溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文實例講述了Java集合定義與用法。分享給大家供大家參考,具體如下:
java集合大體可分為三類,分別是Set、List和Map,它們都繼承了基類接口Collection,Collection接口定義了眾多操作集合的基本方法,如下:
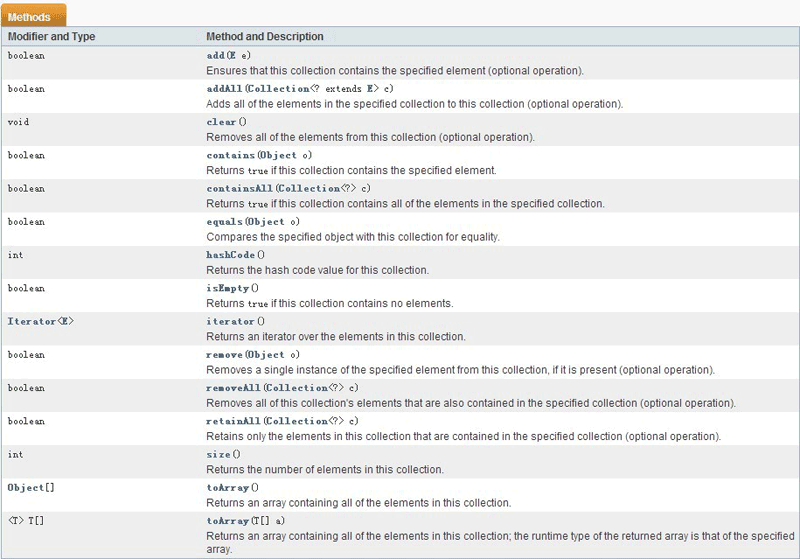
為了訪問Collection集合,不得不去了解Iterator接口。該接口很簡單,主要用于定義訪問集合的方法,如下:

所以上述的三大類子集合必定都繼承了上面2個接口。其中Set集合要求元素不重復,且內部無序,所以訪問時只能根據元素值來訪問;List內部為動態數組,支持有序,元素也可重復,所以往往有index;Map所代表的集合是具有Key-Value的映射關系的集合,如哈希表。
import java.util.Collection;
import java.util.HashSet;
public class TestSet {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static void main(String[] args) {
Collection c1 = new HashSet();
Person p = new Person();
c1.add(p);
c1.add(p);
System.out.println(c1);
Collection c2 = new HashSet();
String str1 = new String("123");
String str2 = new String("123");
c2.add(str1);
c2.add(str2);
System.out.println(c2);
}
}
class Person {
public Person() {
}
public Person(String name) {
this.name = name;
}
public String name;
}
運行輸出:
[demo.Person@1db9742]
[123]
第一次添加了倆次p對象,集合不會重復添加,所以輸出了[Person@1db9742],這很合理。但是第二次明明new了兩個字符串,str1和str2的引用肯定是不同的,那為什么程序還是會認為是相同的元素呢。查找add(E e)的源碼,找到了其中的關鍵部分,如下
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
這一句
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
表明,當兩個對象的哈希值相等并且對象的equals方法返回真時,則認為兩個對象是相同的,并不會進行后面的addEntry操作,即不會添加至集合。
這也就難怪String str1=new String("123")和String str2=new String("123");被認為是同一個對象了,因為String在做equals的時候恰好很特殊,只要值相等,則euqals就返回真。
為了測試源碼是否真的是這么執行的,改寫程序如下:
import java.util.Collection;
import java.util.HashSet;
public class TestSet {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static void main(String[] args) {
Collection c1 = new HashSet();
c1.add(new A());
c1.add(new A());
c1.add(new B());
c1.add(new B());
c1.add(new C());
c1.add(new C());
System.out.println(c1);
}
}
class A {
@Override
public boolean equals(Object obj) {
return true;
}
@Override
public int hashCode() {
return 1;
}
}
class B {
@Override
public int hashCode() {
return 1;
}
}
class C {
@Override
public boolean equals(Object obj) {
return true;
}
}
輸出:
[demo.A@1, demo.B@1, demo.B@1, demo.C@1db9742, demo.C@106d69c]
可以看到,B和C的對象都沒有被集合認為是同一個對象,而A類中重寫的哈希值和equals永遠相等,導致A類new出的匿名對象也是相等的,故只添加了一個。
import java.util.Collection;
import java.util.Iterator;
import java.util.HashSet;
public class TestSet {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static void main(String[] args) {
Collection coll = new HashSet();
coll.add(new Person("f"));
coll.add(new Person("l"));
coll.add(new Person("y"));
System.out.println(coll);// a
Iterator it = coll.iterator();// b
while (it.hasNext()) {
Person p = (Person) it.next();
if (p.name.equals("f")) {
p = new Person();// c
}
}
Iterator it1 = coll.iterator();// d
while (it1.hasNext()) {
Person p = (Person) it1.next();
System.out.println(p.name);
}
System.out.println(coll);
}
}
class Person {
public Person() {
}
public Person(String name) {
this.name = name;
}
public String name;
}
運行輸出:
[demo.Person@52e922, demo.Person@1db9742, demo.Person@106d69c]
y
f
l
[demo.Person@52e922, demo.Person@1db9742, demo.Person@106d69c]
代碼輸出表明,HashSet集合的元素并不是有序的,另外在代碼c處取出了元素后,為該元素重新賦值,而后輸出發現集合并沒有改變,這說明iterator迭代器在提供next的方法里應該是類似于copy的技術,目的就是防止在遍歷set集合的時候元素被改變。
List作為Collection的子接口,自然可以調用父接口的基本方法,但由于List集合元素是有序的,所以List接口在父接口的基礎上又增加了些方法。這些方法的作用與類父接口類似,只是都會增加一個index參數做為索引。
List中最常用的就是ArrayList,它在Vector的基礎上做了許多改進,下面代碼將展示List的基本操作用法:
import java.util.List;
import java.util.ArrayList;
import java.util.ListIterator;
public class TestList {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static void main(String[] args) {
// 向list中添加不同類型的元素,會自動裝箱
List list = new ArrayList();
list.add(1);
list.add("123");
list.add(3.14f);
// 列表元素:[1, 123, 3.14]
System.out.println("列表元素:" + list);
// 清除列表
list.clear();
list.add("我");
list.add("們");
list.add("交");
list.add("個");
list.add("朋");
list.add("友");
list.add("吧");
// 列表元素:[我, 們, 交, 個, 朋, 友, 吧]
System.out.println("列表元素:" + list);
List sub1 = list.subList(0, list.size() / 2);
// 子列表元素:[我, 們, 交]
System.out.println("子列表元素:" + sub1);
// 從list中刪除sub
sub1.removeAll(list);
// 列表元素:[個, 朋, 友, 吧]
System.out.println("列表元素:" + list);
// 添加至頭
List sub2 = new ArrayList();
sub2.add("我");
sub2.add("們");
sub2.add("交");
System.out.println("子列表元素:" + sub2);
// 在list中添加sub2
list.addAll(0, sub2);
System.out.println("列表元素:" + list);
// 遍歷操作
ListIterator iter = list.listIterator();
System.out.println("--正向遍歷--");
while (iter.hasNext()) {
System.out.println(iter.next());
}
System.out.println("--反向遍歷--");
while (iter.hasPrevious()) {
System.out.println(iter.previous());
}
}
}
運行輸出:
列表元素:[1, 123, 3.14]
列表元素:[我, 們, 交, 個, 朋, 友, 吧]
子列表元素:[我, 們, 交]
列表元素:[個, 朋, 友, 吧]
子列表元素:[我, 們, 交]
列表元素:[我, 們, 交, 個, 朋, 友, 吧]
--正向遍歷--
我
們
交
個
朋
友
吧
--反向遍歷--
吧
友
朋
個
交
們
我
List就像是一個動態且元素類型可不一的數組,它不僅具有iterator迭代器,而且還有listIterator,后者就像數組一樣,支持正向和反向遍歷。
Map是具有映射關系的集合,key做為主鍵,可以索引到唯一的value,key和value都可以是對象。如果單獨取出Map里的所有值的話,Map看起來就像是Set,而又由于它較之Set又具有索引功能,所以又似乎有些List的影子。實際上,Map的key必須實現equals和hashCode方法,這也就解釋了為什么可以將一個對象的引用做為key了(實際上是計算這個對象的hashCode做為主鍵),因此不能將同一個對象的引用存入某一個Map中。HashSet實現了Set接口,ArrayList實現了List接口,那么單從命名上就能得知,HashMap肯定實現了Map接口,Map接口的功能如下,
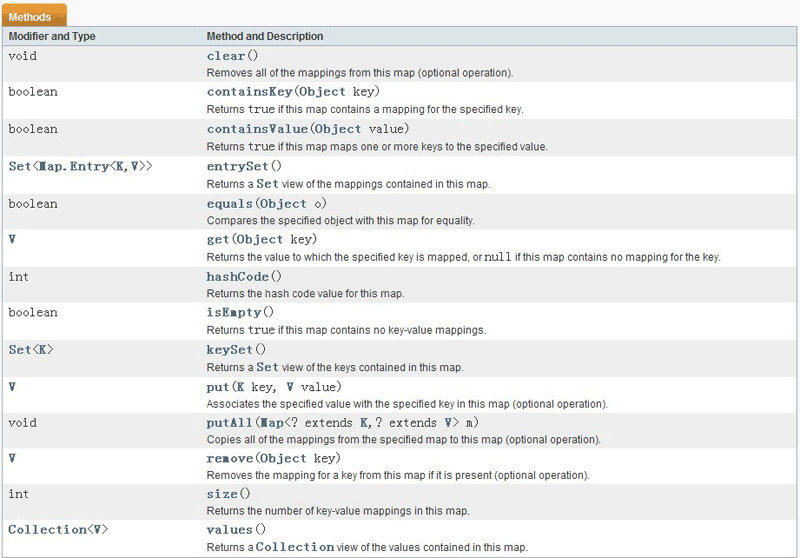
在HashSet和ArrayList都有一個訪問迭代器的方法iterator(),在Set接口中卻沒有,畢竟Set是key-value組合,取而代之的是一個keySet()方法,用以返回一個實現了Set接口的對象,從而又可以進行iterator的操作。
基本操作如下:
import java.util.HashMap;
import java.util.Iterator;
public class TestMap {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static void main(String[] args) {
HashMap hash = new HashMap();
hash.put("1", "我");
hash.put("2", "們");
// 主鍵可為null,但只能有一個null值的主鍵
hash.put(null, null);
// 值可以為null,可以有很多個值為null
hash.put("3", null);
hash.put("4", null);
System.out.println("直接遍歷:" + hash);
System.out.println("----keySey遍歷----:");
for (Object key : hash.keySet()) {
System.out.println("key:" + key + " value:" + hash.get(key));
}
System.out.println("----iterator遍歷----:");
Iterator iter = hash.keySet().iterator();
while (iter.hasNext()) {
String key = (String) iter.next();
System.out.println("key:" + key + " value:" + hash.get(key));
}
}
}
輸出:
直接遍歷:{null=null, 1=我, 2=們, 3=null, 4=null}
----keySey遍歷----:
key:null value:null
key:1 value:我
key:2 value:們
key:3 value:null
key:4 value:null
----iterator遍歷----:
key:null value:null
key:1 value:我
key:2 value:們
key:3 value:null
key:4 value:null
HashMap可以有空key,但是只能有一個,,這符合唯一主鍵的原則,并且若主鍵重復了,則會覆蓋之前的相同主鍵。而值卻沒有限制,有多少個null都可以。此外,在使用HashMap的時候還需要注意下面兩點:
1.HashMap是非線程安全的,而Hashtable是線程安全的。
對于各種集合的各種操作,其實可以依賴于Collections類,該類提供了許多靜態操作集合的方法,其中就可以將一個普通集合封裝為線程安全的集合,如下
Collection c=Collections.synchronized(new ArrayList());
2.了解HashMap的性能
HashMap利用每一個key的哈希值,去為value找尋存儲位置。這個存儲位置往往被稱為“桶”,當哈希值唯一時,那么一個桶中就只有一個對象,這時情況最理想,然而若非正常情況下(比如重寫hashCode強制返回相等),那么一個桶能就有放多個對象,這時性能最差。
上面說道,HashMap與Set、List在某方面都很相似,做為一個強大的集合,它的內部自然也有會動態開辟內存的操作。所有就有了下面幾個參數,
當負載因子很大時,如有90個元素,而集合的容量為100,因子就是0.9,這樣情況非常不利于查詢操作,因為put和get操作會遍歷大量的元素,時間復雜度無形就會增加,但在內存開銷上確實是比較節省的,因為集合不會反復的創建,因為每一次擴充集合的操作,就意味著要將原始元素重新插入到新的集合中去,性能開銷是很大的。
而當負載因子很小時,查詢效率將會非常高(因為遍歷少),但是卻在內部進行了許多次開辟內存的操作。
因此,在系統中,要根據實際需求正確把握HashMap的用法,如一開始建立集合的時候就知道這個集合非常大,那么就有必要在初始化的時候就指明capacity,不應該使用默認值,這樣效率能高點;相反只有少量集合元素時,不應該在創建的時候指定很大的capacity,這明顯是在浪費內存。
更多關于java算法相關內容感興趣的讀者可查看本站專題:《Java數據結構與算法教程》、《Java操作DOM節點技巧總結》、《Java文件與目錄操作技巧匯總》和《Java緩存操作技巧匯總》
希望本文所述對大家java程序設計有所幫助。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





