溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹python爬蟲中如何使用Selenium模擬瀏覽器行為,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
分析
他的代碼比較簡單,主要有以下的步驟:使用BeautifulSoup庫,打開百度貼吧的首頁地址,再解析得到id為new_list標簽底下的img標簽,最后將img標簽的圖片保存下來。
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
data=requests.get("https://tieba.baidu.com/index.html",headers=headers)
html=BeautifulSoup(data.text,'lxml')前面提到過,有部分圖片是動態加載的,那么首先我們得弄清楚,這部分圖片是怎么動態加載的。在瀏覽器中打開百度貼吧的首頁,可以明顯的看到,在往下滾動滾動條的時候,當滾動到底部的時候,滾動條縮短了,并向上移動了一段距離。這個現象也正是有DOM元素動態的添加到了html文檔的一個表現。動態加載數據無非就是ajax請求,而ajax本質上就是XMLHttpRequest請求(簡稱xhr)。在谷歌瀏覽器中,我們可以通過開發者工具的network面板來監測xhr請求。
剛打開首頁時的xhr請求,這里的請求都和要爬取的圖片無關。
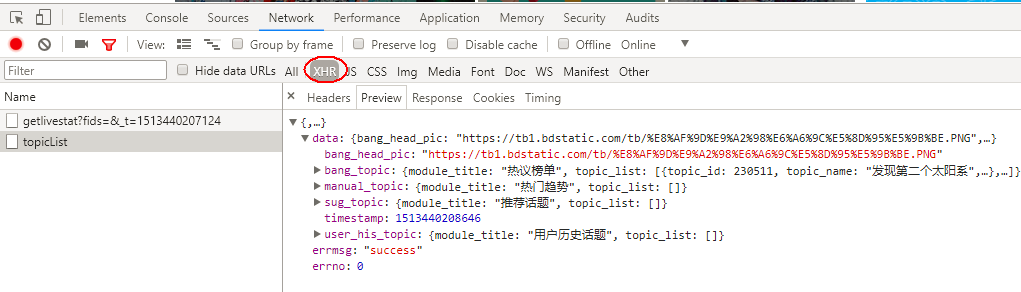
滾動條向下第1次滾動到底部,這里請求的是第20-40條熱門動態,包含要爬取圖片。
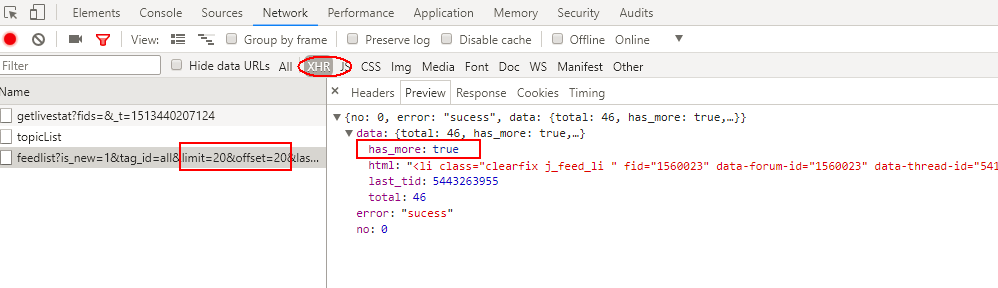
滾動條向下第2次滾動到底部,這里請求的是第40-60條熱門動態,包含要爬取圖片。并且返回的的has_more:false表明沒有跟多數據了。
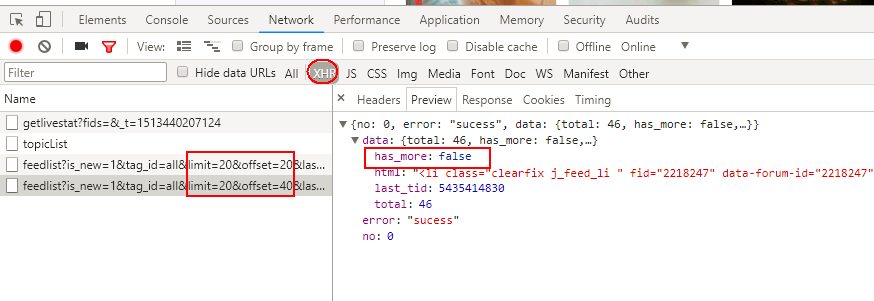
滾動條向下第3次滾動到底部,再無xhr請求。
解決方案
根據上面的分析,我們已經明白,單純使用BeautifulSoup進行爬蟲的時候,只能爬取到1-20條熱門動態里面的圖片。為了爬取到完整的熱門動態里面的圖片,我們則需要模擬瀏覽器的滾動條滾動,讓網頁去觸發xhr請求更多的熱門動態。
在python中,如果需要模擬瀏覽器的行為,可以使用selenium庫。selenium庫是一個自動化測試框架,可以用來模擬測試瀏覽器的各種行為,這里我們使用它來模擬瀏覽器打開百度貼吧的首頁,并模擬滾動條向下滾動到底部的操作。
安裝
pip install selenium
下載瀏覽器驅動
火狐瀏覽器驅動,其下載地址是:https://github.com/mozilla/geckodriver/releases
谷歌瀏覽器驅動,其下載地址是:http://chromedriver.storage.googleapis.com/index.html?path=2.33/
opera瀏覽器驅動,其下載地址是:https://github.com/operasoftware/operachromiumdriver/releases
對照自己電腦安裝的瀏覽器和對應的版本,分別從上面的地址下載驅動文件,也可以從我的github項目中統一下載以上幾個驅動(地址:https://github.com/Sesshoumaru/attachments/tree/master/Selenium%20WebDriver)。下載解壓后,將所在的目錄添加系統的環境變量中。當然你也可以將下載下來的驅動放到python安裝目錄的lib目錄中,因為它本身已經存在于環境變量(我就是這么干的)。
使用python代碼模擬瀏覽器行為
要使用selenium先需要定義一個具體browser對象,這里就定義的時候就看你電腦安裝的具體瀏覽器和安裝的哪個瀏覽器的驅動。這里以火狐瀏覽器為例:
from selenium import webdriver browser = webdriver.Firefox()
再模擬打開貼吧首頁:
browser.get(https://tieba.baidu.com/index.html)
再模擬滾動條滾動到底部
for i in range(1, 5):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)最后再使用BeautifulSoup,解析圖片標簽:
html = BeautifulSoup(browser.page_source, "lxml")
imgs = html.select("#new_list li img")幾個注意點
必須安裝瀏覽器和瀏覽器驅動,并且瀏覽器和瀏覽器驅動要配到
即如果使用谷歌瀏覽器模擬網頁行為,則需要下載谷歌瀏覽器驅動;
如果使用火狐瀏覽器模擬網頁行為,則需要下載火狐瀏覽器驅動
瀏覽器驅動所在的目錄要在環境變量中,或者定義瀏覽器browser的時候指定驅動的路徑
selenium更多用法
查找元素
from selenium import webdriver
browser = webdriver.Firefox()
browser.get("https://tieba.baidu.com/index.html")
new_list = browser.find_element_by_id('new_list')
user_name = browser.find_element_by_name ('user_name')
active = browser.find_element_by_class_name ('active')
p = browser.find_element_by_tag_name ('p')
# find_element_by_name 通過name查找單個元素
# find_element_by_xpath 通過xpath查找單個元素
# find_element_by_link_text 通過鏈接查找單個元素
# find_element_by_partial_link_text 通過部分鏈接查找單個元素
# find_element_by_tag_name 通過標簽名稱查找單個元素
# find_element_by_class_name 通過類名查找單個元素
# find_element_by_css_selector 通過css選擇武器查找單個元素
# find_elements_by_name 通過name查找多個元素
# find_elements_by_xpath 通過xpath查找多個元素
# find_elements_by_link_text 通過鏈接查找多個元素
# find_elements_by_partial_link_text 通過部分鏈接查找多個元素
# find_elements_by_tag_name 通過標簽名稱查找多個元素
# find_elements_by_class_name 通過類名查找多個元素
# find_elements_by_css_selector 通過css選擇武器查找多個元素獲取元素信息
btn_more = browser.find_element_by_id('btn_more')
print(btn_more.get_attribute('class')) # 獲取屬性
print(btn_more.get_attribute('href')) # 獲取屬性
print(btn_more.text) # 獲取文本值元素交互操作
btn_more = browser.find_element_by_id('btn_more')
btn_more.click() # 模擬點擊,可以模擬點擊加載更多
input_search = browser.find_element(By.ID,'q')
input_search.clear() # 清空輸入執行JavaScript
# 執行JavaScript腳本
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')以上是“python爬蟲中如何使用Selenium模擬瀏覽器行為”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





