溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Python如何根據成績分析系統,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
案例:該數據集的是一個關于每個學生成績的數據集,接下來我們對該數據集進行分析,判斷學生是否適合繼續深造
數據集特征展示
1 GRE 成績 (290 to 340) 2 TOEFL 成績(92 to 120) 3 學校等級 (1 to 5) 4 自身的意愿 (1 to 5) 5 推薦信的力度 (1 to 5) 6 CGPA成績 (6.8 to 9.92) 7 是否有研習經驗 (0 or 1) 8 讀碩士的意向 (0.34 to 0.97)
1.導入包
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import os,sys
2.導入并查看數據集
df = pd.read_csv("D:\\machine-learning\\score\\Admission_Predict.csv",sep = ",")
print('There are ',len(df.columns),'columns')
for c in df.columns:
sys.stdout.write(str(c)+', 'There are 9 columns Serial No., GRE Score, TOEFL Score, University Rating, SOP, LOR , CGPA, Research, Chance of Admit , 一共有9列特征
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 400 entries, 0 to 399 Data columns (total 9 columns): Serial No. 400 non-null int64 GRE Score 400 non-null int64 TOEFL Score 400 non-null int64 University Rating 400 non-null int64 SOP 400 non-null float64 LOR 400 non-null float64 CGPA 400 non-null float64 Research 400 non-null int64 Chance of Admit 400 non-null float64 dtypes: float64(4), int64(5) memory usage: 28.2 KB 數據集信息: 1.數據有9個特征,分別是學號,GRE分數,托福分數,學校等級,SOP,LOR,CGPA,是否參加研習,進修的幾率 2.數據集中沒有空值 3.一共有400條數據
# 整理列名稱
df = df.rename(columns={'Chance of Admit ':'Chance of Admit'})
# 顯示前5列數據
df.head()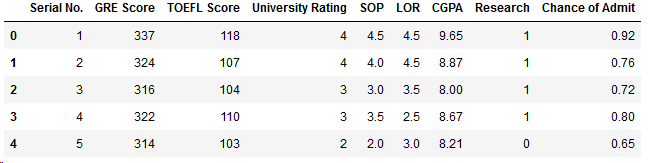
3.查看每個特征的相關性
fig,ax = plt.subplots(figsize=(10,10)) sns.heatmap(df.corr(),ax=ax,annot=True,linewidths=0.05,fmt='.2f',cmap='magma') plt.show()
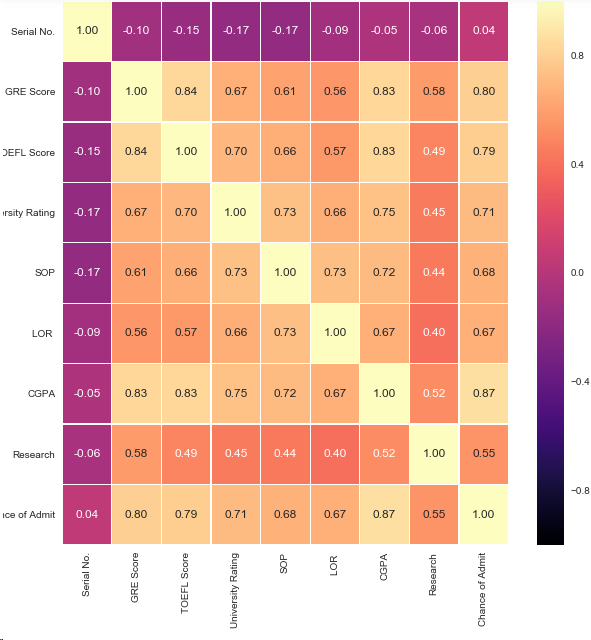
結論:1.最有可能影響是否讀碩士的特征是GRE,CGPA,TOEFL成績
2.影響相對較小的特征是LOR,SOP,和Research
4.數據可視化,雙變量分析
4.1 進行Research的人數
print("Not Having Research:",len(df[df.Research == 0]))
print("Having Research:",len(df[df.Research == 1]))
y = np.array([len(df[df.Research == 0]),len(df[df.Research == 1])])
x = np.arange(2)
plt.bar(x,y)
plt.title("Research Experience")
plt.xlabel("Canditates")
plt.ylabel("Frequency")
plt.xticks(x,('Not having research','Having research'))
plt.show()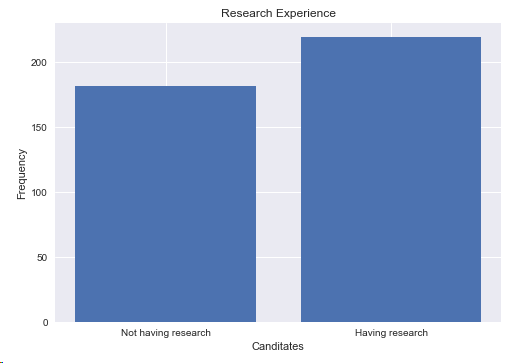
結論:進行research的人數是219,本科沒有research人數是181
4.2 學生的托福成績
y = np.array([df['TOEFL Score'].min(),df['TOEFL Score'].mean(),df['TOEFL Score'].max()])
x = np.arange(3)
plt.bar(x,y)
plt.title('TOEFL Score')
plt.xlabel('Level')
plt.ylabel('TOEFL Score')
plt.xticks(x,('Worst','Average','Best'))
plt.show()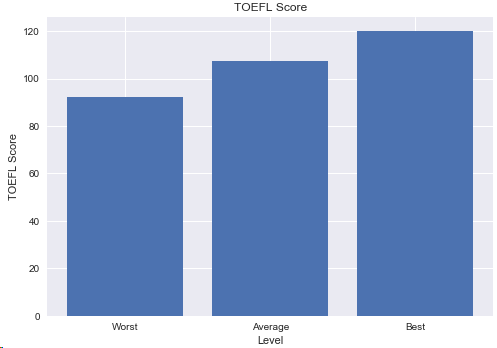
結論:最低分92分,最高分滿分,進修學生的英語成績很不錯
4.3 GRE成績
df['GRE Score'].plot(kind='hist',bins=200,figsize=(6,6))
plt.title('GRE Score')
plt.xlabel('GRE Score')
plt.ylabel('Frequency')
plt.show()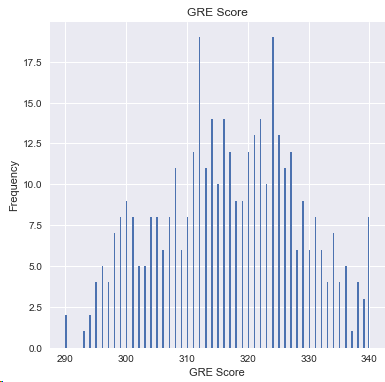
結論:310和330的分值的學生居多
4.4 CGPA和學校等級的關系
plt.scatter(df['University Rating'],df['CGPA'])
plt.title('CGPA Scores for University ratings')
plt.xlabel('University Rating')
plt.ylabel('CGPA')
plt.show()
結論:學校越好,學生的GPA可能就越高
4.5 GRE成績和CGPA的關系
plt.scatter(df['GRE Score'],df['CGPA'])
plt.title('CGPA for GRE Scores')
plt.xlabel('GRE Score')
plt.ylabel('CGPA')
plt.show()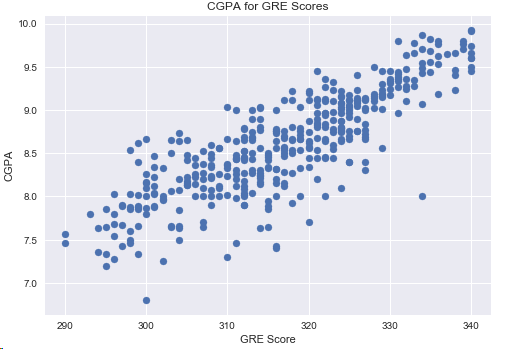
結論:GPA基點越高,GRE分數越高,2者的相關性很大
4.6 托福成績和GRE成績的關系
df[df['CGPA']>=8.5].plot(kind='scatter',x='GRE Score',y='TOEFL Score',color='red')
plt.xlabel('GRE Score')
plt.ylabel('TOEFL Score')
plt.title('CGPA >= 8.5')
plt.grid(True)
plt.show()
結論:多數情況下GRE和托福成正相關,但是GRE分數高,托福一定高。
4.6 學校等級和是否讀碩士的關系
s = df[df['Chance of Admit'] >= 0.75]['University Rating'].value_counts().head(5)
plt.title('University Ratings of Candidates with an 75% acceptance chance')
s.plot(kind='bar',figsize=(20,10),cmap='Pastel1')
plt.xlabel('University Rating')
plt.ylabel('Candidates')
plt.show()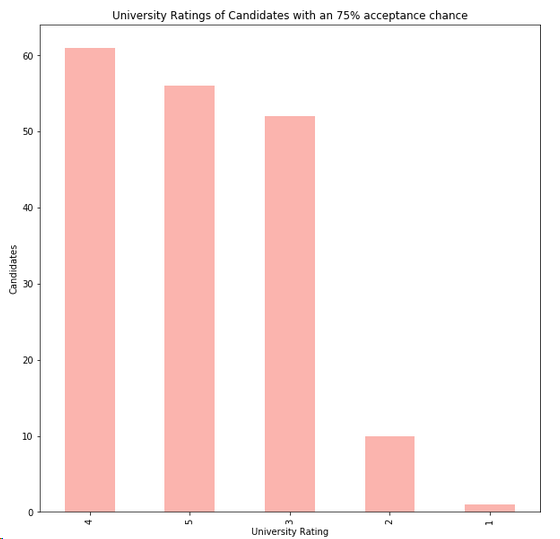
結論:排名靠前的學校的學生,進修的可能性更大
4.7 SOP和GPA的關系
plt.scatter(df['CGPA'],df['SOP'])
plt.xlabel('CGPA')
plt.ylabel('SOP')
plt.title('SOP for CGPA')
plt.show()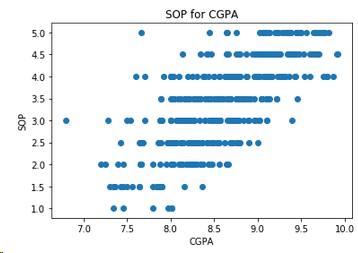
結論: GPA很高的學生,選擇讀碩士的自我意愿更強烈
4.8 SOP和GRE的關系
plt.scatter(df['GRE Score'],df['SOP'])
plt.xlabel('GRE Score')
plt.ylabel('SOP')
plt.title('SOP for GRE Score')
plt.show()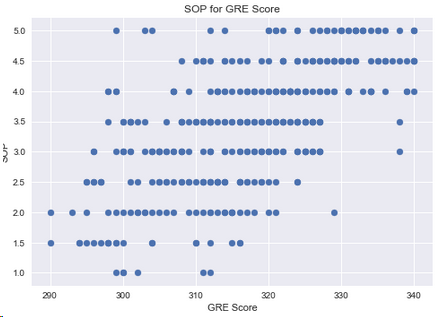
結論:讀碩士意愿強的學生,GRE分數較高
5.模型
5.1 準備數據集
# 讀取數據集
df = pd.read_csv('D:\\machine-learning\\score\\Admission_Predict.csv',sep=',')
serialNO = df['Serial No.'].values
df.drop(['Serial No.'],axis=1,inplace=True)
df = df.rename(columns={'Chance of Admit ':'Chance of Admit'})
# 分割數據集
y = df['Chance of Admit'].values
x = df.drop(['Chance of Admit'],axis=1)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=42)# 歸一化數據 from sklearn.preprocessing import MinMaxScaler scaleX = MinMaxScaler(feature_range=[0,1]) x_train[x_train.columns] = scaleX.fit_transform(x_train[x_train.columns]) x_test[x_test.columns] = scaleX.fit_transform(x_test[x_test.columns])
5.2 回歸
5.2.1 線性回歸
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(x_train,y_train)
y_head_lr = lr.predict(x_test)
print('Real value of y_test[1]: '+str(y_test[1]) + ' -> predict value: ' + str(lr.predict(x_test.iloc[[1],:])))
print('Real value of y_test[2]: '+str(y_test[2]) + ' -> predict value: ' + str(lr.predict(x_test.iloc[[2],:])))
from sklearn.metrics import r2_score
print('r_square score: ',r2_score(y_test,y_head_lr))
y_head_lr_train = lr.predict(x_train)
print('r_square score(train data):',r2_score(y_train,y_head_lr_train))
5.2.2 隨機森林回歸
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(n_estimators=100,random_state=42)
rfr.fit(x_train,y_train)
y_head_rfr = rfr.predict(x_test)
print('Real value of y_test[1]: '+str(y_test[1]) + ' -> predict value: ' + str(rfr.predict(x_test.iloc[[1],:])))
print('Real value of y_test[2]: '+str(y_test[2]) + ' -> predict value: ' + str(rfr.predict(x_test.iloc[[2],:])))
from sklearn.metrics import r2_score
print('r_square score: ',r2_score(y_test,y_head_rfr))
y_head_rfr_train = rfr.predict(x_train)
print('r_square score(train data):',r2_score(y_train,y_head_rfr_train))
5.2.3 決策樹回歸
from sklearn.tree import DecisionTreeRegressor
dt = DecisionTreeRegressor(random_state=42)
dt.fit(x_train,y_train)
y_head_dt = dt.predict(x_test)
print('Real value of y_test[1]: '+str(y_test[1]) + ' -> predict value: ' + str(dt.predict(x_test.iloc[[1],:])))
print('Real value of y_test[2]: '+str(y_test[2]) + ' -> predict value: ' + str(dt.predict(x_test.iloc[[2],:])))
from sklearn.metrics import r2_score
print('r_square score: ',r2_score(y_test,y_head_dt))
y_head_dt_train = dt.predict(x_train)
print('r_square score(train data):',r2_score(y_train,y_head_dt_train))
5.2.4 三種回歸方法比較
y = np.array([r2_score(y_test,y_head_lr),r2_score(y_test,y_head_rfr),r2_score(y_test,y_head_dt)])
x = np.arange(3)
plt.bar(x,y)
plt.title('Comparion of Regression Algorithms')
plt.xlabel('Regression')
plt.ylabel('r2_score')
plt.xticks(x,("LinearRegression","RandomForestReg.","DecisionTreeReg."))
plt.show()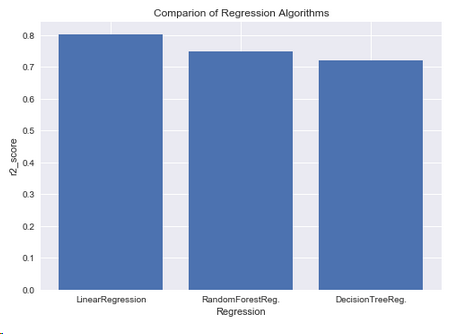
結論 : 回歸算法中,線性回歸的性能更優
5.2.5 三種回歸方法與實際值的比較
red = plt.scatter(np.arange(0,80,5),y_head_lr[0:80:5],color='red')
blue = plt.scatter(np.arange(0,80,5),y_head_rfr[0:80:5],color='blue')
green = plt.scatter(np.arange(0,80,5),y_head_dt[0:80:5],color='green')
black = plt.scatter(np.arange(0,80,5),y_test[0:80:5],color='black')
plt.title('Comparison of Regression Algorithms')
plt.xlabel('Index of candidate')
plt.ylabel('Chance of admit')
plt.legend([red,blue,green,black],['LR','RFR','DT','REAL'])
plt.show()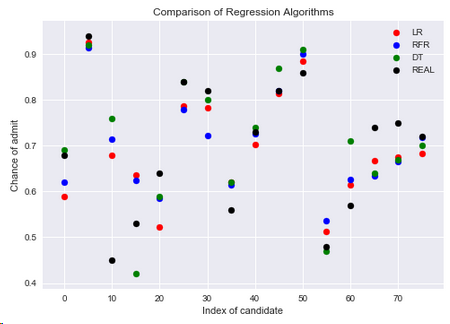
結論:在數據集中有70%的候選人有可能讀碩士,從上圖來看還有些點沒有很好的得到預測
5.3 分類算法
5.3.1 準備數據
df = pd.read_csv('D:\\machine-learning\\score\\Admission_Predict.csv',sep=',')
SerialNO = df['Serial No.'].values
df.drop(['Serial No.'],axis=1,inplace=True)
df = df.rename(columns={'Chance of Admit ':'Chance of Admit'})
y = df['Chance of Admit'].values
x = df.drop(['Chance of Admit'],axis=1)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=42)
from sklearn.preprocessing import MinMaxScaler
scaleX = MinMaxScaler(feature_range=[0,1])
x_train[x_train.columns] = scaleX.fit_transform(x_train[x_train.columns])
x_test[x_test.columns] = scaleX.fit_transform(x_test[x_test.columns])
# 如果chance >0.8, chance of admit 就是1,否則就是0
y_train_01 = [1 if each > 0.8 else 0 for each in y_train]
y_test_01 = [1 if each > 0.8 else 0 for each in y_test]
y_train_01 = np.array(y_train_01)
y_test_01 = np.array(y_test_01)5.3.2 邏輯回歸
from sklearn.linear_model import LogisticRegression
lrc = LogisticRegression()
lrc.fit(x_train,y_train_01)
print('score: ',lrc.score(x_test,y_test_01))
print('Real value of y_test_01[1]: '+str(y_test_01[1]) + ' -> predict value: ' + str(lrc.predict(x_test.iloc[[1],:])))
print('Real value of y_test_01[2]: '+str(y_test_01[2]) + ' -> predict value: ' + str(lrc.predict(x_test.iloc[[2],:])))
from sklearn.metrics import confusion_matrix
cm_lrc = confusion_matrix(y_test_01,lrc.predict(x_test))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_lrc,annot=True,linewidths=0.5,linecolor='red',fmt='.0f',ax=ax)
plt.title('Test for Test dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()
from sklearn.metrics import recall_score,precision_score,f1_score
print('precision_score is : ',precision_score(y_test_01,lrc.predict(x_test)))
print('recall_score is : ',recall_score(y_test_01,lrc.predict(x_test)))
print('f1_score is : ',f1_score(y_test_01,lrc.predict(x_test)))
# Test for Train Dataset:
cm_lrc_train = confusion_matrix(y_train_01,lrc.predict(x_train))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_lrc_train,annot=True,linewidths=0.5,linecolor='blue',fmt='.0f',ax=ax)
plt.title('Test for Train dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()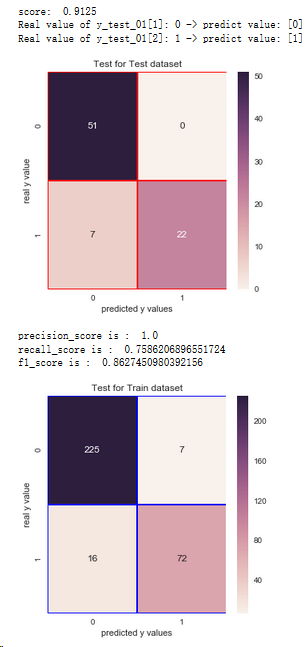
結論:1.通過混淆矩陣,邏輯回歸算法在訓練集樣本上,有23個分錯的樣本,有72人想進一步讀碩士
2.在測試集上有7個分錯的樣本
5.3.3 支持向量機(SVM)
from sklearn.svm import SVC
svm = SVC(random_state=1,kernel='rbf')
svm.fit(x_train,y_train_01)
print('score: ',svm.score(x_test,y_test_01))
print('Real value of y_test_01[1]: '+str(y_test_01[1]) + ' -> predict value: ' + str(svm.predict(x_test.iloc[[1],:])))
print('Real value of y_test_01[2]: '+str(y_test_01[2]) + ' -> predict value: ' + str(svm.predict(x_test.iloc[[2],:])))
from sklearn.metrics import confusion_matrix
cm_svm = confusion_matrix(y_test_01,svm.predict(x_test))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_svm,annot=True,linewidths=0.5,linecolor='red',fmt='.0f',ax=ax)
plt.title('Test for Test dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()
from sklearn.metrics import recall_score,precision_score,f1_score
print('precision_score is : ',precision_score(y_test_01,svm.predict(x_test)))
print('recall_score is : ',recall_score(y_test_01,svm.predict(x_test)))
print('f1_score is : ',f1_score(y_test_01,svm.predict(x_test)))
# Test for Train Dataset:
cm_svm_train = confusion_matrix(y_train_01,svm.predict(x_train))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_svm_train,annot=True,linewidths=0.5,linecolor='blue',fmt='.0f',ax=ax)
plt.title('Test for Train dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()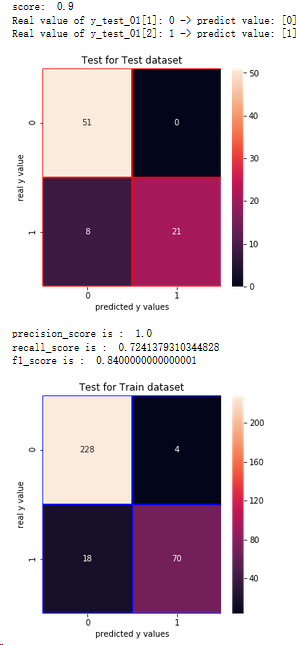
結論:1.通過混淆矩陣,SVM算法在訓練集樣本上,有22個分錯的樣本,有70人想進一步讀碩士
2.在測試集上有8個分錯的樣本
5.3.4 樸素貝葉斯
from sklearn.naive_bayes import GaussianNB
nb = GaussianNB()
nb.fit(x_train,y_train_01)
print('score: ',nb.score(x_test,y_test_01))
print('Real value of y_test_01[1]: '+str(y_test_01[1]) + ' -> predict value: ' + str(nb.predict(x_test.iloc[[1],:])))
print('Real value of y_test_01[2]: '+str(y_test_01[2]) + ' -> predict value: ' + str(nb.predict(x_test.iloc[[2],:])))
from sklearn.metrics import confusion_matrix
cm_nb = confusion_matrix(y_test_01,nb.predict(x_test))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_nb,annot=True,linewidths=0.5,linecolor='red',fmt='.0f',ax=ax)
plt.title('Test for Test dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()
from sklearn.metrics import recall_score,precision_score,f1_score
print('precision_score is : ',precision_score(y_test_01,nb.predict(x_test)))
print('recall_score is : ',recall_score(y_test_01,nb.predict(x_test)))
print('f1_score is : ',f1_score(y_test_01,nb.predict(x_test)))
# Test for Train Dataset:
cm_nb_train = confusion_matrix(y_train_01,nb.predict(x_train))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_nb_train,annot=True,linewidths=0.5,linecolor='blue',fmt='.0f',ax=ax)
plt.title('Test for Train dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()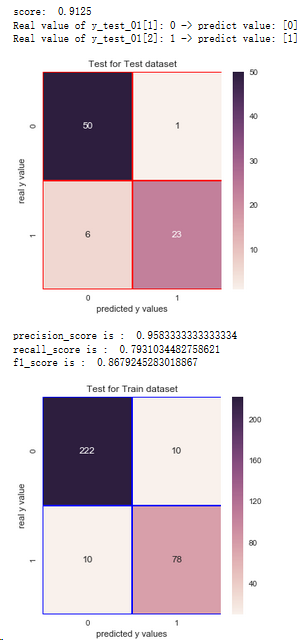
結論:1.通過混淆矩陣,樸素貝葉斯算法在訓練集樣本上,有20個分錯的樣本,有78人想進一步讀碩士
2.在測試集上有7個分錯的樣本
5.3.5 隨機森林分類器
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=100,random_state=1)
rfc.fit(x_train,y_train_01)
print('score: ',rfc.score(x_test,y_test_01))
print('Real value of y_test_01[1]: '+str(y_test_01[1]) + ' -> predict value: ' + str(rfc.predict(x_test.iloc[[1],:])))
print('Real value of y_test_01[2]: '+str(y_test_01[2]) + ' -> predict value: ' + str(rfc.predict(x_test.iloc[[2],:])))
from sklearn.metrics import confusion_matrix
cm_rfc = confusion_matrix(y_test_01,rfc.predict(x_test))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_rfc,annot=True,linewidths=0.5,linecolor='red',fmt='.0f',ax=ax)
plt.title('Test for Test dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()
from sklearn.metrics import recall_score,precision_score,f1_score
print('precision_score is : ',precision_score(y_test_01,rfc.predict(x_test)))
print('recall_score is : ',recall_score(y_test_01,rfc.predict(x_test)))
print('f1_score is : ',f1_score(y_test_01,rfc.predict(x_test)))
# Test for Train Dataset:
cm_rfc_train = confusion_matrix(y_train_01,rfc.predict(x_train))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_rfc_train,annot=True,linewidths=0.5,linecolor='blue',fmt='.0f',ax=ax)
plt.title('Test for Train dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()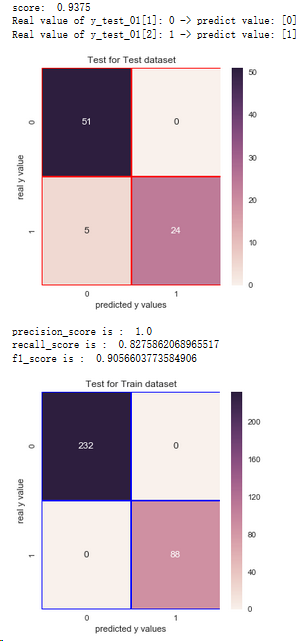
結論:1.通過混淆矩陣,隨機森林算法在訓練集樣本上,有0個分錯的樣本,有88人想進一步讀碩士
2.在測試集上有5個分錯的樣本
5.3.6 決策樹分類器
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier(criterion='entropy',max_depth=3)
dtc.fit(x_train,y_train_01)
print('score: ',dtc.score(x_test,y_test_01))
print('Real value of y_test_01[1]: '+str(y_test_01[1]) + ' -> predict value: ' + str(dtc.predict(x_test.iloc[[1],:])))
print('Real value of y_test_01[2]: '+str(y_test_01[2]) + ' -> predict value: ' + str(dtc.predict(x_test.iloc[[2],:])))
from sklearn.metrics import confusion_matrix
cm_dtc = confusion_matrix(y_test_01,dtc.predict(x_test))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_dtc,annot=True,linewidths=0.5,linecolor='red',fmt='.0f',ax=ax)
plt.title('Test for Test dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()
from sklearn.metrics import recall_score,precision_score,f1_score
print('precision_score is : ',precision_score(y_test_01,dtc.predict(x_test)))
print('recall_score is : ',recall_score(y_test_01,dtc.predict(x_test)))
print('f1_score is : ',f1_score(y_test_01,dtc.predict(x_test)))
# Test for Train Dataset:
cm_dtc_train = confusion_matrix(y_train_01,dtc.predict(x_train))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_dtc_train,annot=True,linewidths=0.5,linecolor='blue',fmt='.0f',ax=ax)
plt.title('Test for Train dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()
結論:1.通過混淆矩陣,決策樹算法在訓練集樣本上,有20個分錯的樣本,有78人想進一步讀碩士
2.在測試集上有7個分錯的樣本
5.3.7 K臨近分類器
from sklearn.neighbors import KNeighborsClassifier
scores = []
for each in range(1,50):
knn_n = KNeighborsClassifier(n_neighbors = each)
knn_n.fit(x_train,y_train_01)
scores.append(knn_n.score(x_test,y_test_01))
plt.plot(range(1,50),scores)
plt.xlabel('k')
plt.ylabel('Accuracy')
plt.show()
knn = KNeighborsClassifier(n_neighbors=7)
knn.fit(x_train,y_train_01)
print('score 7 : ',knn.score(x_test,y_test_01))
print('Real value of y_test_01[1]: '+str(y_test_01[1]) + ' -> predict value: ' + str(knn.predict(x_test.iloc[[1],:])))
print('Real value of y_test_01[2]: '+str(y_test_01[2]) + ' -> predict value: ' + str(knn.predict(x_test.iloc[[2],:])))
from sklearn.metrics import confusion_matrix
cm_knn = confusion_matrix(y_test_01,knn.predict(x_test))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_knn,annot=True,linewidths=0.5,linecolor='red',fmt='.0f',ax=ax)
plt.title('Test for Test dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()
from sklearn.metrics import recall_score,precision_score,f1_score
print('precision_score is : ',precision_score(y_test_01,knn.predict(x_test)))
print('recall_score is : ',recall_score(y_test_01,knn.predict(x_test)))
print('f1_score is : ',f1_score(y_test_01,knn.predict(x_test)))
# Test for Train Dataset:
cm_knn_train = confusion_matrix(y_train_01,knn.predict(x_train))
f,ax = plt.subplots(figsize=(5,5))
sns.heatmap(cm_knn_train,annot=True,linewidths=0.5,linecolor='blue',fmt='.0f',ax=ax)
plt.title('Test for Train dataset')
plt.xlabel('predicted y values')
plt.ylabel('real y value')
plt.show()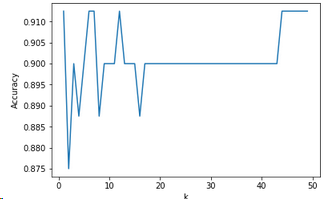
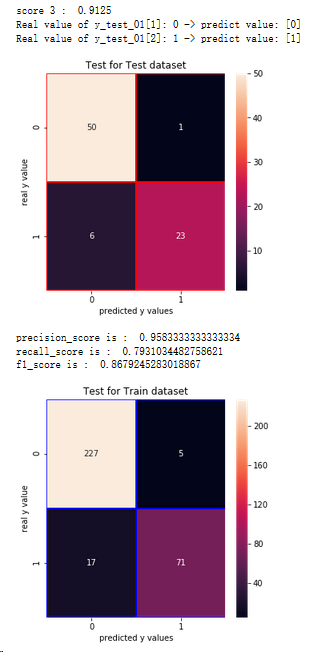
結論:1.通過混淆矩陣,K臨近算法在訓練集樣本上,有22個分錯的樣本,有71人想進一步讀碩士
2.在測試集上有7個分錯的樣本
5.3.8 分類器比較
y = np.array([lrc.score(x_test,y_test_01),svm.score(x_test,y_test_01),nb.score(x_test,y_test_01),
dtc.score(x_test,y_test_01),rfc.score(x_test,y_test_01),knn.score(x_test,y_test_01)])
x = np.arange(6)
plt.bar(x,y)
plt.title('Comparison of Classification Algorithms')
plt.xlabel('Classification')
plt.ylabel('Score')
plt.xticks(x,("LogisticReg.","SVM","GNB","Dec.Tree","Ran.Forest","KNN"))
plt.show()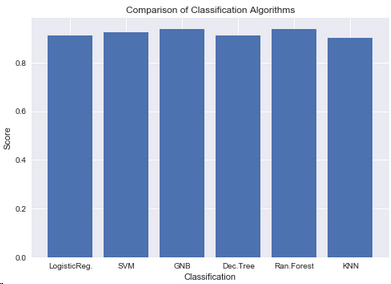
結論:隨機森林和樸素貝葉斯二者的預測值都比較高
5.4 聚類算法
5.4.1 準備數據
df = pd.read_csv('D:\\machine-learning\\score\\Admission_Predict.csv',sep=',')
df = df.rename(columns={'Chance of Admit ':'Chance of Admit'})
serialNo = df['Serial No.']
df.drop(['Serial No.'],axis=1,inplace=True)
df = (df - np.min(df)) / (np.max(df)-np.min(df))
y = df['Chance of Admit']
x = df.drop(['Chance of Admit'],axis=1)5.4.2 降維
from sklearn.decomposition import PCA
pca = PCA(n_components=1,whiten=True)
pca.fit(x)
x_pca = pca.transform(x)
x_pca = x_pca.reshape(400)
dictionary = {'x':x_pca,'y':y}
data = pd.DataFrame(dictionary)
print('pca data:',data.head())
print()
print('orin data:',df.head())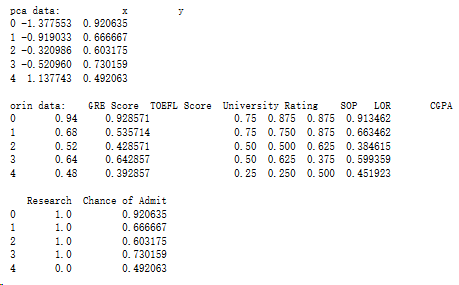
5.4.3 K均值聚類
from sklearn.cluster import KMeans
wcss = []
for k in range(1,15):
kmeans = KMeans(n_clusters=k)
kmeans.fit(x)
wcss.append(kmeans.inertia_)
plt.plot(range(1,15),wcss)
plt.xlabel('Kmeans')
plt.ylabel('WCSS')
plt.show()
df["Serial No."] = serialNo
kmeans = KMeans(n_clusters=3)
clusters_knn = kmeans.fit_predict(x)
df['label_kmeans'] = clusters_knn
plt.scatter(df[df.label_kmeans == 0 ]["Serial No."],df[df.label_kmeans == 0]['Chance of Admit'],color = "red")
plt.scatter(df[df.label_kmeans == 1 ]["Serial No."],df[df.label_kmeans == 1]['Chance of Admit'],color = "blue")
plt.scatter(df[df.label_kmeans == 2 ]["Serial No."],df[df.label_kmeans == 2]['Chance of Admit'],color = "green")
plt.title("K-means Clustering")
plt.xlabel("Candidates")
plt.ylabel("Chance of Admit")
plt.show()
plt.scatter(data.x[df.label_kmeans == 0 ],data[df.label_kmeans == 0].y,color = "red")
plt.scatter(data.x[df.label_kmeans == 1 ],data[df.label_kmeans == 1].y,color = "blue")
plt.scatter(data.x[df.label_kmeans == 2 ],data[df.label_kmeans == 2].y,color = "green")
plt.title("K-means Clustering")
plt.xlabel("X")
plt.ylabel("Chance of Admit")
plt.show()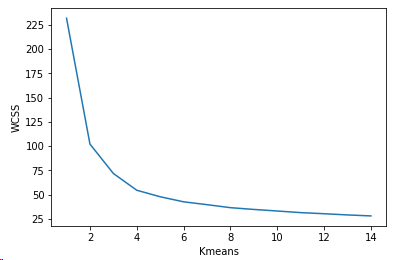
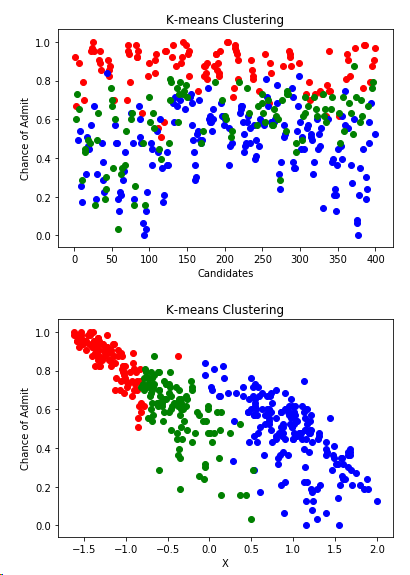
結論:數據集分成三個類別,一部分學生是決定繼續讀碩士,一部分放棄,還有一部分學生的比較猶豫,但是深造的可能性較大
5.4.4 層次聚類
from scipy.cluster.hierarchy import linkage,dendrogram
merg = linkage(x,method='ward')
dendrogram(merg,leaf_rotation=90)
plt.xlabel('data points')
plt.ylabel('euclidean distance')
plt.show()
from sklearn.cluster import AgglomerativeClustering
hiyerartical_cluster = AgglomerativeClustering(n_clusters=3,affinity='euclidean',linkage='ward')
clusters_hiyerartical = hiyerartical_cluster.fit_predict(x)
df['label_hiyerartical'] = clusters_hiyerartical
plt.scatter(df[df.label_hiyerartical == 0 ]["Serial No."],df[df.label_hiyerartical == 0]['Chance of Admit'],color = "red")
plt.scatter(df[df.label_hiyerartical == 1 ]["Serial No."],df[df.label_hiyerartical == 1]['Chance of Admit'],color = "blue")
plt.scatter(df[df.label_hiyerartical == 2 ]["Serial No."],df[df.label_hiyerartical == 2]['Chance of Admit'],color = "green")
plt.title('Hierarchical Clustering')
plt.xlabel('Candidates')
plt.ylabel('Chance of Admit')
plt.show()
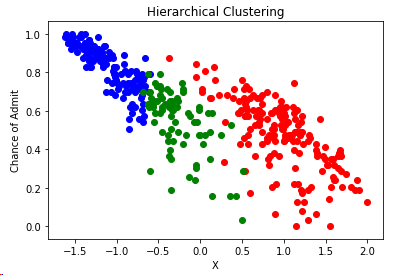
plt.scatter(data[df.label_hiyerartical == 0].x,data.y[df.label_hiyerartical==0],color='red')
plt.scatter(data[df.label_hiyerartical == 1].x,data.y[df.label_hiyerartical==1],color='blue')
plt.scatter(data[df.label_hiyerartical == 2].x,data.y[df.label_hiyerartical==2],color='green')
plt.title('Hierarchical Clustering')
plt.xlabel('X')
plt.ylabel('Chance of Admit')
plt.show()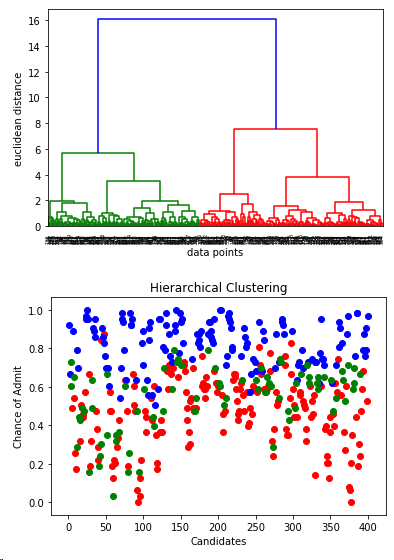
以上是“Python如何根據成績分析系統”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





