溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關python爬蟲如何模擬瀏覽器,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
一、Herders 屬性
爬取CSDN博客
import urllib.request url = "http://blog.csdn.net/hurmishine/article/details/71708030"file = urllib.request.urlopen(url)
爬取結果
urllib.error.HTTPError: HTTP Error 403: Forbidden
這就說明CSDN做了一些設置,來防止別人惡意爬取信息
所以接下來,我們需要讓爬蟲模擬成瀏覽器
任意打開一個網頁,比如打開百度,然后按F12,此時會出現一個窗口,我們切換到Network標簽頁,然后點擊刷新網站,選中彈出框左側的“www.baidu.com”,即下圖所示:
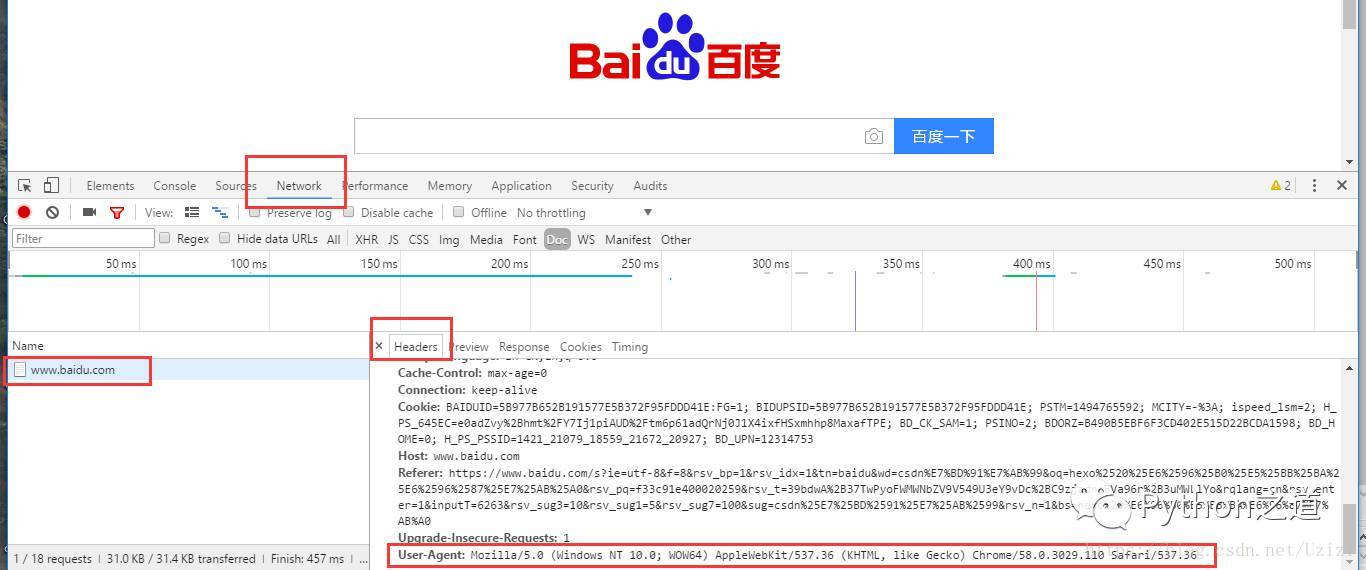
往下拖動 我們會看到“User-Agent”字樣的一串信息,沒錯 這就是我們想要的東西。我們將其復制下來。
此時我們得到的信息是:”Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36”
接下來我們可以用兩種方式來模擬瀏覽器訪問網頁。
二、方法1:使用build_opener()修改報頭
由于urlopen()不支持一些HTTP的高級功能,所以我們需要修改報頭。可以使用urllib.request.build_opener()進行,我們修改一下上面的代碼:
import urllib.request
url = "http://blog.csdn.net/hurmishine/article/details/71708030"headers = ("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36")
opener = urllib.request.build_opener()
opener.addheaders = [headers]
data = opener.open(url).read()
print(data)上面代碼中我們先定義一個變量headers來儲存User-Agent信息,定義的格式是(“User-Agent”,具體信息)
具體信息我們上面已經獲取到了,這個信息獲取一次即可,以后爬取其他網站也可以用,所以我們可以保存下來,不用每次都F12去找了。
然后我們用urllib.request.build_opener()創建自定義的opener對象并賦值給opener,然后設置opener的addheaders,就是設置對應的頭信息,格式為:“opener(對象名).addheaders = [頭信息(即我們儲存的具體信息)]”,設置好后我們就可以使用opener對象的open()方法打開對應的網址了。格式:“opener(對象名).open(url地址)”打開后我們可以使用read()方法來讀取對應數據,并賦值給data變量。
得到輸出結果
b'\r\n<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">\r\n \r\n <html xmlns="http://www.w3.org/1999/xhtml">\r\n \r\n<head> \r\n\r\n <link rel="canonical" href="http://blog.csdn.net/hurmishine/article/details/71708030" rel="external nofollow" /> ...
三、方法2:使用add_header()添加報頭
除了上面的這種方法,還可以使用urllib.request.Request()下的add_header()實現瀏覽器的模擬。
先上代碼
import urllib.request
url = "http://blog.csdn.net/hurmishine/article/details/71708030"req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36')
data = urllib.request.urlopen(req).read()
print(data)好,我們來分析一下。
導入包,定義url地址我們就不說了,我們使用urllib.request.Request(url)創建一個Request對象,并賦值給變量req,創建Request對象的格式:urllib.request.Request(url地址)
隨后我們使用add_header()方法添加對應的報頭信息,格式:Request(對象名).add_header(‘對象名','對象值')
現在我們已經設置好了報頭,然后我們使用urlopen()打開該Request對象即可打開對應的網址,多以我們使用
data = urllib.request.urlopen(req).read()打開了對應的網址,并讀取了網頁內容,并賦值給data變量。
以上,我們使用了兩種方法實現了爬蟲模擬瀏覽器打開網址,并獲取網址的內容信息,避免了403錯誤。
值得我們注意的是,方法1中使用的是addheaders()方法,方法2中使用的是add_header()方法,注意末尾有無s以及有無下劃線的區別
關于“python爬蟲如何模擬瀏覽器”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





