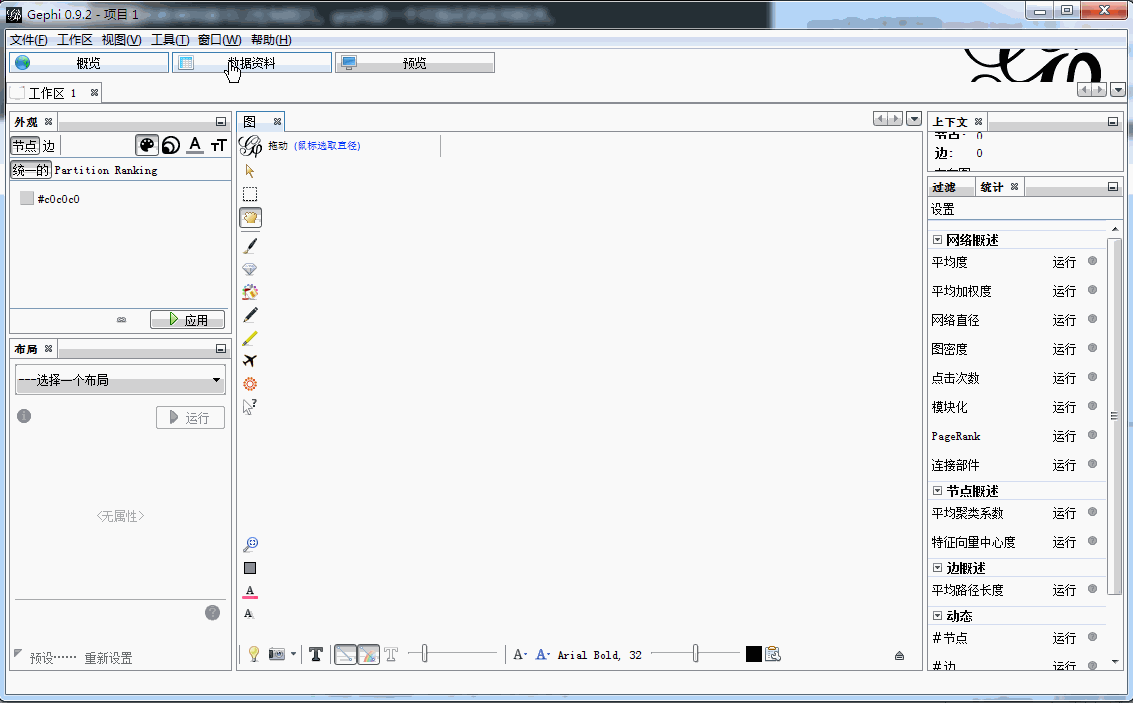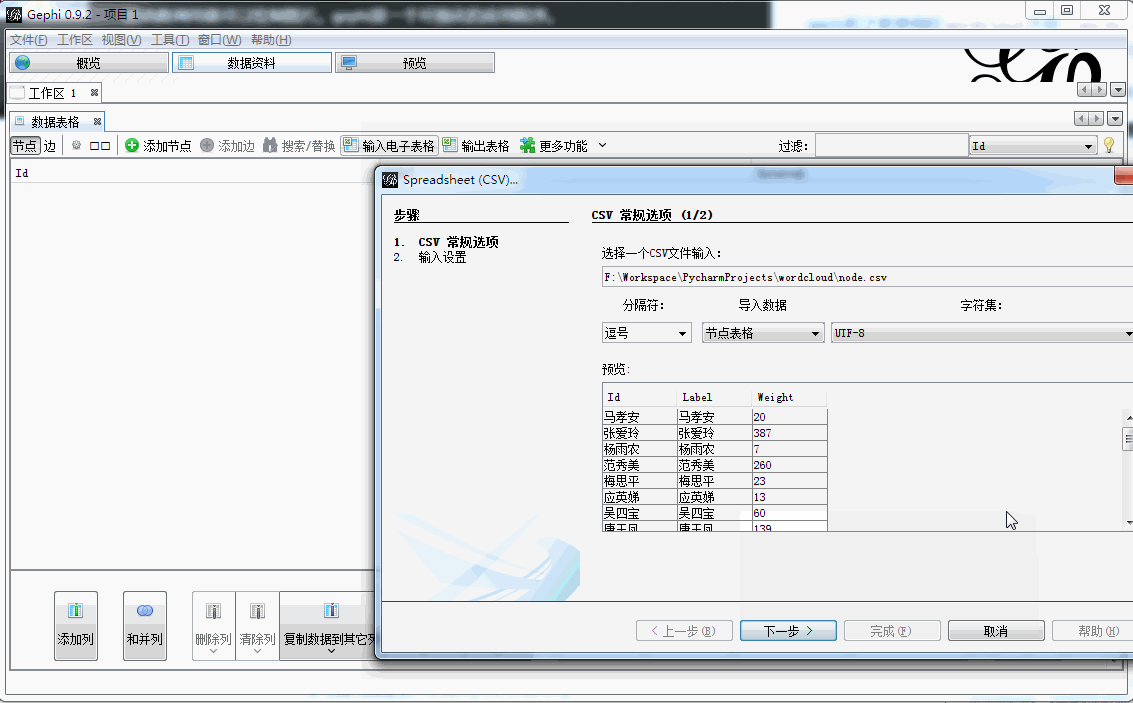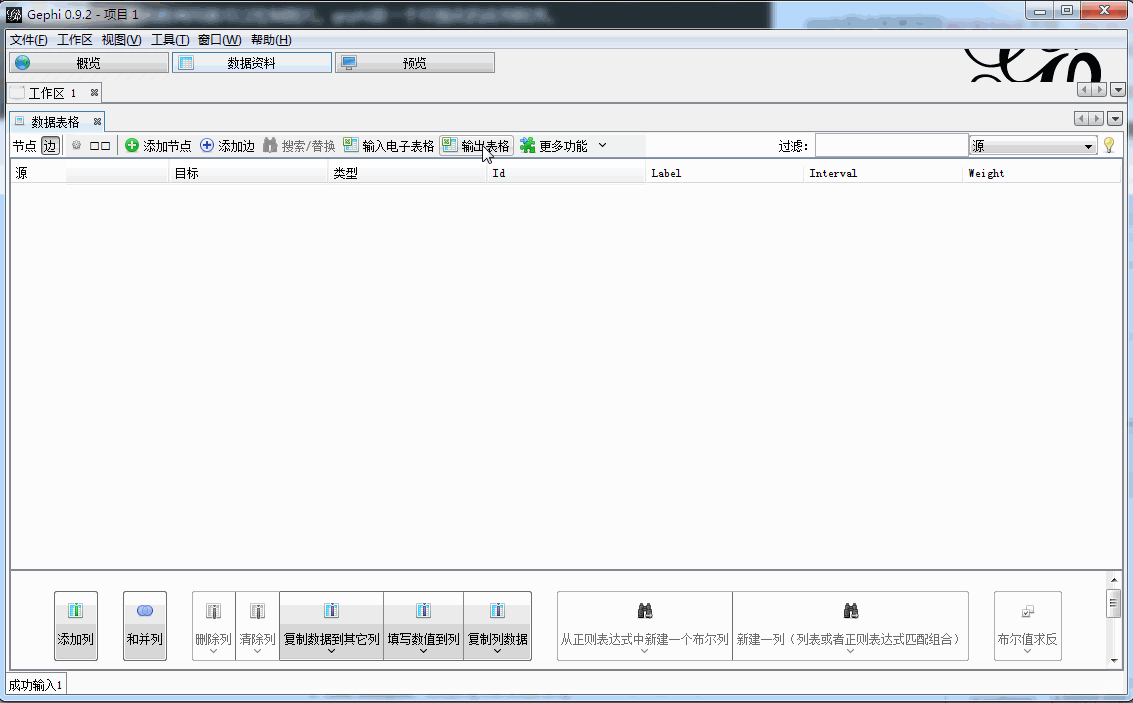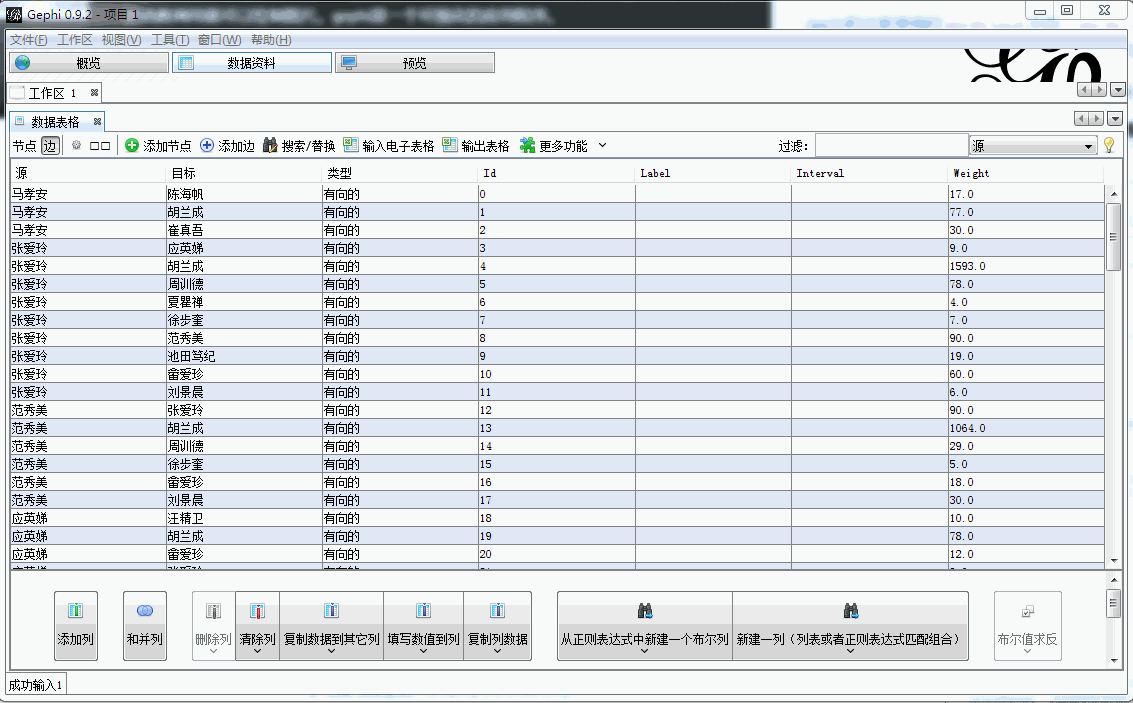
node_data = DataFrame(text_node, columns=['Id', 'Label', 'Weight'])
node_data.to_csv('node.csv', encoding='gbk')結果樣例如下:
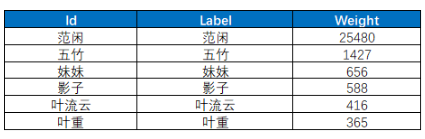
不愧是主角,范閑出現的次數超過了其他人物出現次數的總和,基本每個人都與主角直接或間接地產生影響。
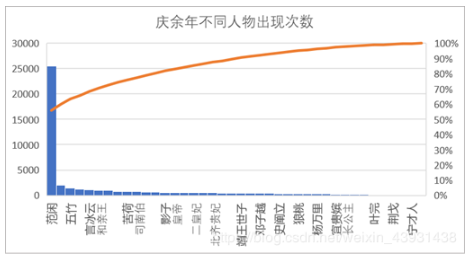
同理可以得到不同人物的邊,具體代碼參考源文件。
接下來需要做的就是利用Gephi繪制人物關系圖譜:
運行結果:
以上是利用Python分析《慶余年》人物圖譜和微博傳播路徑的方法的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





