溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Python中怎么爬取微信公眾號文章,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
Selenium介紹
Selenium是一個用于web應用程序自動化測試的工具,直接運行在瀏覽器當中,可以通過代碼控制與頁面上元素進行交互,并獲取對應的信息。Selenium很大的一個優點是:不需要復雜地構造請求,訪問參數跟使用瀏覽器的正常用戶一模一樣,訪問行為也相對更像正常用戶,不容易被反爬蟲策略命中,所見即所得。而且在抓取的過程中,必要時還可人工干預(比如登錄、輸入驗證碼等)。
Selenium常常是面對一個嚴格反爬網站無從入手時的保留武器。當然也有缺點:操作均需要等待頁面加載完畢后才可以繼續進行,所以速度要慢,效率不高(某些情況下使用headless和無圖模式會提高一點效率)。
需求很明確:獲取一個公眾號全部推文的標題、日期、鏈接。微信自身的推文功能只能通過其App查看,對App的抓取比較復雜。有一個很方便的替代途徑就是通過搜狗微信檢索。不過如果直接使用Requests等庫直接請求,會涉及的反爬措施有cookie設置,js加密等等,所以今天就利用Selenium大法!
首先導入所需的庫和實例化瀏覽器對象:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# 導入第2-4行是為了馬上會提到的 顯式等待
import time
import datetime
driver = webdriver.Chrome()
driver.get('https://weixin.sogou.com/')上述的代碼就可以實現打開搜狗微信搜索的操作,接下來需要往搜索框里輸入文字,并且點擊“搜文章”(不直接點搜公眾號是因為已經取消通過公眾號直接獲取相應文章的功能)
wait = WebDriverWait(driver, 10)
input = wait.until(EC.presence_of_element_located((By.NAME, 'query')))
input.send_keys('早起Python')
driver.find_element_by_xpath("//input[@class='swz']").click()邏輯是設定最長等待時間,在10s內發現了輸入框已經加載出來后就輸入公眾號名稱,這里我們以“早起Python”為例,并且根據“搜文章”按鈕的xpath獲取該位置并點擊,這里就用到了顯式等待。Selenium請求網頁等待響應受到網速牽制,如果元素未加載全而代碼執行過快就會意外報錯而終止,解決方式是等待。
隱式等待是在嘗試發現某個元素的時候,如果沒能立刻發現,就等待固定長度的時間driver.implicitly_wait(10),顯示等待明確了等待條件,只有該條件觸發,才執行后續代碼,如這里我用到的代碼,當然也可以用time模塊之間設定睡眠時間,睡完了再運行后續代碼。
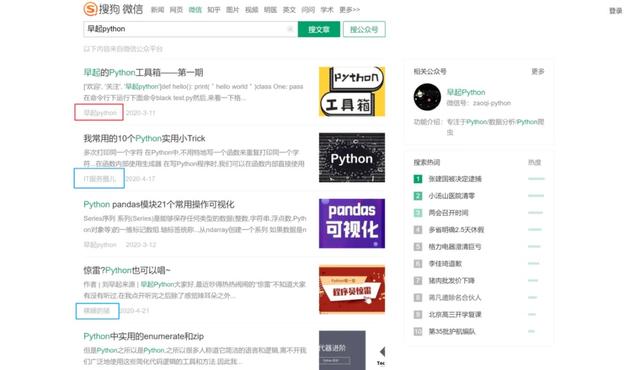
另外只能獲取前10頁100條的結果,查看后續頁面需要微信掃碼登錄:
因此從這里開始,代碼的執行邏輯為:
第10頁遍歷完成后自動點擊登錄,此時需要人工介入,掃碼完成登錄
代碼檢測登錄是否完成(可以簡化為識別“下一頁”按鈕是否出現),如果登錄完成則繼續從11頁遍歷到最后一頁(沒有“下一頁”按鈕)
由于涉及兩次遍歷則可以將解析信息包裝成函數:
num = 0
def get_news():
global num # 放全局變量是為了給符合條件的文章記序
time.sleep(1)
news_lst = driver.find_elements_by_xpath("//li[contains(@id,'sogou_vr_11002601_box')]")
for news in news_lst:
# 獲取公眾號來源
source = news.find_elements_by_xpath('div[2]/div/a')[0].text
if '早起' not in source:
continue
num += 1
# 獲取文章標題
title = news.find_elements_by_xpath('div[2]/h4/a')[0].text
# 獲取文章發表日期
date = news.find_elements_by_xpath('div[2]/div/span')[0].text
# 文章發表的日期如果較近可能會顯示“1天前” “12小時前” “30分鐘前”
# 這里可以用`datetime`模塊根據時間差求出具體時間
# 然后解析為`YYYY-MM-DD`格式
if '前' in date:
today = datetime.datetime.today()
if '天' in date:
delta = datetime.timedelta(days=int(date[0]))
elif '小時' in date:
delta = datetime.timedelta(hours=int(date.replace('小時前', ' ')))
else:
delta = datetime.timedelta(minutes=int(date.replace('分鐘前', ' ')))
date = str((today - delta).strftime('%Y-%m-%d'))
date = datetime.datetime.strptime(date, '%Y-%m-%d').strftime('%Y-%m-%d')
# 獲取url
url = news.find_elements_by_xpath('div[2]/h4/a')[0].get_attribute('href')
print(num, title, date)
print(url)
print('-' * 10)
for i in range(10):
get_news()
if i == 9:
# 如果遍歷到第十頁則跳出循環不需要點擊“下一頁”
break
driver.find_element_by_id("sogou_next").click()接下來就是點擊“登錄”,然后人工完成掃碼,可以利用while True檢測登錄是否成功,是否出現了下一頁按鈕,如果出現則跳出循環,點擊“下一頁”按鈕并繼續后面的代碼,否則睡3秒后重復檢測:
driver.find_element_by_name('top_login').click()
while True:
try:
next_page = driver.find_element_by_id("sogou_next")
break
except:
time.sleep(3)
next_page.click()效果如圖:
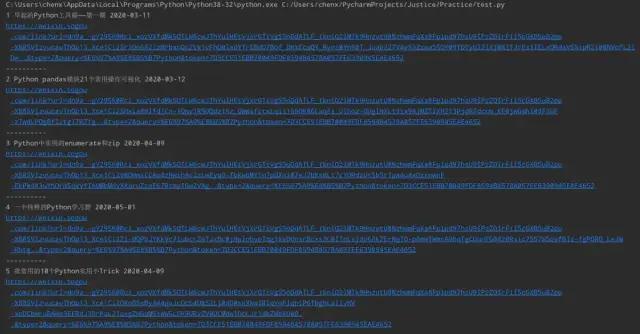
然后就是重新遍歷文章了,由于不知道最后一頁是第幾頁可以使用while循環反復調用解析頁面的函數半點擊“下一頁”,如果不存在下一頁則結束循環:
while True:
get_news()
try:
driver.find_element_by_id("sogou_next").click()
except:
break
# 最后退出瀏覽器即可
driver.quit()看完上述內容,你們對Python中怎么爬取微信公眾號文章有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





