溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
—舉例(學生排課)—
正常思路的處理方法和優化過后的處理方法:
比如說給學生排課。學生和課程是一個多對多的關系。

按照正常的邏輯 應該有一個關聯表來維護 兩者之間的關系。

現在,添加一個約束條件用于校驗。如:張三上學期學過的課程,在排課的時候不應該再排這種課程。
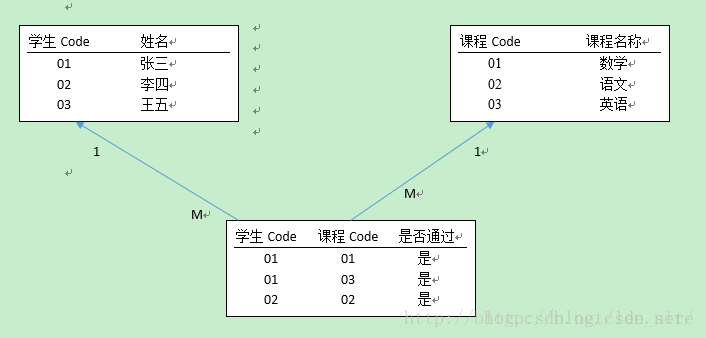
所以需要出現一個約束表(即:歷史成績表)。
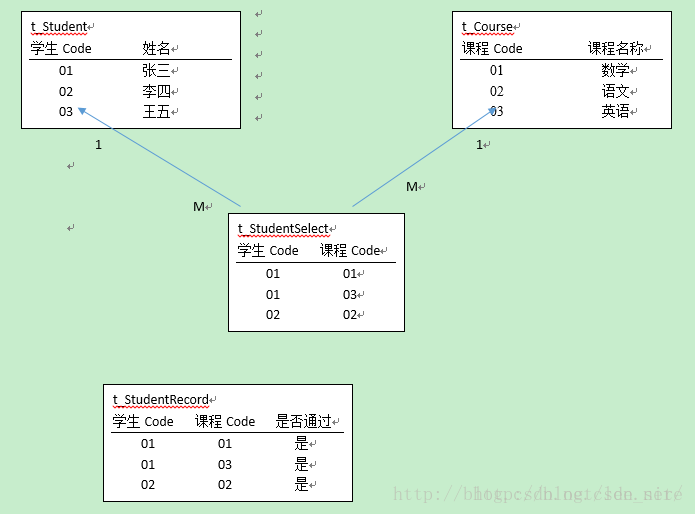
即:學生選課表,需要學生成績表作為約束。
—方案一:正常處理方式—
當一個學生進行再次選課的時候。需要查詢學生選課表看是否已經存在。
即有如下校驗:
//查詢 學生code和課程code分別為 A 和 B的數據是否存在
//list集合中存放 學生選課記錄全部的數據
List<StudentRecordEntity> ListStudentRecord=service.findAll();
//查詢數據,看是否已經存在
StudentRecordEntity enSr=ListStudentRecord.find(s=>s.學生Code==A && s.課程Code==B);
If(enSr==null){
//學生沒有選該課程
//....
}else{
//學生已經選過該課程
//....
}
對于上面這種代碼的寫法,非常的簡練。而且也非常易懂。
首先,假設有5000個學生,100門課程。那么對于學生選課的數據集中,數據量將是5000*100.數據量會是十萬級別的數量級。
在十萬條數據中,查詢學生=A課程=B的一條記錄。執行的效率會很低。因為find方法的查詢也就是where查詢,即通過遍歷數據集合來查找。
所以,使用上面的代碼。在數據量逐漸增長的過程中,程序的執行效率會大幅度下降。
ps:數據量增長,在該例子中并不太適合。例子可能不太恰當。總之,大概就是這個意思。)
—方案二:使用內存進行優化效率—
這種做法,需要消耗內存。或者說把校驗的工作向前做(數據的初始化,在部署系統的過程中進行)。即:在頁面加載的時候數據只調用提供的public方法進行校驗。
//學生Code 到 數組索引
Private Dictionary<string,int> _DicStudentCodeToArrayIndex;
//課程Code 到 數據索引
Private Dictionary<string,int> _DicCourseCodeToArrayIndex;
//所有學生
List<StudentEntity> ListStudent=service.findAllStudent();
//所有課程
List<CourseEntity> ListCourse=service.findAllCourse();
//所有 學生選課記錄
List<StudentCourseEntity> ListStudentRecord=service.finAll();
Private int[,] _ConnStudentRecord=new int[ListStudent.count,ListCourse.count];
//構造 學生、課程的 數組 用于快速查找字典索引
Private void GenerateDic(){
For(int i=0;
i<ListStudent.Count;
i++)
_DicStudentCodeToArrayIndex.Add(ListStudent[i].code,i)
}
For(int i=0;
i<ListCourse.Count;
i++){
_DicCourseCodeToArrayIndex.Add(ListCourse[i].code,i)
}
}
//構造學生選課 匹配的 二維數組。 1表示 學生已選該課程
Private void GenerateArray(){
Foreach(StudentRecordEntity sre in ListStudentRecord){
int x=_DicStudentCodeToArrayIndex[sre.學生Code];
int y=DicCourseCodeToArrayIndex[sre.課程Code];
ConnStudentRecord[x,y]=1;
}
}
//對外公開的方法:根據學生Code 和課程Code 查詢 選課記錄是否存在
/// <returns>返回1 表示存在。返回0表示不存在</returns>
Public void VerifyRecordByStudentCodeAndCourseCode(String pStudentCode,String pCourseCode){
int x=_DicStudentCodeToArrayIndex[pStudentCode];
int y=_DicCourseCodeToArrayIndex[pCourseCode];
Return ConnStudentRecord[x,y];
}
—性能分析—
分析一下第二種方案的表象。
1、方法很多。
2、使用的變量很多。
首先要說一下。該優化的目的,是提高學生在選課的時候,所出現的卡頓現象(校驗數據量大)。
分別對以上兩種方案進行分析:
假設學生為N,課程為M
第一種方案:
時間復雜度很容易計算第一種方案最小為O(NM)
第二種方案:
1、代碼多。但是給用戶提供的只有一個VerifyRecordByStudentCodeAndCourseCode方法。
2、變量多,因為該方案就是要使用內存提高效率的。
這個方法執行流程:1、在Dictionary中使用Code找Index2、使用Index查詢數組。
第一步中,Dictionary中查詢是使用的Hash查找算法。時間復雜度為O(lgN)時間比較快。第二步,時間復雜度為O(1),因為數組是連續的使用索引會直接查找對應的地址。
所以,使用第二種方案進行校驗,第二種方案時間復雜度為O(lgN+lgM)
—總結—
通過上面的分析,可以看出,內存的付出是可以提高程序的執行效率的。以上只是一個例子,優化的好壞取決于使用的數據結構。
以上就是本文關于Java性能優化之數據結構實例代碼的全部內容,希望對大家有所幫助。感興趣的朋友可以繼續參閱本站其他相關專題,如有不足之處,歡迎留言指出。感謝朋友們對本站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





