溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何使用Python對微信好友進行數據分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
1、云計算,典型應用OpenStack。2、WEB前端開發,眾多大型網站均為Python開發。3.人工智能應用,基于大數據分析和深度學習而發展出來的人工智能本質上已經無法離開python。4、系統運維工程項目,自動化運維的標配就是python+Django/flask。5、金融理財分析,量化交易,金融分析。6、大數據分析。
只有登錄微信才能獲取到微信好友的信息,本文采用wxpy該第三方庫進行微信的登錄以及信息的獲取。
wxpy 在 itchat 的基礎上,通過大量接口優化提升了模塊的易用性,并進行豐富的功能擴展。
wxpy一些常見的場景:
?控制路由器、智能家居等具有開放接口的玩意兒
?運行腳本時自動把日志發送到你的微信
?加群主為好友,自動拉進群中
?跨號或跨群轉發消息
?自動陪人聊天
?逗人玩
總而言之,可用來實現各種微信個人號的自動化操作。
wxpy 支持 Python 3.4-3.6,以及 2.7 版本
將下方命令中的 “pip” 替換為 “pip3” 或 “pip2”,可確保安裝到對應的 Python 版本中
1.從 PYPI 官方源下載安裝 (在國內可能比較慢或不穩定):
pip install -U wxpy1
1.從豆瓣 PYPI 鏡像源下載安裝 (推薦國內用戶選用):
pip install -U wxpy -i "https://pypi.doubanio.com/simple/"1
wxpy中有一個機器人對象,機器人 Bot 對象可被理解為一個 Web 微信客戶端。Bot 在初始化時便會執行登陸操作,需要手機掃描登陸。
通過機器人對象 Bot 的 chats(), friends(),groups(), mps() 方法, 可分別獲取到當前機器人的 所有聊天對象、好友、群聊,以及公眾號列表。
本文主要通過friends()獲取到所有好友信息,然后進行數據的處理。
from wxpy import * # 初始化機器人,掃碼登陸 bot = Bot() # 獲取所有好友 my_friends = bot.friends() print(type(my_friends))
以下為輸出消息:
Getting uuid of QR code.
Downloading QR code.
Please scan the QR code to log in.
Please press confirm on your phone.
Loading the contact, this may take a little while.
<Login successfully as 王強?>
<class 'wxpy.api.chats.chats.Chats'>
wxpy.api.chats.chats.Chats對象是多個聊天對象的合集,可用于搜索或統計,可以搜索和統計的信息包括sex(性別)、province(省份)、city(城市)和signature(個性簽名)等。
使用一個字典sex_dict來統計好友中男性和女性的數量。
# 使用一個字典統計好友男性和女性的數量
sex_dict = {'male': 0, 'female': 0}
for friend in my_friends:
# 統計性別
if friend.sex == 1:
sex_dict['male'] += 1
elif friend.sex == 2:
sex_dict['female'] += 1
print(sex_dict)以下為輸出結果:
{'male': 255, 'female': 104}
本文采用 ECharts餅圖 進行數據的呈現,打開鏈接http://echarts.baidu.com/echarts2/doc/example/pie1.html,可以看到如下內容:
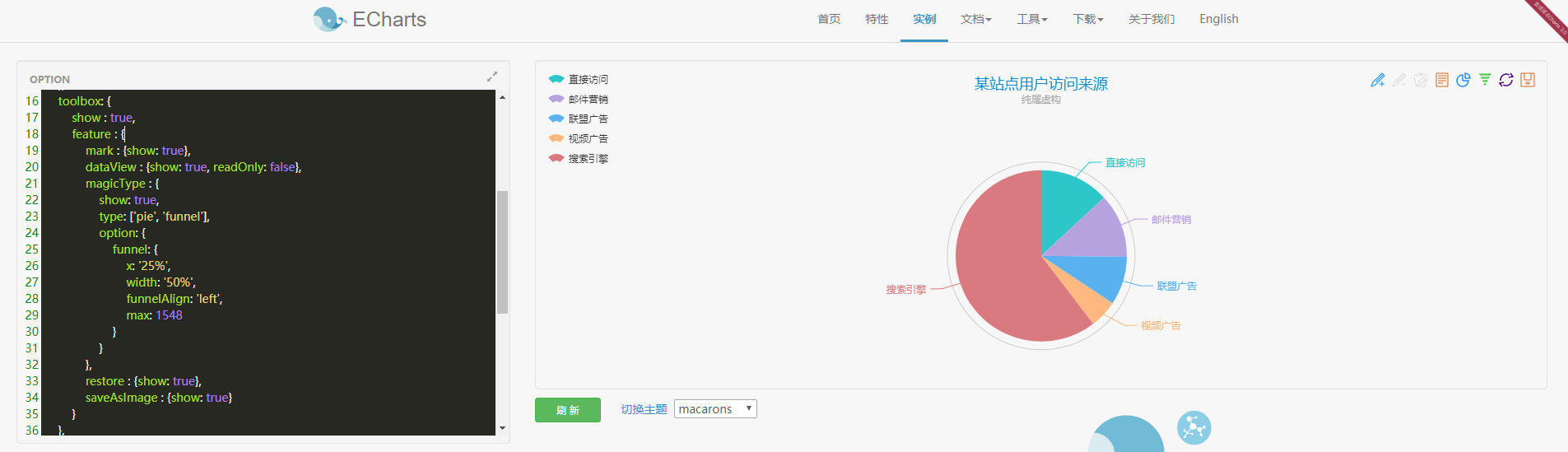
1、echarts餅圖原始內容
從圖中可以看到左側為數據,右側為呈現的數據圖,其他的形式的圖也是這種左右結構。看一下左邊的數據:
option = {
title : {
text: '某站點用戶訪問來源',
subtext: '純屬虛構',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} (aegqsqibtmh%)"
},
legend: {
orient : 'vertical',
x : 'left',
data:['直接訪問','郵件營銷','聯盟廣告','視頻廣告','搜索引擎']
},
toolbox: {
show : true,
feature : {
mark : {show: true},
dataView : {show: true, readOnly: false},
magicType : {
show: true,
type: ['pie', 'funnel'],
option: {
funnel: {
x: '25%',
width: '50%',
funnelAlign: 'left',
max: 1548
}
}
},
restore : {show: true},
saveAsImage : {show: true}
}
},
calculable : true,
series : [
{
name:'訪問來源',
type:'pie',
radius : '55%',
center: ['50%', '60%'],
data:[
{value:335, name:'直接訪問'},
{value:310, name:'郵件營銷'},
{value:234, name:'聯盟廣告'},
{value:135, name:'視頻廣告'},
{value:1548, name:'搜索引擎'}
]
}
]
};可以看到option =后面的大括號里是JSON格式的數據,接下來分析一下各項數據:
?title:標題
?text:標題內容
?subtext:子標題
?x:標題位置
?tooltip:提示,將鼠標放到餅狀圖上就可以看到提示
?legend:圖例
?orient:方向
?x:圖例位置
?data:圖例內容
?toolbox:工具箱,在餅狀圖右上方橫向排列的圖標
?mark:輔助線開關
?dataView:數據視圖,點擊可以查看餅狀圖數據
?magicType:餅圖(pie)切換和漏斗圖(funnel)切換
?restore:還原
?saveAsImage:保存為圖片
?calculable:暫時不知道它有什么用
?series:主要數據
?data:呈現的數據
其它類型的圖數據格式類似,后面不再詳細分析。只需要修改data、l**egend->data**、series->data即可,修改后的數據為:
option = {
title : {
text: '微信好友性別比例',
subtext: '真實數據',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} (aegqsqibtmh%)"
},
legend: {
orient : 'vertical',
x : 'left',
data:['男性','女性']
},
toolbox: {
show : true,
feature : {
mark : {show: true},
dataView : {show: true, readOnly: false},
magicType : {
show: true,
type: ['pie', 'funnel'],
option: {
funnel: {
x: '25%',
width: '50%',
funnelAlign: 'left',
max: 1548
}
}
},
restore : {show: true},
saveAsImage : {show: true}
}
},
calculable : true,
series : [
{
name:'訪問來源',
type:'pie',
radius : '55%',
center: ['50%', '60%'],
data:[
{value:255, name:'男性'},
{value:104, name:'女性'}
]
}
]
};數據修改完成后,點擊頁面中綠色的刷新按鈕,可以得到餅圖如下(可以根據自己的喜好修改主題):
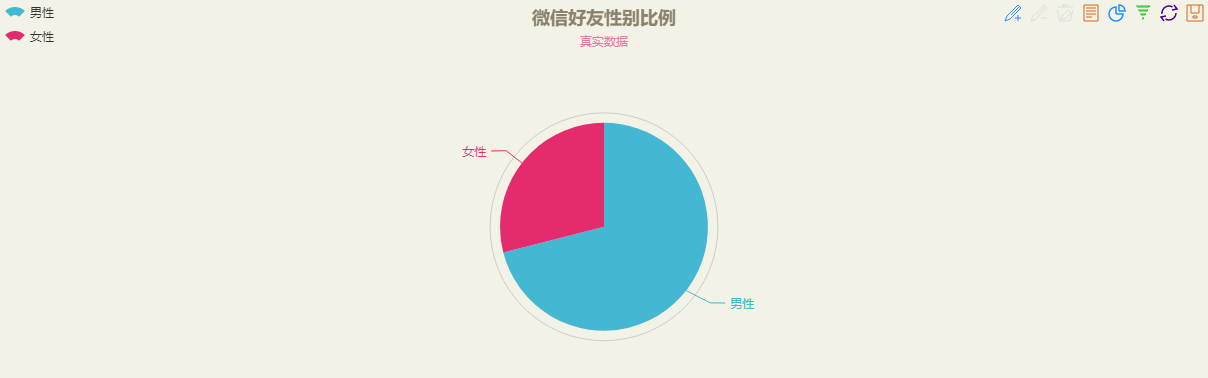
2、好友性別比例
將鼠標放到餅圖上可以看到詳細數據:
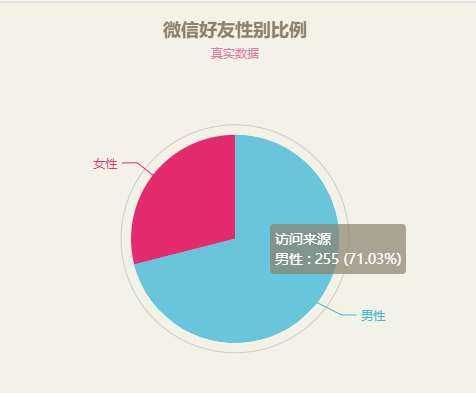
3、好友性別比例查看數據
3、微信好友全國分布圖
# 使用一個字典統計各省好友數量
province_dict = {'北京': 0, '上海': 0, '天津': 0, '重慶': 0,
'河北': 0, '山西': 0, '吉林': 0, '遼寧': 0, '黑龍江': 0,
'陜西': 0, '甘肅': 0, '青海': 0, '山東': 0, '福建': 0,
'浙江': 0, '臺灣': 0, '河南': 0, '湖北': 0, '湖南': 0,
'江西': 0, '江蘇': 0, '安徽': 0, '廣東': 0, '海南': 0,
'四川': 0, '貴州': 0, '云南': 0,
'內蒙古': 0, '新疆': 0, '寧夏': 0, '廣西': 0, '西藏': 0,
'香港': 0, '澳門': 0}
# 統計省份
for friend in my_friends:
if friend.province in province_dict.keys():
province_dict[friend.province] += 1
# 為了方便數據的呈現,生成JSON Array格式數據
data = []
for key, value in province_dict.items():
data.append({'name': key, 'value': value})
print(data)以下為輸出結果:
[{'name': '北京', 'value': 91}, {'name': '上海', 'value': 12}, {'name': '天津', 'value': 15}, {'name': '重慶', 'value': 1}, {'name': '河北', 'value': 53}, {'name': '山西', 'value': 2}, {'name': '吉林', 'value': 1}, {'name': '遼寧', 'value': 1}, {'name': '黑龍江', 'value': 2}, {'name': '陜西', 'value': 3}, {'name': '甘肅', 'value': 0}, {'name': '青海', 'value': 0}, {'name': '山東', 'value': 7}, {'name': '福建', 'value': 3}, {'name': '浙江', 'value': 4}, {'name': '臺灣', 'value': 0}, {'name': '河南', 'value': 1}, {'name': '湖北', 'value': 4}, {'name': '湖南', 'value': 4}, {'name': '江西', 'value': 4}, {'name': '江蘇', 'value': 9}, {'name': '安徽', 'value': 2}, {'name': '廣東', 'value': 63}, {'name': '海南', 'value': 0}, {'name': '四川', 'value': 2}, {'name': '貴州', 'value': 0}, {'name': '云南', 'value': 1}, {'name': '內蒙古', 'value': 0}, {'name': '新疆', 'value': 2}, {'name': '寧夏', 'value': 0}, {'name': '廣西', 'value': 1}, {'name': '西藏', 'value': 0}, {'name': '香港', 'value': 0}, {'name': '澳門', 'value': 0}]
可以看出,好友最多的省份為北京。那么問題來了:為什么要把數據重組成這種格式?因為ECharts的地圖需要這種格式的數據。
采用ECharts地圖 來進行好友分布的數據呈現。打開該網址,將左側數據修改為:
option = {
title : {
text: '微信好友全國分布圖',
subtext: '真實數據',
x:'center'
},
tooltip : {
trigger: 'item'
},
legend: {
orient: 'vertical',
x:'left',
data:['好友數量']
},
dataRange: {
min: 0,
max: 100,
x: 'left',
y: 'bottom',
text:['高','低'], // 文本,默認為數值文本
calculable : true
},
toolbox: {
show: true,
orient : 'vertical',
x: 'right',
y: 'center',
feature : {
mark : {show: true},
dataView : {show: true, readOnly: false},
restore : {show: true},
saveAsImage : {show: true}
}
},
roamController: {
show: true,
x: 'right',
mapTypeControl: {
'china': true
}
},
series : [
{
name: '好友數量',
type: 'map',
mapType: 'china',
roam: false,
itemStyle:{
normal:{label:{show:true}},
emphasis:{label:{show:true}}
},
data:[
{'name': '北京', 'value': 91},
{'name': '上海', 'value': 12},
{'name': '天津', 'value': 15},
{'name': '重慶', 'value': 1},
{'name': '河北', 'value': 53},
{'name': '山西', 'value': 2},
{'name': '吉林', 'value': 1},
{'name': '遼寧', 'value': 1},
{'name': '黑龍江', 'value': 2},
{'name': '陜西', 'value': 3},
{'name': '甘肅', 'value': 0},
{'name': '青海', 'value': 0},
{'name': '山東', 'value': 7},
{'name': '福建', 'value': 3},
{'name': '浙江', 'value': 4},
{'name': '臺灣', 'value': 0},
{'name': '河南', 'value': 1},
{'name': '湖北', 'value': 4},
{'name': '湖南', 'value': 4},
{'name': '江西', 'value': 4},
{'name': '江蘇', 'value': 9},
{'name': '安徽', 'value': 2},
{'name': '廣東', 'value': 63},
{'name': '海南', 'value': 0},
{'name': '四川', 'value': 2},
{'name': '貴州', 'value': 0},
{'name': '云南', 'value': 1},
{'name': '內蒙古', 'value': 0},
{'name': '新疆', 'value': 2},
{'name': '寧夏', 'value': 0},
{'name': '廣西', 'value': 1},
{'name': '西藏', 'value': 0},
{'name': '香港', 'value': 0},
{'name': '澳門', 'value': 0}
]
}
]
};注意兩點:
?dataRange->max 根據統計數據適當調整
?series->data 的數據格式
點擊刷新按鈕后,可以生成如下地圖:
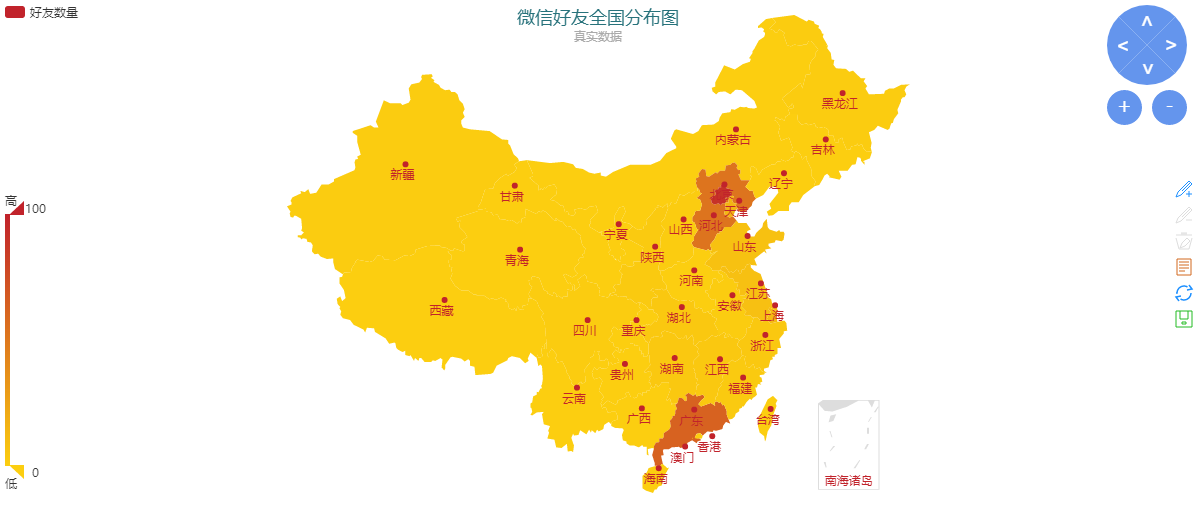
4、好友全國分布圖
從圖中可以看出我的好友主要分布在北京、河北和廣東。
有趣的是,地圖左邊有一個滑塊,代表地圖數據的范圍,我們將上邊的滑塊拉到最下面可以看到沒有微信好友分布的省份:
5、沒有微信好友的省份
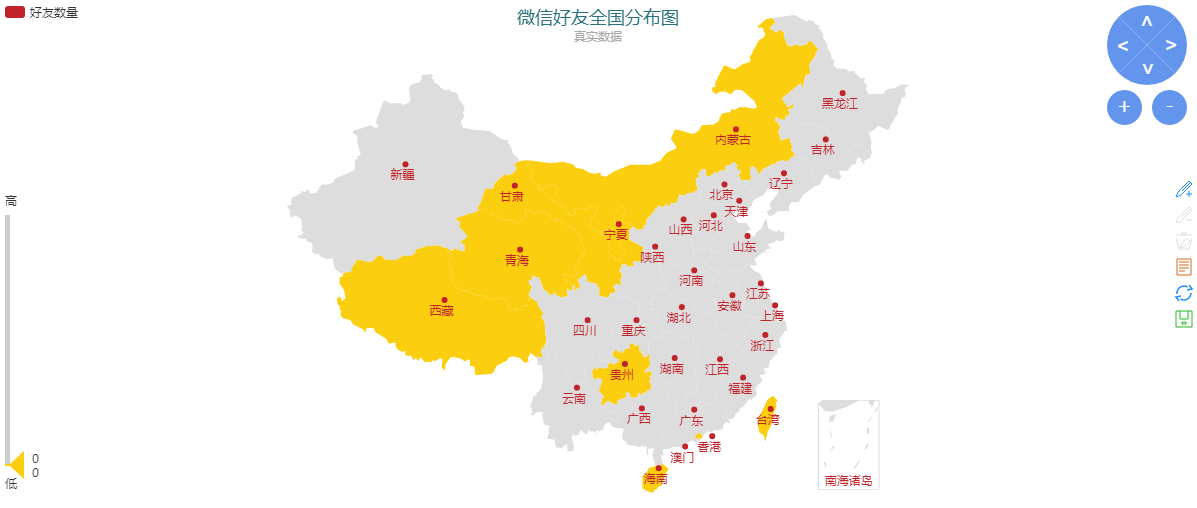
按照這個思路,我們可以在地圖上看到確切數量好友分布的省份,讀者可以動手試試。
def write_txt_file(path, txt):
'''
寫入txt文本
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f.write(txt)
# 統計簽名
for friend in my_friends:
# 對數據進行清洗,將標點符號等對詞頻統計造成影響的因素剔除
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, friend.signature)
write_txt_file('signatures.txt', ''.join(filterdata))上面代碼實現了對好友簽名進行清洗以及保存的功能,執行完成之后會在當前目錄生成signatures.txt文件。
數據呈現采用詞頻統計和詞云展示,通過詞頻可以了解到微信好友的生活態度。
詞頻統計用到了 jieba、numpy、pandas、scipy、wordcloud庫。如果電腦上沒有這幾個庫,執行安裝指令:
?pip install jieba
?pip install pandas
?pip install numpy
?pip install scipy
?pip install wordcloud
4.2.1 讀取txt文件
前面已經將好友簽名保存到txt文件里了,現在我們將其讀出:
def read_txt_file(path): ''' 讀取txt文本 ''' with open(path, 'r', encoding='gb18030', newline='') as f: return f.read()
4.2.2 stop word
下面引入一個概念:stop word, 在網站里面存在大量的常用詞比如:“在”、“里面”、“也”、“的”、“它”、“為”這些詞都是停止詞。這些詞因為使用頻率過高,幾乎每個網頁上都存在,所以搜索引擎開發人員都將這一類詞語全部忽略掉。如果我們的網站上存在大量這樣的詞語,那么相當于浪費了很多資源。
在百度搜索stpowords.txt進行下載,放到py文件同級目錄。
content = read_txt_file(txt_filename)
segment = jieba.lcut(content)
words_df=pd.DataFrame({'segment':segment})
stopwords=pd.read_csv("stopwords.txt",index_col=False,quoting=3,sep=" ",names=['stopword'],encoding='utf-8')
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]4.2.3 詞頻統計
重頭戲來了,詞頻統計使用numpy:
import numpy
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"計數":numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["計數"],ascending=False)4.2.4 詞頻可視化:詞云
詞頻統計雖然出來了,可以看出排名,但是不完美,接下來我們將它可視化。使用到wordcloud庫,詳細介紹見 github 。
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
# 設置詞云屬性
color_mask = imread('background.jfif')
wordcloud = WordCloud(font_path="simhei.ttf", # 設置字體可以顯示中文
background_color="white", # 背景顏色
max_words=100, # 詞云顯示的最大詞數
mask=color_mask, # 設置背景圖片
max_font_size=100, # 字體最大值
random_state=42,
width=1000, height=860, margin=2,# 設置圖片默認的大小,但是如果使用背景圖片的話, # 那么保存的圖片大小將會按照其大小保存,margin為詞語邊緣距離
)
# 生成詞云, 可以用generate輸入全部文本,也可以我們計算好詞頻后使用generate_from_frequencies函數
word_frequence = {x[0]:x[1]for x in words_stat.head(100).values}
print(word_frequence)
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 從背景圖片生成顏色值
image_colors = ImageColorGenerator(color_mask)
# 重新上色
wordcloud.recolor(color_func=image_colors)
# 保存圖片
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()運行效果圖如下(左圖為背景圖,右圖為生成詞云圖片):

6、背景圖和詞云圖對比
從詞云圖可以分析好友特點:
?做——————–行動派
?人生、生活——–熱愛生活
?快樂—————–樂觀
?選擇—————–決斷
?專業—————–專業
?愛——————–愛
至此,微信好友的分析工作已經完成,wxpy的功能還有很多,比如聊天、查看公眾號信息等,有意的讀者請自行查閱官方文檔。
上面的代碼比較松散,下面展示的完整代碼我將各功能模塊封裝成函數:
#-*- coding: utf-8 -*-
import re
from wxpy import *
import jieba
import numpy
import pandas as pd
import matplotlib.pyplot as plt
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
def write_txt_file(path, txt):
'''
寫入txt文本
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f.write(txt)
def read_txt_file(path):
'''
讀取txt文本
'''
with open(path, 'r', encoding='gb18030', newline='') as f:
return f.read()
def login():
# 初始化機器人,掃碼登陸
bot = Bot()
# 獲取所有好友
my_friends = bot.friends()
print(type(my_friends))
return my_friends
def show_sex_ratio(friends):
# 使用一個字典統計好友男性和女性的數量
sex_dict = {'male': 0, 'female': 0}
for friend in friends:
# 統計性別
if friend.sex == 1:
sex_dict['male'] += 1
elif friend.sex == 2:
sex_dict['female'] += 1
print(sex_dict)
def show_area_distribution(friends):
# 使用一個字典統計各省好友數量
province_dict = {'北京': 0, '上海': 0, '天津': 0, '重慶': 0,
'河北': 0, '山西': 0, '吉林': 0, '遼寧': 0, '黑龍江': 0,
'陜西': 0, '甘肅': 0, '青海': 0, '山東': 0, '福建': 0,
'浙江': 0, '臺灣': 0, '河南': 0, '湖北': 0, '湖南': 0,
'江西': 0, '江蘇': 0, '安徽': 0, '廣東': 0, '海南': 0,
'四川': 0, '貴州': 0, '云南': 0,
'內蒙古': 0, '新疆': 0, '寧夏': 0, '廣西': 0, '西藏': 0,
'香港': 0, '澳門': 0}
# 統計省份
for friend in friends:
if friend.province in province_dict.keys():
province_dict[friend.province] += 1
# 為了方便數據的呈現,生成JSON Array格式數據
data = []
for key, value in province_dict.items():
data.append({'name': key, 'value': value})
print(data)
def show_signature(friends):
# 統計簽名
for friend in friends:
# 對數據進行清洗,將標點符號等對詞頻統計造成影響的因素剔除
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, friend.signature)
write_txt_file('signatures.txt', ''.join(filterdata))
# 讀取文件
content = read_txt_file('signatures.txt')
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment':segment})
# 讀取stopwords
stopwords = pd.read_csv("stopwords.txt",index_col=False,quoting=3,sep=" ",names=['stopword'],encoding='utf-8')
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
print(words_df)
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"計數":numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["計數"],ascending=False)
# 設置詞云屬性
color_mask = imread('background.jfif')
wordcloud = WordCloud(font_path="simhei.ttf", # 設置字體可以顯示中文
background_color="white", # 背景顏色
max_words=100, # 詞云顯示的最大詞數
mask=color_mask, # 設置背景圖片
max_font_size=100, # 字體最大值
random_state=42,
width=1000, height=860, margin=2,# 設置圖片默認的大小,但是如果使用背景圖片的話, # 那么保存的圖片大小將會按照其大小保存,margin為詞語邊緣距離
)
# 生成詞云, 可以用generate輸入全部文本,也可以我們計算好詞頻后使用generate_from_frequencies函數
word_frequence = {x[0]:x[1]for x in words_stat.head(100).values}
print(word_frequence)
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 從背景圖片生成顏色值
image_colors = ImageColorGenerator(color_mask)
# 重新上色
wordcloud.recolor(color_func=image_colors)
# 保存圖片
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
def main():
friends = login()
show_sex_ratio(friends)
show_area_distribution(friends)
show_signature(friends)
if __name__ == '__main__':
main()關于“如何使用Python對微信好友進行數據分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





