溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下pyspider的使用方法,相信大部分人都還不怎么了解,因此分享這篇文章給大家學習,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去學習方法吧!
pyspider 的基本使用
本節用一個實例來講解 pyspider 的基本用法。
1. 本節目標
我們要爬取的目標是去哪兒網的旅游攻略,鏈接為 http://travel.qunar.com/travelbook/list.htm,我們要將所有攻略的作者、標題、出發日期、人均費用、攻略正文等保存下來,存儲到 MongoDB 中。
2. 準備工作
請確保已經安裝好了 pyspider 和 PhantomJS,安裝好了 MongoDB 并正常運行服務,還需要安裝 PyMongo 庫,具體安裝可以參考第 1 章的說明。
3. 啟動 pyspider
執行如下命令啟動 pyspider:
pyspider all
運行效果如圖 12-2 所示。

圖 12-2 運行結果
這樣可以啟動 pyspider 的所有組件,包括 PhantomJS、ResultWorker、Processer、Fetcher、Scheduler、WebUI,這些都是 pyspider 運行必備的組件。最后一行輸出提示 WebUI 運行在 5000 端口上。可以打開瀏覽器,輸入鏈接 http://localhost:5000,這時我們會看到頁面,如圖 12-3 所示。

圖 12-3 WebUI 頁面
此頁面便是 pyspider 的 WebUI,我們可以用它來管理項目、編寫代碼、在線調試、監控任務等。
4. 創建項目
新建一個項目,點擊右邊的 Create 按鈕,在彈出的浮窗里輸入項目的名稱和爬取的鏈接,再點擊 Create 按鈕,這樣就成功創建了一個項目,如圖 12-4 所示。

圖 12-4 創建項目
接下來會看到 pyspider 的項目編輯和調試頁面,如圖 12-5 所示。

圖 12-5 調試頁面
左側就是代碼的調試頁面,點擊左側右上角的 run 單步調試爬蟲程序,在左側下半部分可以預覽當前的爬取頁面。右側是代碼編輯頁面,我們可以直接編輯代碼和保存代碼,不需要借助于 IDE。
注意右側,pyspider 已經幫我們生成了一段代碼,代碼如下所示:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = { }
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://travel.qunar.com/travelbook/list.htm', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),}這里的 Handler 就是 pyspider 爬蟲的主類,我們可以在此處定義爬取、解析、存儲的邏輯。整個爬蟲的功能只需要一個 Handler 即可完成。
接下來我們可以看到一個 crawl_config 屬性。我們可以將本項目的所有爬取配置統一定義到這里,如定義 Headers、設置代理等,配置之后全局生效。
然后,on_start() 方法是爬取入口,初始的爬取請求會在這里產生,該方法通過調用 crawl() 方法即可新建一個爬取請求,第一個參數是爬取的 URL,這里自動替換成我們所定義的 URL。crawl() 方法還有一個參數 callback,它指定了這個頁面爬取成功后用哪個方法進行解析,代碼中指定為 index_page() 方法,即如果這個 URL 對應的頁面爬取成功了,那 Response 將交給 index_page() 方法解析。
index_page() 方法恰好接收這個 Response 參數,Response 對接了 pyquery。我們直接調用 doc() 方法傳入相應的 CSS 選擇器,就可以像 pyquery 一樣解析此頁面,代碼中默認是 a[href^=”http”],也就是說該方法解析了頁面的所有鏈接,然后將鏈接遍歷,再次調用了 crawl() 方法生成了新的爬取請求,同時再指定了 callback 為 detail_page,意思是說這些頁面爬取成功了就調用 detail_page() 方法解析。這里,index_page() 實現了兩個功能,一是將爬取的結果進行解析,二是生成新的爬取請求。
detail_page() 同樣接收 Response 作為參數。detail_page() 抓取的就是詳情頁的信息,就不會生成新的請求,只對 Response 對象做解析,解析之后將結果以字典的形式返回。當然我們也可以進行后續處理,如將結果保存到數據庫。
接下來,我們改寫一下代碼來實現攻略的爬取吧。
5. 爬取首頁
點擊左欄右上角的 run 按鈕,即可看到頁面下方 follows 便會出現一個標注,其中包含數字 1,這代表有新的爬取請求產生,如圖 12-6 所示。

圖 12-6 操作示例
左欄左上角會出現當前 run 的配置文件,這里有一個 callback 為 on_start,這說明點擊 run 之后實際是執行了 on_start() 方法。在 on_start() 方法中,我們利用 crawl() 方法生成一個爬取請求,那下方 follows 部分的數字 1 就代表了這一個爬取請求。
點擊下方的 follows 按鈕,即可看到生成的爬取請求的鏈接。每個鏈接的右側還有一個箭頭按鈕,如圖 12-7 所示。

圖 12-7 操作示例
點擊該箭頭,我們就可以對此鏈接進行爬取,也就是爬取攻略的首頁內容,如圖 12-8 所示。

圖 12-8 爬取結果
上方的 callback 已經變成了 index_page,這就代表當前運行了 index_page() 方法。index_page() 接收到的 response 參數就是剛才生成的第一個爬取請求的 Response 對象。index_page() 方法通過調用 doc() 方法,傳入提取所有 a 節點的 CSS 選擇器,然后獲取 a 節點的屬性 href,這樣實際上就是獲取了第一個爬取頁面中的所有鏈接。然后在 index_page() 方法里遍歷了所有鏈接,同時調用 crawl() 方法,就把這一個個的鏈接構造成新的爬取請求了。所以最下方 follows 按鈕部分有 217 的數字標記,這代表新生成了 217 個爬取請求,同時這些請求的 URL 都呈現在當前頁面了。
再點擊下方的 web 按鈕,即可預覽當前爬取結果的頁面,如圖 12-9 所示。

圖 12-9 預覽頁面
當前看到的頁面結果和瀏覽器看到的幾乎是完全一致的,在這里我們可以方便地查看頁面請求的結果。
點擊 html 按鈕即可查看當前頁面的源代碼,如圖 12-10 所示。
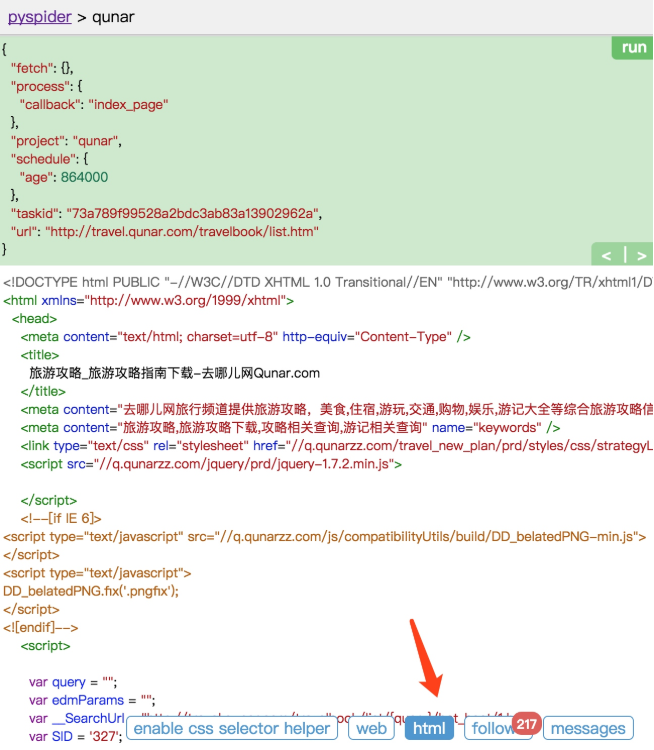
圖 12-10 頁面源碼
如果需要分析代碼的結構,我們可以直接參考頁面源碼。
我們剛才在 index_page() 方法中提取了所有的鏈接并生成了新的爬取請求。但是很明顯要爬取的肯定不是所有鏈接,只需要攻略詳情的頁面鏈接就夠了,所以我們要修改一下當前 index_page() 里提取鏈接時的 CSS 選擇器。
接下來需要另外一個工具。首先切換到 Web 頁面,找到攻略的標題,點擊下方的 enable css selector helper,點擊標題。這時候我們看到標題外多了一個紅框,上方出現了一個 CSS 選擇器,這就是當前標題對應的 CSS 選擇器,如圖 12-11 所示。

圖 12-11 CSS 工具
在右側代碼選中要更改的區域,點擊左欄的右箭頭,此時在上方出現的標題的 CSS 選擇器就會被替換到右側代碼中,如圖 12-12 所示。

圖 12-12 操作結果
這樣就成功完成了 CSS 選擇器的替換,非常便捷。
重新點擊左欄右上角的 run 按鈕,即可重新執行 index_page() 方法。此時的 follows 就變成了 10 個,也就是說現在我們提取的只有當前頁面的 10 個攻略,如圖 12-13 所示。

圖 12-13 運行結果
我們現在抓取的只是第一頁的內容,還需要抓取后續頁面,所以還需要一個爬取鏈接,即爬取下一頁的攻略列表頁面。我們再利用 crawl() 方法添加下一頁的爬取請求,在 index_page() 方法里面添加如下代碼,然后點擊 save 保存:
next = response.doc('.next').attr.href
self.crawl(next, callback=self.index_page)利用 CSS 選擇器選中下一頁的鏈接,獲取它的 href 屬性,也就獲取了頁面的 URL。然后將該 URL 傳給 crawl() 方法,同時指定回調函數,注意這里回調函數仍然指定為 index_page() 方法,因為下一頁的結構與此頁相同。
重新點擊 run 按鈕,這時就可以看到 11 個爬取請求。follows 按鈕上會顯示 11,這就代表我們成功添加了下一頁的爬取請求,如圖 12-14 所示。

圖 12-14 運行結果
現在,索引列表頁的解析過程我們就完成了。
6. 爬取詳情頁
任意選取一個詳情頁進入,點擊前 10 個爬取請求中的任意一個的右箭頭,執行詳情頁的爬取,如圖 12-15 所示。

圖 12-15 運行結果
切換到 Web 頁面預覽效果,頁面下拉之后,頭圖正文中的一些圖片一直顯示加載中,如圖 12-16 和圖 12-17 所示。

圖 12-16 預覽結果

圖 12-17 預覽結果
查看源代碼,我們沒有看到 img 節點,如圖 12-18 所示。

圖 12-18 源代碼
出現此現象的原因是 pyspider 默認發送 HTTP 請求,請求的 HTML 文檔本身就不包含 img 節點。但是在瀏覽器中我們看到了圖片,這是因為這張圖片是后期經過 JavaScript 出現的。那么,我們該如何獲取呢?
幸運的是,pyspider 內部對接了 PhantomJS,那么我們只需要修改一個參數即可。
我們將 index_page() 中生成抓取詳情頁的請求方法添加一個參數 fetch_type,改寫的 index_page() 變為如下內容:
def index_page(self, response):
for each in response.doc('li> .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page, fetch_type='js')
next = response.doc('.next').attr.href
self.crawl(next, callback=self.index_page)接下來,我們來試試它的抓取效果。
點擊左欄上方的左箭頭返回,重新調用 index_page() 方法生成新的爬取詳情頁的 Request,如圖 12-19 所示。

圖 12-19 爬取詳情
再點擊新生成的詳情頁 Request 的爬取按鈕,這時我們便可以看到頁面變成了這樣子,如圖 12-20 所示。

圖 12-20 運行結果
圖片被成功渲染出來,這就是啟用了 PhantomJS 渲染后的結果。只需要添加一個 fetch_type 參數即可,這非常方便。
最后就是將詳情頁中需要的信息提取出來,提取過程不再贅述。最終 detail_page() 方法改寫如下所示:
def detail_page(self, response):
return {
'url': response.url,
'title': response.doc('#booktitle').text(),
'date': response.doc('.when .data').text(),
'day': response.doc('.howlong .data').text(),
'who': response.doc('.who .data').text(),
'text': response.doc('#b_panel_schedule').text(),
'image': response.doc('.cover_img').attr.src
}我們分別提取了頁面的鏈接、標題、出行日期、出行天數、人物、攻略正文、頭圖信息,將這些信息構造成一個字典。
重新運行,即可發現輸出結果如圖 12-21 所示。

圖 12-21 輸出結果
左欄中輸出了最終構造的字典信息,這就是一篇攻略的抓取結果。
7. 啟動爬蟲
返回爬蟲的主頁面,將爬蟲的 status 設置成 DEBUG 或 RUNNING,點擊右側的 Run 按鈕即可開始爬取,如圖 12-22 所示。

圖 12-22 啟動爬蟲
在最左側我們可以定義項目的分組,以方便管理。rate/burst 代表當前的爬取速率,rate 代表 1 秒發出多少個請求,burst 相當于流量控制中的令牌桶算法的令牌數,rate 和 burst 設置的越大,爬取速率越快,當然速率需要考慮本機性能和爬取過快被封的問題。process 中的 5m、1h、1d 指的是最近 5 分、1 小時、1 天內的請求情況,all 代表所有的請求情況。請求由不同顏色表示,藍色的代表等待被執行的請求,綠色的代表成功的請求,黃色的代表請求失敗后等待重試的請求,紅色的代表失敗次數過多而被忽略的請求,這樣可以直觀知道爬取的進度和請求情況,如圖 12-23 所示。

圖 12-23 爬取情況
點擊 Active Tasks,即可查看最近請求的詳細狀況,如圖 12-24 所示。

圖 12-24 最近請求
點擊 Results,即可查看所有的爬取結果,如圖 12-25 所示。

圖 12-25 爬取結果
點擊右上角的按鈕,即可獲取數據的 JSON、CSV 格式。
以上是pyspider的使用方法的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





