溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
初學python,抓取搜狗微信公眾號文章存入mysql
mysql表:
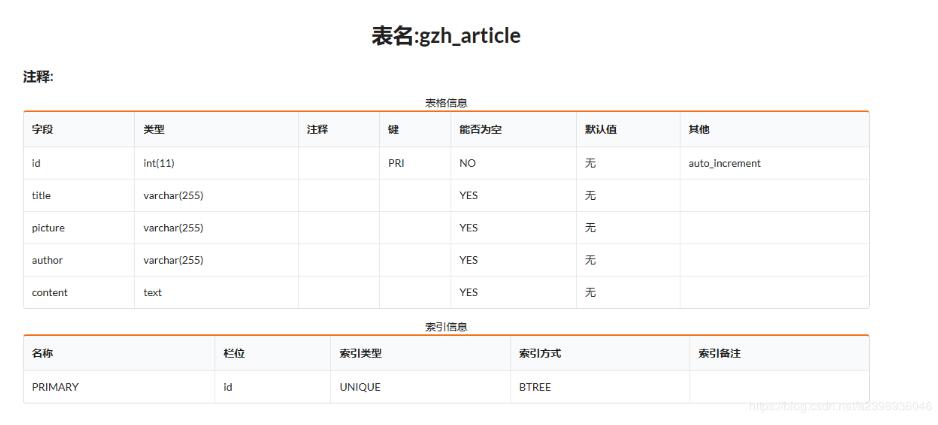
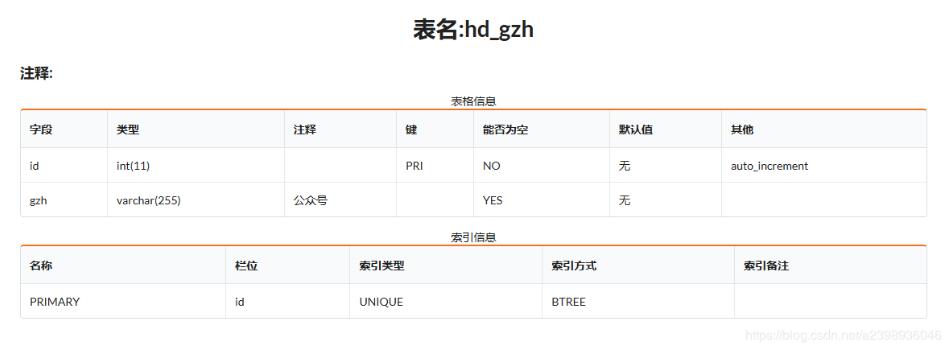
代碼:
import requests
import json
import re
import pymysql
# 創建連接
conn = pymysql.connect(host='你的數據庫地址', port=端口, user='用戶名', passwd='密碼', db='數據庫名稱', charset='utf8')
# 創建游標
cursor = conn.cursor()
cursor.execute("select * from hd_gzh")
effect_row = cursor.fetchall()
from bs4 import BeautifulSoup
socket.setdefaulttimeout(60)
count = 1
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:65.0) Gecko/20100101 Firefox/65.0'}
#阿布云ip代理暫時不用
# proxyHost = "http-cla.abuyun.com"
# proxyPort = "9030"
# # 代理隧道驗證信息
# proxyUser = "H56761606429T7UC"
# proxyPass = "9168EB00C4167176"
# proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
# "host" : proxyHost,
# "port" : proxyPort,
# "user" : proxyUser,
# "pass" : proxyPass,
# }
# proxies = {
# "http" : proxyMeta,
# "https" : proxyMeta,
# }
#查看是否已存在數據
def checkData(name):
sql = "select * from gzh_article where title = '%s'"
data = (name,)
count = cursor.execute(sql % data)
conn.commit()
if(count!=0):
return False
else:
return True
#插入數據
def insertData(title,picture,author,content):
sql = "insert into gzh_article (title,picture,author,content) values ('%s', '%s','%s', '%s')"
data = (title,picture,author,content)
cursor.execute(sql % data)
conn.commit()
print("插入一條數據")
return
for row in effect_row:
newsurl = 'https://weixin.sogou.com/weixin?type=1&s_from=input&query=' + row[1] + '&ie=utf8&_sug_=n&_sug_type_='
res = requests.get(newsurl,headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
url = 'https://weixin.sogou.com' + soup.select('.tit a')[0]['href']
res2 = requests.get(url,headers=headers)
res2.encoding = 'utf-8'
soup2 = BeautifulSoup(res2.text,'html.parser')
pattern = re.compile(r"url \+= '(.*?)';", re.MULTILINE | re.DOTALL)
script = soup2.find("script")
url2 = pattern.search(script.text).group(1)
res3 = requests.get(url2,headers=headers)
res3.encoding = 'utf-8'
soup3 = BeautifulSoup(res3.text,'html.parser')
print()
pattern2 = re.compile(r"var msgList = (.*?);$", re.MULTILINE | re.DOTALL)
script2 = soup3.find("script", text=pattern2)
s2 = json.loads(pattern2.search(script2.text).group(1))
#等待10s
time.sleep(10)
for news in s2["list"]:
articleurl = "https://mp.weixin.qq.com"+news["app_msg_ext_info"]["content_url"]
articleurl = articleurl.replace('&','&')
res4 = requests.get(articleurl,headers=headers)
res4.encoding = 'utf-8'
soup4 = BeautifulSoup(res4.text,'html.parser')
if(checkData(news["app_msg_ext_info"]["title"])):
insertData(news["app_msg_ext_info"]["title"],news["app_msg_ext_info"]["cover"],news["app_msg_ext_info"]["author"],pymysql.escape_string(str(soup4)))
count += 1
#等待5s
time.sleep(10)
for news2 in news["app_msg_ext_info"]["multi_app_msg_item_list"]:
articleurl2 = "https://mp.weixin.qq.com"+news2["content_url"]
articleurl2 = articleurl2.replace('&','&')
res5 = requests.get(articleurl2,headers=headers)
res5.encoding = 'utf-8'
soup5 = BeautifulSoup(res5.text,'html.parser')
if(checkData(news2["title"])):
insertData(news2["title"],news2["cover"],news2["author"],pymysql.escape_string(str(soup5)))
count += 1
#等待10s
time.sleep(10)
cursor.close()
conn.close()
print("操作完成")
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





