溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python如何實現字符型圖片驗證碼識別完整過程詳解,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
1摘要
驗證碼是目前互聯網上非常常見也是非常重要的一個事物,充當著很多系統的防火墻功能,但是隨時OCR技術的發展,驗證碼暴露出來的安全問題也越來越嚴峻。本文介紹了一套字符驗證碼識別的完整流程,對于驗證碼安全和OCR識別技術都有一定的借鑒意義。
2關鍵詞
關鍵詞:安全,字符圖片,驗證碼識別,OCR,Python,SVM,PIL
3免責聲明
本文研究所用素材來自于某舊Web框架的網站完全對外公開的公共圖片資源。
本文只做了該網站對外公開的公共圖片資源進行了爬取,并未越權做任何多余操作。
本文在書寫相關報告的時候已經隱去漏洞網站的身份信息。
本文作者已經通知網站相關人員此系統漏洞,并積極向新系統轉移。
本報告的主要目的也僅是用于OCR交流學習和引起大家對驗證安全的警覺。
4引言
本章內容作為它的技術補充來給出相應的識別的解決方案,讓讀者對驗證碼的功能及安全性問題有更深刻的認識。
5基本工具
要達到本文的目的,只需要簡單的編程知識即可,因為現在的機器學習領域的蓬勃發展,已經有很多封裝好的開源解決方案來進行機器學習。普通程序員已經不需要了解復雜的數學原理,即可以實現對這些工具的應用了。
主要開發環境:
python3.5
python SDK版本
PIL
圖片處理庫
libsvm
開源的svm機器學習庫
關于環境的安裝,不是本文的重點,故略去。
6基本流程
一般情況下,對于字符型驗證碼的識別流程如下:
1.準備原始圖片素材
2.圖片預處理
3.圖片字符切割
4.圖片尺寸歸一化
5.圖片字符標記
6.字符圖片特征提取
7.生成特征和標記對應的訓練數據集
8.訓練特征標記數據生成識別模型
9.使用識別模型預測新的未知圖片集
10.達到根據“圖片”就能返回識別正確的字符集的目標
7素材準備
7.1素材選擇
由于本文是以初級的學習研究目的為主,要求“有代表性,但又不會太難”,所以就直接在網上找個比較有代表性的簡單的字符型驗證碼(感覺像在找漏洞一樣)。
最后在一個比較舊的網站(估計是幾十年前的網站框架)找到了這個驗證碼圖片。
原始圖:

放大清晰圖:

此圖片能滿足要求,仔細觀察其具有如下特點。
有利識別的特點:
由純阿拉伯數字組成字數為4位字符排列有規律字體是用的統一字體
以上就是本文所說的此驗證碼簡單的重要原因,后續代碼實現中會用到
不利識別的特點:
圖片背景有干擾噪點
這雖然是不利特點,但是這個干擾門檻太低,只需要簡單的方法就可以除去
7.2素材獲取
由于在做訓練的時候,需要大量的素材,所以不可能用手工的方式一張張在瀏覽器中保存,故建議寫個自動化下載的程序。
主要步驟如下:
通過瀏覽器的抓包功能獲取隨機圖片驗證碼生成接口批量請求接口以獲取圖片將圖片保存到本地磁盤目錄中
這些都是一些IT基本技能,本文就不再詳細展開了。
關于網絡請求和文件保存的代碼,如下:
def downloads_pic(**kwargs):
pic_name = kwargs.get('pic_name', None)
url = 'http://xxxx/rand_code_captcha/'
res = requests.get(url, stream=True)
with open(pic_path + pic_name+'.bmp', 'wb') as f:
for chunk in res.iter_content(chunk_size=1024):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
f.flush()
f.close()循環執行N次,即可保存N張驗證素材了。
下面是收集的幾十張素材庫保存到本地文件的效果圖:

8圖片預處理
雖然目前的機器學習算法已經相當先進了,但是為了減少后面訓練時的復雜度,同時增加識別率,很有必要對圖片進行預處理,使其對機器識別更友好。
針對以上原始素材的處理步驟如下:
1.讀取原始圖片素材
2.將彩色圖片二值化為黑白圖片
3.去除背景噪點
8.1二值化圖片
主要步驟如下:
將RGB彩圖轉為灰度圖
將灰度圖按照設定閾值轉化為二值圖
image = Image.open(img_path)
imgry = image.convert('L') # 轉化為灰度圖
table = get_bin_table()
out = imgry.point(table, '1')上面引用到的二值函數的定義如下:
def get_bin_table(threshold=140): """ 獲取灰度轉二值的映射table :param threshold: :return: """ table = [] for i in range(256): if i < threshold: table.append(0) else: table.append(1) return table
由PIL轉化后變成二值圖片:0表示黑色,1表示白色。二值化后帶噪點的6937的像素點輸出后如下圖:
1110111011110111011111011110111100110111
1101111111110110101111110101111111101111
1100111011111000001111111001011111011111
1101111011111111101111011110111111011111
1110000111111000011101100001110111011111
如果你是近視眼,然后離屏幕遠一點,可以隱約看到6937的骨架了。
8.2去除噪點
在轉化為二值圖片后,就需要清除噪點。本文選擇的素材比較簡單,大部分噪點也是最簡單的那種孤立點,所以可以通過檢測這些孤立點就能移除大量的噪點。
關于如何去除更復雜的噪點甚至干擾線和色塊,有比較成熟的算法:洪水填充法 Flood Fill,后面有興趣的時間可以繼續研究一下。
本文為了問題簡單化,干脆就用一種簡單的自己想的簡單辦法來解決掉這個問題:
對某個 黑點 周邊的九宮格里面的黑色點計數
如果黑色點少于2個則證明此點為孤立點,然后得到所有的孤立點
對所有孤立點一次批量移除。
下面將詳細介紹關于具體的算法原理。
將所有的像素點如下圖分成三大類
頂點A非頂點的邊界點B內部點C
種類點示意圖如下:
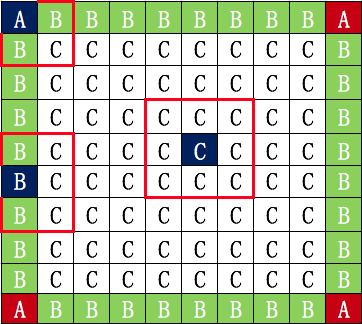
其中:
?A類點計算周邊相鄰的3個點(如上圖紅框所示)
?B類點計算周邊相鄰的5個點(如上圖紅框所示)
?C類點計算周邊相鄰的8個點(如上圖紅框所示)
當然,由于基準點在計算區域的方向不同,A類點和B類點還會有細分:
?A類點繼續細分為:左上,左下,右上,右下
?B類點繼續細分為:上,下,左,右
?C類點不用細分
然后這些細分點將成為后續坐標獲取的準則。
主要算法的python實現如下:
def sum_9_region(img, x, y):
"""
9鄰域框,以當前點為中心的田字框,黑點個數
:param x:
:param y:
:return:
"""
# todo 判斷圖片的長寬度下限
cur_pixel = img.getpixel((x, y)) # 當前像素點的值
width = img.width
height = img.height
if cur_pixel == 1: # 如果當前點為白色區域,則不統計鄰域值
return 0
if y == 0: # 第一行
if x == 0: # 左上頂點,4鄰域
# 中心點旁邊3個點
sum = cur_pixel \
+ img.getpixel((x, y + 1)) \
+ img.getpixel((x + 1, y)) \
+ img.getpixel((x + 1, y + 1))
return 4 - sum
elif x == width - 1: # 右上頂點
sum = cur_pixel \
+ img.getpixel((x, y + 1)) \
+ img.getpixel((x - 1, y)) \
+ img.getpixel((x - 1, y + 1))
return 4 - sum
else: # 最上非頂點,6鄰域
sum = img.getpixel((x - 1, y)) \
+ img.getpixel((x - 1, y + 1)) \
+ cur_pixel \
+ img.getpixel((x, y + 1)) \
+ img.getpixel((x + 1, y)) \
+ img.getpixel((x + 1, y + 1))
return 6 - sum
elif y == height - 1: # 最下面一行
if x == 0: # 左下頂點
# 中心點旁邊3個點
sum = cur_pixel \
+ img.getpixel((x + 1, y)) \
+ img.getpixel((x + 1, y - 1)) \
+ img.getpixel((x, y - 1))
return 4 - sum
elif x == width - 1: # 右下頂點
sum = cur_pixel \
+ img.getpixel((x, y - 1)) \
+ img.getpixel((x - 1, y)) \
+ img.getpixel((x - 1, y - 1))
return 4 - sum
else: # 最下非頂點,6鄰域
sum = cur_pixel \
+ img.getpixel((x - 1, y)) \
+ img.getpixel((x + 1, y)) \
+ img.getpixel((x, y - 1)) \
+ img.getpixel((x - 1, y - 1)) \
+ img.getpixel((x + 1, y - 1))
return 6 - sum
else: # y不在邊界
if x == 0: # 左邊非頂點
sum = img.getpixel((x, y - 1)) \
+ cur_pixel \
+ img.getpixel((x, y + 1)) \
+ img.getpixel((x + 1, y - 1)) \
+ img.getpixel((x + 1, y)) \
+ img.getpixel((x + 1, y + 1))
return 6 - sum
elif x == width - 1: # 右邊非頂點
# print('%s,%s' % (x, y))
sum = img.getpixel((x, y - 1)) \
+ cur_pixel \
+ img.getpixel((x, y + 1)) \
+ img.getpixel((x - 1, y - 1)) \
+ img.getpixel((x - 1, y)) \
+ img.getpixel((x - 1, y + 1))
return 6 - sum
else: # 具備9領域條件的
sum = img.getpixel((x - 1, y - 1)) \
+ img.getpixel((x - 1, y)) \
+ img.getpixel((x - 1, y + 1)) \
+ img.getpixel((x, y - 1)) \
+ cur_pixel \
+ img.getpixel((x, y + 1)) \
+ img.getpixel((x + 1, y - 1)) \
+ img.getpixel((x + 1, y)) \
+ img.getpixel((x + 1, y + 1))
return 9 - sumTips:這個地方是相當考驗人的細心和耐心程度了,這個地方的工作量還是蠻大的,花了半個晚上的時間才完成的。
計算好每個像素點的周邊像素黑點(注意:PIL轉化的圖片黑點的值為0)個數后,只需要篩選出個數為1或者2的點的坐標即為孤立點。這個判斷方法可能不太準確,但是基本上能夠滿足本文的需求了。
經過預處理后的圖片如下所示:

對比文章開頭的原始圖片,那些孤立點都被移除掉,相對比較干凈的驗證碼圖片已經生成。
9圖片字符切割
由于字符型驗證碼圖片本質就可以看著是由一系列的單個字符圖片拼接而成,為了簡化研究對象,我們也可以將這些圖片分解到原子級,即:只包含單個字符的圖片。
于是,我們的研究對象由“N種字串的組合對象”變成“10種阿拉伯數字”的處理,極大的簡化和減少了處理對象。
9.1分割算法
現實生活中的字符驗證碼的產生千奇百怪,有各種扭曲和變形。關于字符分割的算法,也沒有很通用的方式。這個算法也是需要開發人員仔細研究所要識別的字符圖片的特點來制定的。
當然,本文所選的研究對象盡量簡化了這個步驟的難度,下文將慢慢進行介紹。
使用圖像編輯軟件(PhoneShop或者其它)打開驗證碼圖片,放大到像素級別,觀察其它一些參數特點:

可以得到如下參數:
?整個圖片尺寸是 40*10
?單個字符尺寸是 6*10
?左右字符和左右邊緣相距2個像素
?字符上下緊挨邊緣(即相距0個像素)
這樣就可以很容易就定位到每個字符在整個圖片中占據的像素區域,然后就可以進行分割了,具體代碼如下:
def get_crop_imgs(img): """ 按照圖片的特點,進行切割,這個要根據具體的驗證碼來進行工作. # 見原理圖 :param img: :return: """ child_img_list = [] for i in range(4): x = 2 + i * (6 + 4) # 見原理圖 y = 0 child_img = img.crop((x, y, x + 6, y + 10)) child_img_list.append(child_img) return child_img_list
然后就能得到被切割的原子級的圖片元素了:
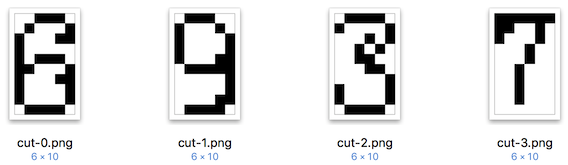
9.2內容小結
基于本部分的內容的討論,相信大家已經了解到了,如果驗證碼的干擾(扭曲,噪點,干擾色塊,干擾線……)做得不夠強的話,可以得到如下兩個結論:
4位字符和40000位字符的驗證碼區別不大
純數字和數字及字母組合的驗證碼區別不大
純數字。分類數為10
純字母
不區分大小寫。分類數為26
區分大小寫。分類數為52
數字和區分大小寫的字母組合。分類數為62
在沒有形成指數級或者幾何級的難度增加,而只是線性有限級增加計算量時,意義不太大。
10尺寸歸一
本文所選擇的研究對象本身尺寸就是統一狀態:6*10的規格,所以此部分不需要額外處理。但是一些進行了扭曲和縮放的驗證碼,則此部分也會是一個圖像處理的難點。
11模型訓練步驟
在前面的環節,已經完成了對單個圖片的處理和分割了。后面就開始進行識別模型的訓練了。
整個訓練過程如下:
1.大量完成預處理并切割到原子級的圖片素材準備
2.對素材圖片進行人為分類,即:打標簽
3.定義單張圖片的識別特征
4.使用SVM訓練模型對打了標簽的特征文件進行訓練,得到模型文件
12素材準備
本文在訓練階段重新下載了同一模式的4數字的驗證圖片總計:3000張。然后對這3000張圖片進行處理和切割,得到12000張原子級圖片。
在這12000張圖片中刪除一些會影響訓練和識別的強干擾的干擾素材,切割后的效果圖如下:

13素材標記
由于本文使用的這種識別方法中,機器在最開始是不具備任何 數字的觀念的。所以需要人為的對素材進行標識,告訴機器什么樣的圖片的內容是 1……。
這個過程叫做“標記”。
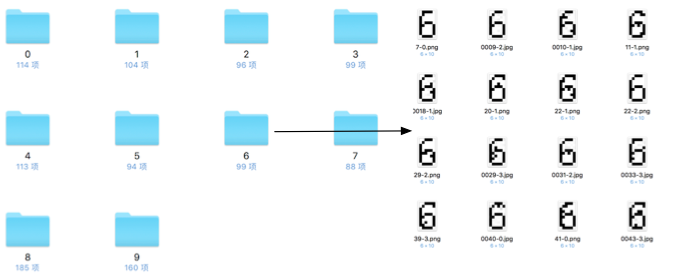
具體打標簽的方法是:
為0~9每個數字建立一個目錄,目錄名稱為相應數字(相當于標簽)
人為判定圖片內容,并將圖片拖到指定數字目錄中
每個目錄中存放100張左右的素材
一般情況下,標記的素材越多,那么訓練出的模型的分辨能力和預測能力越強。例如本文中,標記素材為十多張的時候,對新的測試圖片識別率基本為零,但是到達100張時,則可以達到近乎100%的識別率
14特征選擇
對于切割后的單個字符圖片,像素級放大圖如下:

從宏觀上看,不同的數字圖片的本質就是將黑色按照一定規則填充在相應的像素點上,所以這些特征都是最后圍繞像素點進行。
字符圖片寬6個像素,高10個像素,理論上可以最簡單粗暴地可以定義出60個特征:60個像素點上面的像素值。但是顯然這樣高維度必然會造成過大的計算量,可以適當的降維。
通過查閱相應的文獻[2],給出另外一種簡單粗暴的特征定義:
每行上黑色像素的個數,可以得到10個特征
每列上黑色像素的個數,可以得到6個特征
最后得到16維的一組特征,實現代碼如下:
def get_feature(img): """ 獲取指定圖片的特征值, 1. 按照每排的像素點,高度為10,則有10個維度,然后為6列,總共16個維度 :param img_path: :return:一個維度為10(高度)的列表 """ width, height = img.size pixel_cnt_list = [] height = 10 for y in range(height): pix_cnt_x = 0 for x in range(width): if img.getpixel((x, y)) == 0: # 黑色點 pix_cnt_x += 1 pixel_cnt_list.append(pix_cnt_x) for x in range(width): pix_cnt_y = 0 for y in range(height): if img.getpixel((x, y)) == 0: # 黑色點 pix_cnt_y += 1 pixel_cnt_list.append(pix_cnt_y) return pixel_cnt_list
然后就將圖片素材特征化,按照libSVM指定的格式生成一組帶特征值和標記值的向量文件。內容示例如下:

說明如下:
1.第一列是標簽列,即此圖片人為標記值,后續還有其它數值1~9的標記
2.后面是16組特征值,冒號前面是索引號,后面是值
3.如果有1000張訓練圖片,那么會產生1000行的記錄
對此文件格式有興趣的同學,可以到libSVM官網搜索更多的資料。
15模型訓練
到這個階段后,由于本文直接使用的是開源的libSVM方案,屬于應用了,所以此處內容就比較簡單的。只需要輸入特征文件,然后輸出模型文件即可。
可以搜索到很多相關中文資料[1]。
主要代碼如下:
def train_svm_model(): """ 訓練并生成model文件 :return: """ y, x = svm_read_problem(svm_root + '/train_pix_feature_xy.txt') model = svm_train(y, x) svm_save_model(model_path, model)
備注:生成的模型文件名稱為svm_model_file
16模型測試
訓練生成模型后,需要使用訓練集之外的全新的標記后的圖片作為測試集來對模型進行測試。
本文中的測試實驗如下:
使用一組全部標記為8的21張圖片來進行模型測試
測試圖片生成帶標記的特征文件名稱為last_test_pix_xy_new.txt
在早期訓練集樣本只有每字符十幾張圖的時候,雖然對訓練集樣本有很好的區分度,但是對于新樣本測試集基本沒區分能力,識別基本是錯誤的。逐漸增加標記為8的訓練集的樣本后情況有了比較好的改觀:
到60張左右的時候,正確率大概80%
到185張的時候,正確率基本上達到100%
以數字8的這種模型強化方法,繼續強化對數字0~9中的其它數字的模型訓練,最后可以達到對所有的數字的圖片的識別率達到近乎 100%。在本文示例中基本上每個數字的訓練集在100張左右時,就可以達到100%的識別率了。
模型測試代碼如下:
def svm_model_test():
"""
使用測試集測試模型
:return:
"""
yt, xt = svm_read_problem(svm_root + '/last_test_pix_xy_new.txt')
model = svm_load_model(model_path)
p_label, p_acc, p_val = svm_predict(yt, xt, model)#p_label即為識別的結果
cnt = 0
for item in p_label:
print('%d' % item, end=',')
cnt += 1
if cnt % 8 == 0:
print('')至此,驗證的識別工作算是完滿結束。
17完整識別流程
在前面的環節,驗證碼識別的相關工具集都準備好了。然后對指定的網絡上的動態驗證碼形成持續不斷地識別,還需要另外寫一點代碼來組織這個流程,以形成穩定的黑盒的驗證碼識別接口。
主要步驟如下:
1.傳入一組驗證碼圖片
2.對圖片進行預處理:去噪,二值等等
3.切割成4張有序的單字符圖片
4.使用模型文件分別對4張圖片進行識別
5.將識別結果拼接
6.返回識別結果
然后本文中,請求某網絡驗證碼的http接口,獲得驗證碼圖片,識別出結果,以此結果作為名稱保存此驗證圖片。效果如下:

顯然,已經達到幾乎100%的識別率了。
在本算法沒有做任何優化的情況下,在目前主流配置的PC機上運行此程序,可以實現200ms識別一個(很大的耗時來自網絡請求的阻塞)。
18效率優化
后期通過優化的方式可以達到更好的效率。
軟件層次優化
1.將圖片資源的網絡請求部分做成異步非阻塞模式
2.利用好多核CPU,多進程并行運行
3.在圖片特征上認真挑選和實驗,降低維度
預計可以達到1s識別10到100個驗證碼的樣子。
硬件層次優化
1.粗暴地增加CPU性能
2.粗暴地增加運行機器
基本上,10臺4核心機器同時請求,保守估計效率可以提升到1s識別1萬個驗證碼。
19互聯網安全警示
如果驗證碼被識別出來后,會有什么安全隱患呢?
在大家通過上一小節對識別效率有了認識之后,再提到這樣的場景,大家會有新的看法了吧:
12306火車售票網,春節期間早上8:00某車次放出的500張票,1s內全部被搶光,最后發現正常需求的人搶不到票,但是黃牛卻大大的有票某某手機網站,早上10:00開啟搶購活動,守候了許久的無數的你都鎩羽而歸,但是同樣黃牛卻大量有貨
暫先不管后面有沒有手續上的黑幕,在一切手續合法的情況下,只要通過技術手段識別掉了驗證碼,再通過計算機強大的計算力和自動化能力,將大量資源搶到少數黃牛手中在技術是完全可行的。
所以今后大家搶不到票不爽的時候,可以繼續罵12306,但是不要罵它有黑幕了,而是罵他們IT技術不精吧。
關于一個驗證碼失效,即相當于沒有驗證碼的系統,再沒有其它風控策略的情況下,那么這個系統對于代碼程序來就就完全如入無人之境。
目前確實有一些web應用系統連驗證碼都沒有,只能任人宰割即使web應用系統有驗證碼但是難度不夠,也只能任人宰割
所以,這一塊雖然小,但是安全問題不能忽視。
20積極應用場景
本文介紹的其實是一項簡單的OCR技術實現。有一些很好同時也很有積極進步意義的應用場景:
?銀行卡號識別
?身份證號識別
?車牌號碼識別
這些場景有具有和本文所研究素材很相似的特點:
1.字體單一
2.字符為簡單的數字或字母組合
3.文字的排列是標準化統一化的
所以如果拍照時原始數據采集比較規范的情況下,識別起來應該難度也不大。
21小結
本文只是選取了一個比較典型的而且比較簡單的驗證碼的識別作為示例,但是基本上能表述出一個識別此類驗證碼的完整流程,可以供大家交流學習。
由于目前全球的IT技術實力參差不齊,現在很多舊的IT系統里面都存在一些舊的頁面框架,里面使用的驗證碼也是相當古老,對于當下的一些識別技術來說,完全不堪一擊。比如,我看到一些在校大學生就直接拿自己學校的教務系統的驗證碼來開刀練習的。
最后,本文特意提出如下倡議:
對于掌握OCR技術的人
?不要做違法的事,因為目前被抓的“白帽子”的新聞也蠻多的
?在不違法的情況下,還是可以向存在漏洞的系統管理員提出善意提醒
?以自己的專業知識,多做一些促進社會進步,提升社會生產力的事情,如紙書電子化等等
對于仍然沿用舊的落后的IT系統的公司或者機構相關人員
應該盡快認識到事情的嚴重性,趕緊升級自己的系統,或者將這一塊業務交付給專門的安全公司
關于“Python如何實現字符型圖片驗證碼識別完整過程詳解”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





