溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python進行爬取酷狗音樂的方法,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
功能概述
讓用戶輸入要搜索的音樂名,然后把所有的音樂以及每一個音樂對應的信息展示給用戶。再詢問用戶要不要下載任何音樂,如果要,則讓用戶輸入音樂對應的id號來下載(支持批量下載)。
找出思路
首先,在獲取多首歌曲的信息和下載地址之前,我們需要知道如何獲取一首歌的下載地址。
打開www.kugou.com ,在搜索欄里輸入你想要查找的歌曲名。按下回車。切換網頁之后,點進一首歌曲的播放頁。按下F12,調出開發者工具。選擇network,然后點all。可以看到,目前是沒有任何東西顯示的。因為所有的文件已經在你打開開發者工具的時候加載完了,此時此刻,你只需要F5刷新一下網頁。好了,現在
你就能看到類似這樣的頁面。
可以看到什么js文件啊,png文件啊,音頻文件啊,都沒有!因為我們在調出開發者工具之前,網站已經加載完了文件,這個時候,我們只需要按下F5刷新一下網站。好了,所有的文件加載出來了。進入到一個叫做index.php?的文件,然后進入到這個文件的地址。
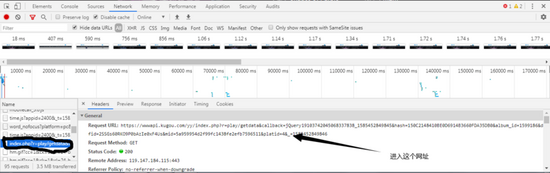
進入這個文件地址之后,這實際上就是音樂的信息(為了方便,我在文章后面就說是信息地址)。我們還可以看到一個叫play_url的東西,這個play_url就是音頻的mp3文件地址,可以看到,這些play_url都是把/變成了/。我們不用擔心這個,因為網址輸入欄會自動幫我們調整成/,但是在用代碼實現爬蟲的時候,我們就需要把/變成/了。但短時間內,我們先不用管這個。讓我們進入到這個網址,咦?這不是我們剛剛播放的音樂嗎?
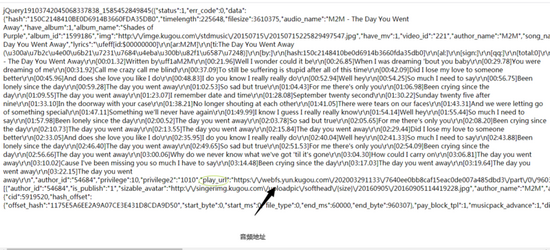
成功之后,我們就有了更大的信心和思路去爬蟲。我們只要把每首歌曲的信息地址找出來,然后用正則表達式把每首歌曲的信息和音樂地址獲取出來。再一次用爬蟲獲取到音樂的二進制編碼,保存在本地。
那我們如何獲取每首歌的信息地址呢?通過拼接地址!讓我們看這兩首歌的url有啥不同,你就知道了。
Faded - https://wwwapi.kugou.com/yy/i...
卡路里 - https://wwwapi.kugou.com/yy/i...
可以看到除了hash值以外的東西,就沒有啥區別了。也就是說我們只需要通過 https://wwwapi.kugou.com/yy/i...
來拼接每首歌的信息地址就行了。那歌曲的hash要去那里找呢?回到酷狗的音樂搜索欄,隨便搜一首歌按下回車。可以看到這里有好多首歌。F12-NETWORK-ALL-F5,我們找出一個這樣的文件。
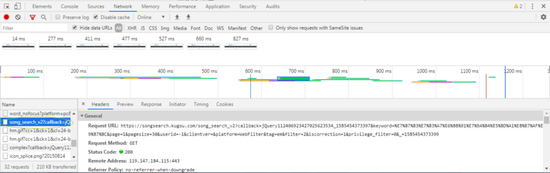
我們進入這個網址,就可以看到剛剛所有歌曲的hash。那問題又來了,我們又要怎樣獲取到這個hash信息網址呢?這個太簡單了,只需要通過 https://songsearch.kugou.com/...
拼接網址就行。
這個搜索的歌曲名,我們代碼用input讓用戶輸入歌曲名就行了。那么,你找到思路了嗎?
思路:拼接出hash信息網址,正則表達式獲取到所有歌曲的hash,再拼接出單首歌曲的url。最后再一次用正則表達式獲取歌曲的play_url即可。
開始寫代碼
首先導入我們的requests和re正則表達式庫。re用來找出音樂的信息和下載地址,requests負責獲取文本和下載音樂。
import requestsimport re
我們還要設置一些變量,這些變量在后面可是會派上大用場的。
timer = 0song_urls = {}names = {}
我們不是要拼接出多首歌曲的信息網址嗎?那我們就先要讓用戶輸入歌曲名。接著再拼。
songs = input("請輸入歌曲名:")
url = 'https://songsearch.kugou.com/song_search_v2?callback=jQuery112409090559630919017_1585358668138&keyword=%s&page=1&pagesize=30&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1585358668140'%songs現在,我們就可以用requests請求文本了!由于這個網址是get請求的而且我們請求的是文本,所以,我們也要用方法requests.get().text方法。
texts = requests.get(url).text
接著,你可以試著打印一下文本。打印出來的文本和我們拼接的網址的內容毫無區別(我這里就不打印了,等下python卡死就完了)
在這些文本里,我們可以獲取到每首歌的hash值。用正則表達式查找就行了。
song_hashes = re.findall('"FileHash":"(.*?)"',texts)
打印一下song_hashes,可以看到,他是個列表。所以我們要進行for遍歷。
for i in song_hashes:
information_url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19104610954889760035_1585364074033&hash=%s&album_id=0&dfid=2SSGs60RKO9P0bAzIe0xF4Us∣=5a959954d2f99fc1438fe2efb7596511&platid=4&_=1585364074034'%i
information = requests.get(information_url).text
song_url = re.findall('"play_url":"(.*?)"',information)
song_names = bytes(re.findall('"audio_name":"(.*?)"',information)[0],encoding='ascii').decode('unicode-escape')
singers = bytes(re.findall('"author_name":"(.*?)"',information)[0],encoding='ascii').decode('unicode-escape') if song_names not in names.values():
names[str(timer)] = song_names print("%d.%s"%(timer,song_names)) print("作者:%s"%singers) print()
timer += 1 if song_url[0] not in song_urls.values():
song_urls[str(timer-1)] = song_url[0]上段代碼中,我們進行了每個hash的拼接操作,然后我們在從單首歌曲的信息文本里找到了音樂名和作者和下載地址。由于音樂名和作者是進行ascii編碼過的,所以我們也要進行一個解碼。由于歌曲名和歌手有時候會重復打印,所以我們每一次打印音樂和作者之前,都會把音樂和作者名加入到一個字典。每一次打印都會進行一次是否存在字典的判斷。字典的key就由我們的timer變量的變化進行改變key名。另外,我們還把每首歌的下載地址保存到了song_urls字典里。
打印了音樂信息之后,就要詢問用戶要下載那首歌了。
print('輸入n就不下載,若要下載多首歌曲,請用英文符號","隔開')
choice = input('請輸入要下載歌曲的編號:').split(',')if choice == "n": exit()else:
path = input("請輸入要保存的路徑:") for i in choice:
song_url = song_urls[i].replace('\\/','/')
song = requests.get(song_url).content
save_name = names[i]
with open(path + '/' + save_name + '.mp3','wb') as f:
f.write(song)
print("保存完成!")按以前的做法,用requests.get().content把音樂轉換成二進制文件再進行保存。在get之前,我們還需要把網址的亂七八糟的\/變成/。之后,就能保存下來了!
我們就拿一首叫做the day you went away的歌試一下
代碼實現效果:

程序的不足
酷狗每隔一段時間都會弄個滑動驗證碼,這個時候我們的程序就不能獲取到數據。這種情況,用selenium就可以輕松解決。
完整代碼:
#導入庫
import requests
import re
import os
#設置好一些變量
timer = 0 #設置一個計算歌曲順序的機器
song_urls = {}
names = {}
songs = input("請輸入歌曲名:")url = 'https://songsearch.kugou.com/song_search_v2?callback=jQuery112409090559630919017_1585358668138&keyword=%s&page=1&pagesize=30&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1585358668140'%songs
texts = requests.get(url).text
song_hashes = re.findall('"FileHash":"(.*?)"',texts)print("請稍等...")for i in song_hashes:
information_url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19104610954889760035_1585364074033&hash=%s&album_id=0&dfid=2SSGs60RKO9P0bAzIe0xF4Us∣=5a959954d2f99fc1438fe2efb7596511&platid=4&_=1585364074034'%i
information = requests.get(information_url).text
song_url = re.findall('"play_url":"(.*?)"',information)
song_names = bytes(re.findall('"audio_name":"(.*?)"',information)[0],encoding='ascii').decode('unicode-escape')
singers = bytes(re.findall('"author_name":"(.*?)"',information)[0],encoding='ascii').decode('unicode-escape') if song_names not in names.values():
names[str(timer)] = song_names print("%d.%s"%(timer,song_names)) print("作者:%s"%singers) print()
timer += 1 if song_url[0] not in song_urls.values():
song_urls[str(timer-1)] = song_url[0]print('輸入n就不下載,若要下載多首歌曲,請用英文符號","隔開')
choice = input('請輸入要下載歌曲的編號:').split(',')if choice == "n": exit()else:
path = input("請輸入要保存的路徑:")
has_path = os.path.exists(path) while has_path == False: print("路徑不存在!!")
path = input("請輸入要保存的路徑:")
has_path = os.path.exists(path) for i in choice:
song_url = song_urls[i].replace('\\/','/')
song = requests.get(song_url).content
save_name = names[i]
with open(path + '/' + save_name + '.mp3','wb') as f: f.write(song) print("保存完成!")看完了這篇文章,相信你對Python進行爬取酷狗音樂的方法有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





