溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹怎么在pandas中使用DataFrame 刪除重復行,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
1. 建立一個DataFrame
C=pd.DataFrame({'a':['dog']*3+['fish']*3+['dog'],'b':[10,10,12,12,14,14,10]})
2. 判斷是否有重復項
用duplicated( )函數判斷
C.duplicated()
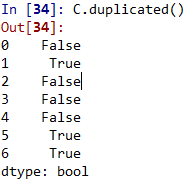
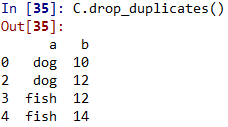
3. 有重復項,則可以用drop_duplicates()移除重復項
C.drop_duplicates()
4. Duplicated( )和drop_duplicates( )方法是以默認的方式判斷全部的列(上面的例子中是看兩個變量a和b是否都是重復出現)。
我們也可以對特定的列進行重復項判斷。
C.duplicated(['a']) C.drop_duplicates(['a']) C.duplicated(['b']) C.drop_duplicates(['b'])

5. norepeat_df = df.drop_duplicates(subset=['A_ID', 'B_ID'], keep='first')
#上面的命令去掉UNIT_ID和KPI_ID列中重復的行,并保留重復出現的行中第一次出現的行
補充:
當keep=False時,就是去掉所有的重復行
當keep=‘first'時,就是保留第一次出現的重復行
當keep='last'時就是保留最后一次出現的重復行。
關于怎么在pandas中使用DataFrame 刪除重復行就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





