溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
最近正在研究人工智能,為了加深對算法的理解,決定寫個自動設別驗證碼的程序。看了看網上的demo,大部分都是python2的寫法,而且驗證碼的識別都是用的數字做例子,那我就寫個基于python3字母識別的程序,不過一路寫下來碰到不少坑,大家感興趣的話可以慢慢看。
圖片識別有幾個比較大的步驟是必須完成的:
1、有大量的驗證碼圖片作為樣本
2、圖片要進行處理 流程是:灰度化==》二值化==》字符切割==》識別分類
3、圖像識別要提取特征值,然后把圖片二值化的數據當做樣本做訓練,最后基于樣本完成對新驗證碼的識別
一、大量驗證碼準備
因為要寫字母識別,所以需要大量的字母驗證碼,正好之前做過某電商的項目,印象中是純字母的查了下果然是的所以就用那個網站作為例子了。
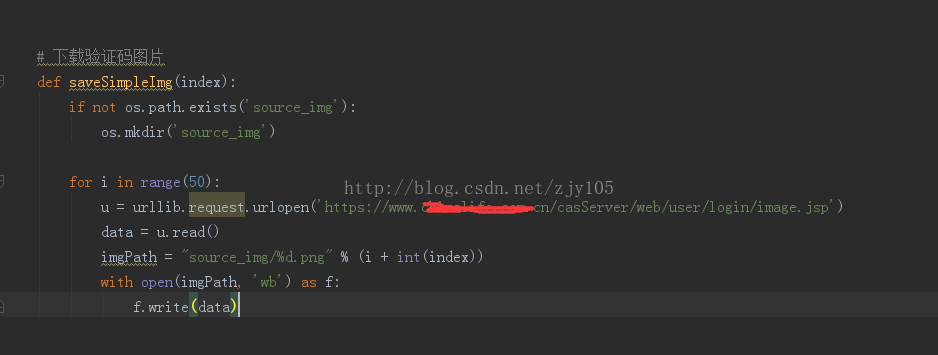
獲取驗證碼方法很簡單,找到驗證碼動態生成的地址,
然后調用python的urllib.request獲得圖片然后保存就好了
二、圖片的灰度化和二值化
其實為了增強識別率,我們將彩色的圖片灰度化,
這樣就變成了黑白兩色,黑的是255白的是0,這樣更容易讓機器來識別。
灰度化和二值化之前、后的效果圖

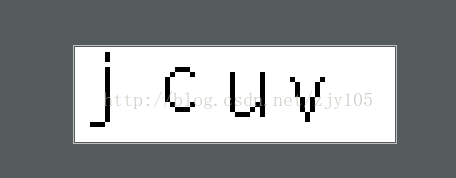
三、圖片的分割
經過觀察驗證碼可以發現,驗證碼是4位的字母,
同時驗證碼直接是有空白分隔的(后面的驗證碼有黏連的單獨講)
這里使用垂直投影法,根據投影進行圖片的切割。這個算法講起來太復雜,看代碼吧。。。
效果如下,反正就是切成了4個圖片




四、識別分類
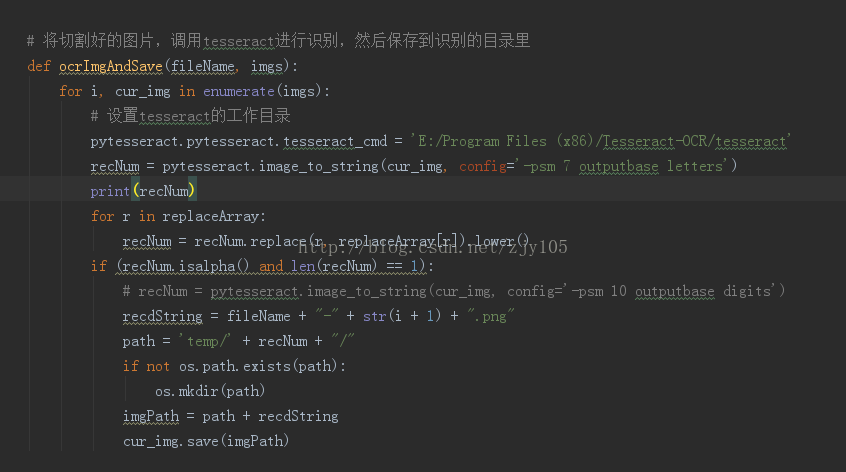
這里因為圖片太多了,要對每個圖片分26個字母的哪一個太麻煩,所以借用Google的tesseract這個OCR的軟件,用它來幫我識別下圖片是哪個字母(當然它識別的成功率不高,不然也不用人工智能了),然后識別錯誤的我再手動分類。
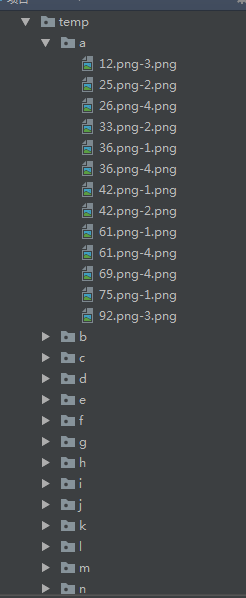
經過ocr識別和人工分類后,我的temp目錄下就變成了這樣的,每個目錄下都是正確的字母圖片
五、提取特征值
將字母的文件夾圖片取出,提取特征值然后存儲到文本文件里

六、機器訓練
這里使用sklearn.svm這個支持向量機的算法,來對數據進行分類。
SVM的算法是啥,可以看看知乎大神的講解https://www.zhihu.com/question/21094489 ,
通過fit進行訓練后,將訓練的結果保存到pkl文件里,其實里面都是0和1的特征值

七、最后的驗證就很簡單了
找個驗證碼圖片,調用之前的方法,變成二值化的數據,然后用SVM進行識別,就能得到正確的結果了
八、滴水算法(解決黏連問題)
這個驗證碼也不是完全都有空格分割好的,可能是長這樣的,字母直接黏在一起了

這樣的字母為了分割出來,就要用滴水算法,模擬水滴重力下落的過程,自動切分圖片。
可以看我的water.py文件里面是詳細的算法。
講講碰到的坑
1、python3不能用opencv了,尤其是cv2.cv方法只是python2用的,不用他換個python寫法一樣可以實現
2、原始圖片有藍色邊,剛開始老識別錯誤,后來發現問題后,要先進行切割,保證只有字母是有顏色的,其它區域是白色的。
這個是cutImg方法的作用
3、使用Google的ocr時,使用了python的pytesseract,這個要先在電腦安裝Tesseract-OCR,然后要在程序里指定路徑才行,
不然會報錯誤的。pytesseract.pytesseract.tesseract_cmd = 'E:/Program Files (x86)/Tesseract-OCR/tesseract'
4、pytesseract.image_to_string(cur_img, config='-psm 7 outputbase letters')
這個letters是我自己創建的,位置在E:\Program Files (x86)\Tesseract-OCR\tessdata\configs 這里的letters是用來
約束識別范圍的,比如我設置tessedit_char_whitelist abcdefghijklmnopqrstuvwxyz 這就表示只識別字母,這樣
就會把1,0之類的變成l和o了
最后附上github的源碼地址 https://github.com/zjy090/verifyCode (本地下載)
下次研究遺傳算法GA的實現等寫好了也寫個demo分享給大家
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





