溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關使用Pandas對數據進行篩選和排序,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
首選導入需要使用的Pandas庫和numpy庫,讀取并創建數據表,將數據表命名為lc。
import pandas as pd
import numpy as np
lc=pd.DataFrame(pd.read_csv('LoanStats3a.csv',header=1))創建數據表后,開始使用Pandas的.sort函數對數據表進行排序操作,下面是Pandas官方對.sort函數語法和使用方法的說明。.sort函數主要包含6個參數,columns為要進行排序的列名稱, ascending為排序的方式true為升序,False為降序,默認為true。axis為排序的軸,0表示index,1表示columns,當對數據列進行排序時,axis必須設置為0。inplace默認為False,表示對數據 表進行排序,不創建新實例。Kind可選擇排序的方式,如快速排序等。na_position對NaN值的處理方式,可以選擇first和last兩種方式,默認為last,也就是將NaN值放在排序的結尾。

在了解了.sort函數的語法和使用方法后,我們開始使用這個函數對數據進行排序操作,數據源來自Lending Club 2017-2011年的公開數據。首先對單列數據進行排序。
對單列數據進行排序
升序
單列數據的排序的方法很簡單,按照.sort函數中的介紹,寫清楚要排序的數據表名稱,以及要進行排序的列名稱即可。具體的代碼和排序結果如下所示,其中lc是前面我們讀取并創建的數據表名稱,loan_amnt是要進行排序的列名稱。這里我們對lc數據表按loan_amnt列進行升序排列。這里需要說明的是ascending參數的默認值是True,也就是升序。因此下面的兩種寫法效果是一樣的 。
lc.sort(["loan_amnt"]) lc.sort(["loan_amnt"],ascending=True)
降序
將ascending參數的值改為False就完成對數據表的降序排列工作。與升序排列的數據表相比可以發現升序排列將loan_amnt列的最小值放在了前面,因此我們可以判斷loan_amnt的最小金額為500,與之相反,降序排列將最大值放在了前面,因此loan_amnt的最大金額應該為35000。這里我們沒有設置na_position參數的值,因此按默認情況loan_amnt列的NaN值在排序的結尾顯示。以下顯示了降序排列的代碼和結果。
lc.sort(["loan_amnt"],ascending=False)
對多列數據進行排序
除了對單列數據進行排序以外,.sort函數還可以對多列數據進行排序操作。下面我們分別對loan_amnt和int_rate字段進行降序排列,以下是具體的代碼和排序結果,與單列數據排序的代碼相比,這里只增加了一個新的列名稱int_rate。
lc.sort(["loan_amnt","int_rate"],ascending=False)
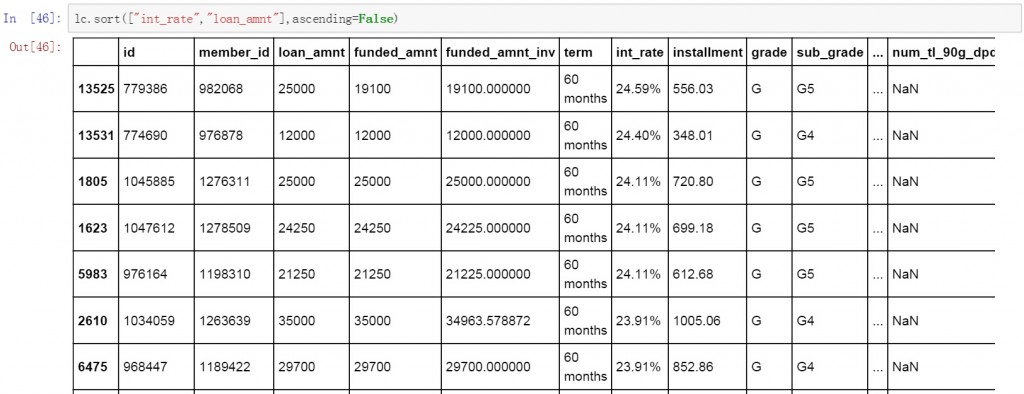
我們將需要排序的兩個列名稱互換位置,再次執行降序排列操作。觀察兩次的排序結果可以發現,這次的結果與之前的結果有一些差異。Loan_amnt字段的排序結果有些混亂,有些較小的值排在了較大值的前面。這是因為第一次排序時loan_amnt是第一排序字段,int_rate是第二排序字段。兩個字段交換位置第二次排序后,int_rate變成了第一排序字段,loan_amnt變成了第二排序字段 。
lc.sort(["int_rate","loan_amnt"],ascending=False)
獲取金額最小前10項
在完成了對數據表排序的操作后,我們可以對數據表進行簡單的篩選,例如獲取loan_amnt金額最小的前10名數據。具體的方法是先對lc數據表按loan_amnt升序排列,然后取前10名的數據。NaN值默認在排序結果的結尾顯示。以下是具體代碼和結果。與前面單列升序排列的代碼相比只在結尾增加了.head()函數。
lc.sort(["loan_amnt"],ascending=True).head(10)
獲取金額最大前10項
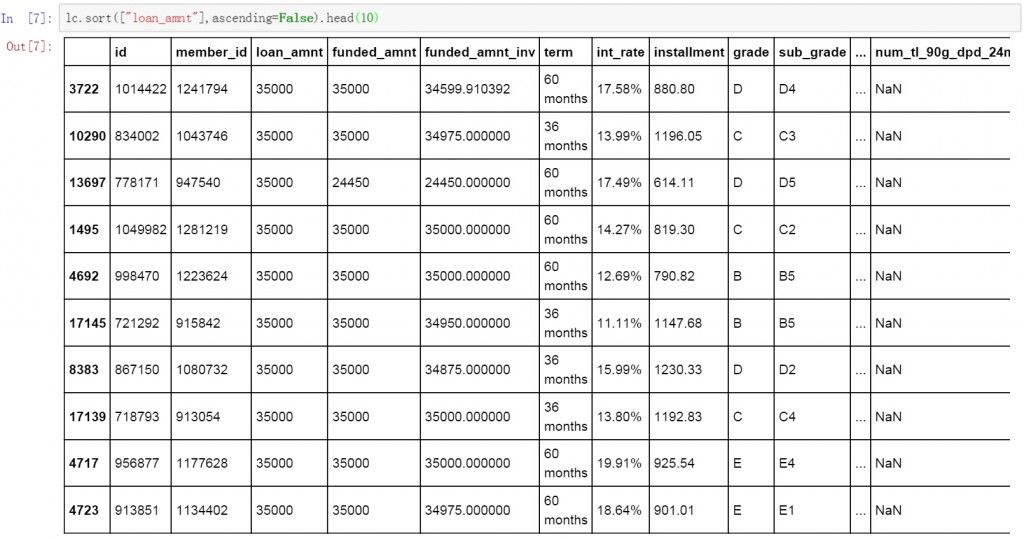
獲取金額最大前10項的代碼與獲取金額最小前10項略有差異,本來我們只需要復制前面的代碼,然后將.head()函數改為tail()函數即可,但由于NaN值在排序的尾部,因此,我們將lc數據表按loan_amnt按降序排列,并取排名前10的數據。當然這并不是唯一的方法,我們還可以通過放棄NaN值的排序或者將NaN值在排序前部顯示來解決這個問題。以下是具體的代碼和執行結果。
lc.sort(["loan_amnt"],ascending=False).head(10)
介紹完排序功能后再來看下篩選,在篩選功能上Pandas使用的是.loc函數。以下是Pandas官方對.loc函數的語法和使用方法的說明。

單列數據篩選并排序
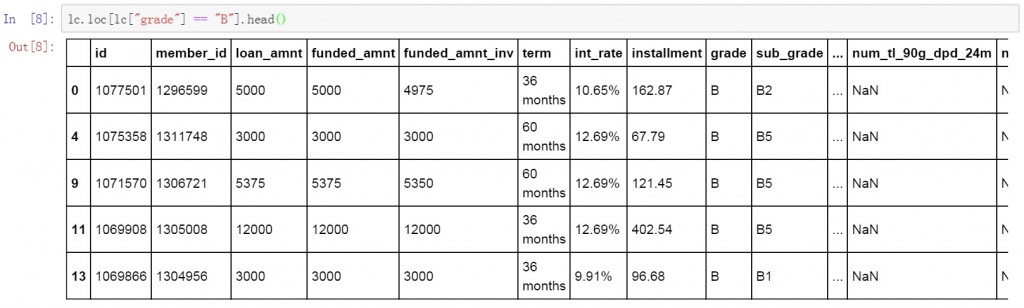
我們使用.loc對lc數據表中grade列為B值的數據條目進行了篩選操作,具體的代碼和篩選結果如下。在代碼中lc.loc[]是.loc函數的語法,lc[“grade”] == “B”是具體的篩選條件。由于數據表較大,因此在最后使用了head()函數只顯示前5行篩選結果。從篩選結果來看grade列的值都為B。
lc.loc[lc["grade"] == "B"].head()
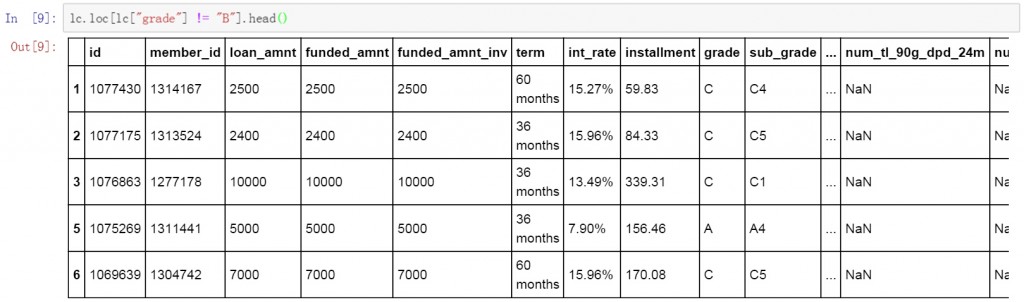
篩選條件除了”等于”(==)以外,還可以使用”不等于”(!=)來排除列中特定的值。我們使用”不等于”來篩選grade列中不是B值的數據條目。以下是具體的代碼和篩選結果,可以看到篩選結果中的grade列里已經不包含B值了。
lc.loc[lc["grade"] != "B"].head()
很多時候我們只關注數據表中某幾列的數據,這時可以在前面篩選代碼的基礎上增加要顯示的列名稱和顯示順序。下面是具體的代碼和篩選結果。代碼部分與之前相比增加了要顯示的列名稱 [“member_id”, “loan_amnt”, “grade”]。其余部分均沒有改變。在篩選結果的數據表中可以看到僅顯示了我們在代碼中列出的三列。
lc.loc[lc["grade"] == "B", ["member_id", "loan_amnt", "grade"]].head()
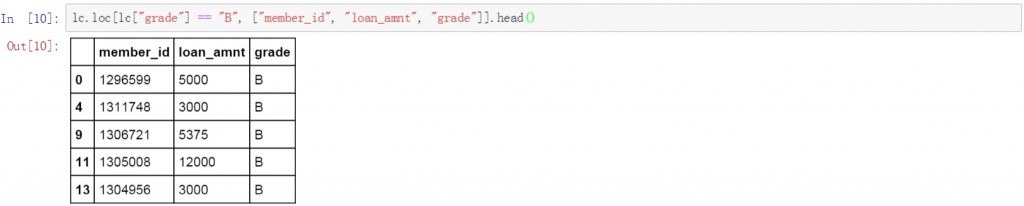
若要對篩選結果進行排序可以聯合使用.loc函數和.sort函數。下面的代碼中首先對數據表的grade列進行篩選,選擇所有值為B的數據,并限定了結果中要顯示的三列的名稱。最后對篩選出的結果按loan_amnt的金額進行升序排序。
lc.loc[lc["grade"] == "B", ["member_id", "loan_amnt", "grade"]].sort(["loan_amnt"])
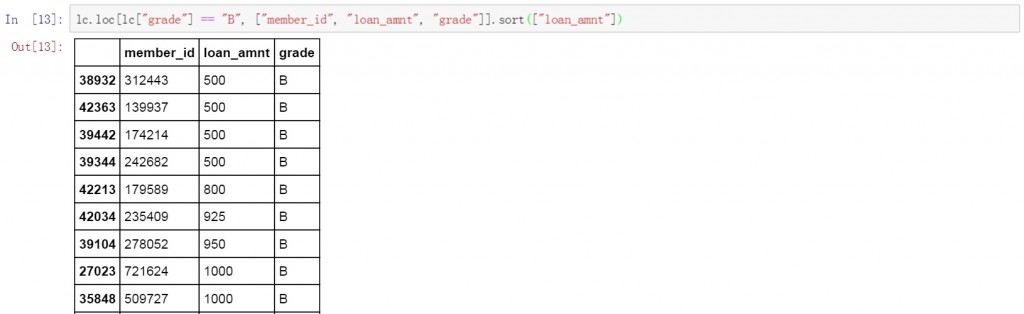
在代碼后面增加ascending參數,并將值設置為False就可實現對篩選結果的降序排列。以下為具體的代碼和篩選及排序結果。
lc.loc[lc["grade"] != "B", ["member_id", "loan_amnt", "grade"]].sort(["loan_amnt"],ascending=False)

多列數據篩選并排序
Pandas的.loc參數還可以同時對多列數據進行篩選,并且支持不同篩選條件邏輯組合。常用的篩選條件包括”等于”(==)”,不等于”(!),”大于”(>)”,小于”(<)”,大于等于”(>=)” ,小于等于”(<=)等等。邏輯組合包括”與”()和”或”()。下面我們將通過3條多列數據篩選代碼逐一進行介紹。
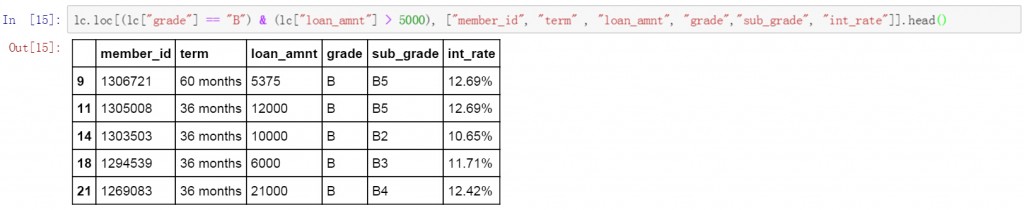
第一條代碼使用”與”邏輯,篩選出了grade等于B,并且loan_amnt金額大于5000的數據。并限定了顯示的列名稱。從篩選結果中可以看出grade列的值都是B,loan_amnt的金額均大于5000。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"]>5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].head()
第二條代碼也使用”與”邏輯,篩選出了grade不等于B,并且loan_status不等于Charged Off的數據,同時也限定了顯示的列名稱。從篩選結果中看grade列不包含B值,并且loan_status列不包含Charged Off值。
lc.loc[(lc["grade"] != "B") & (lc["loan_status"] != "Charged Off"),["member_id", "term" , "loan_amnt", "grade", "sub_grade", "loan_status"]].head()

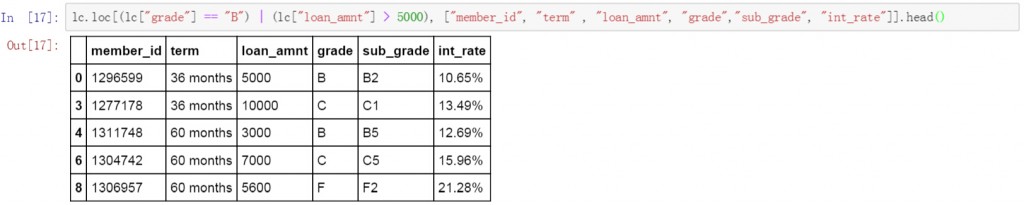
第三條代碼使用了”或”邏輯,篩選出了grade列值為B,或loan_amnt列金額大于5000的數據,同時也限定了顯示的列名稱。從篩選結果來看,grade列除了B值以外還保留了其他的值,而這些值在loan_amnt列的金額均大于5000。換句話說,一條數據只要grade列或loan_amnt列任意之一符合篩選條件,這條數據就會被顯示。
lc.loc[(lc["grade"] == "B") | (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].head()
多列篩選也可以進行排序,方法與單列篩選后排序基本一樣,下面的代碼對多列篩選后的結果按loan_amnt列進行升序排序。由于篩選條件中限定了loan_amnt列的值要大于5000,因此排序的結果從5020開始。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].sort(["loan_amnt"])
對多列篩選結果進行降序排序只需在前面升序排序代碼的基礎上增加ascending參數,并將值設定為False即可。下面是多列篩選后降序排序的代碼和結果。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].sort(["loan_amnt"],ascending=False)
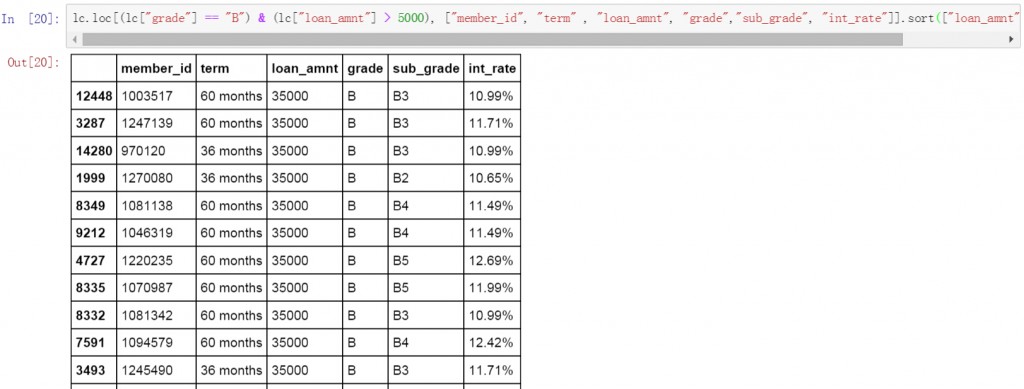
無論是”與”條件,還是”或”條件都可以在篩選后使用排序。下面代碼是對使用了“或”邏輯條件的篩選結果進行降序排序的代碼和結果。
lc.loc[(lc["grade"] == "B") | (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].sort(["loan_amnt"],ascending=False)
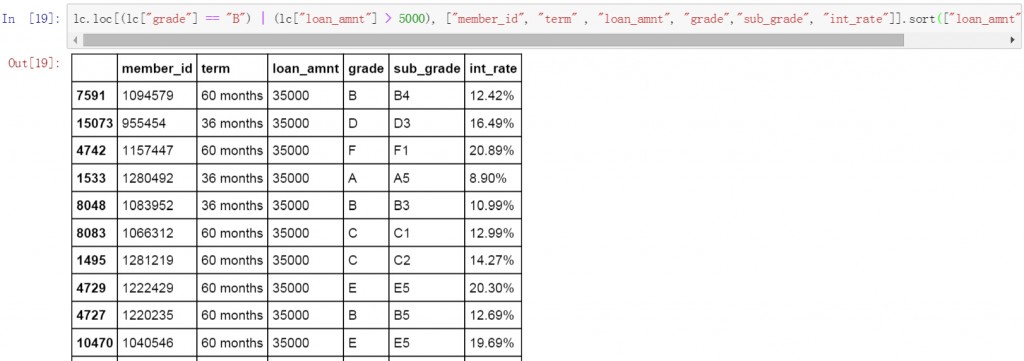
Pandas中的排序和篩選基本介紹完了,在實際的分析工作中,篩選只是分析過程中的一個步驟,很多時候我們還需要對篩選后的結果進行匯總,例如求和,計數,或計算均值等等。也就是Excel中常用的sumifs和countifs函數。
按篩選條件求和(sumif, sumifs)
在單列篩選的代碼后增加求和條件就相當于Excel中的sumif函數的功能。下面的代碼在單列篩選的代碼后增加了.loan_amnt.sum()的求和字段,表示對數據表中所有grade列值為B的loan_amnt金額求和。
lc.loc[lc["grade"] == "B",].loan_amnt.sum()

除了包含條件外,也可以對排除某一條件的數據求和。下面的代碼與之前的正好相反,對數據表中所有grade列值不為B的loan_amnt金額求和。
lc.loc[lc["grade"] != "B",].loan_amnt.sum()

增加一個篩選條件就變成了Excel中的sumifs函數的功能。下面的代碼中分別使用了兩個條件對數據表進行篩選,并對最后的loan_amnt金額進行求和。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000)].loan_amnt.sum()

按篩選條件計數(countif, countifs)
將前面的.sum()函數換為.count()函數就變成了Excel中的countif函數的功能,下面的代碼對數據表中grade列值為B的loan_amnt筆數進行計數。
lc.loc[lc["grade"] == "B"].loan_amnt.count()

與前面代碼相反,下面的代碼對數據表中grade列值不為B的所有loan_amnt筆數進行計數。
lc.loc[lc["grade"] != "B"].loan_amnt.count()

增加篩選條件,變成了Excel中的countifs函數的功能,下面的代碼對數據表中grade列值為B,并且loan_amnt金額額大于5000的loan_amnt筆數進行計數。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000)].loan_amnt.count()

按篩選條件計算均值(averageif, averageifs)
有了sumifs和countifs,當然也少不了averageifs,在Pandas中.mean()是用來計算均值的函數,將.sum()和.count()替換為.mean()。就是pandas版的averageif和averageifs。下面的代碼中計算了數據表中grade列值為B的loan_amnt金額均值。相當于Excel中的averageif函數的功能。
lc.loc[lc["grade"] == "B"].loan_amnt.mean()

與前面的代碼證號相反,下面的代碼計算了數據表中所有grade列值不為B的loan_amnt金額均值。
lc.loc[lc["grade"] != "B"].loan_amnt.mean()

增加一個篩選條件變成了Excel中的averageifs,不過這里好像又有一些不同,Excel中的sumifs,countifs和averageifs的計算邏輯是滿足滿足所有指定條件時,才對這些單元格進行求和或計數。而在下面的代碼中我們使用了或條件,就是說只要滿足兩個條件中的任意一個都會進行計算。
lc.loc[(lc["grade"] == "B") | (lc["loan_amnt"] > 5000)].loan_amnt.mean()

按篩選條件獲取最大值和最小值
最后兩個是Excel中沒有的函數功能,就是對篩選后的數據表計算最大值和最小值。方法很簡單,將之前的sum()和count()換成max()和min()函數即可。下面是具體的代碼和結果。
這條代碼是計算數據表中grade列值為B的loan_amnt最大金額。
lc.loc[lc["grade"] == "B"].loan_amnt.max()

這條代碼是計算數據表中grade列值不為B的loan_amnt最小金額。
lc.loc[lc["grade"] != "B"].loan_amnt.min()

關于使用Pandas對數據進行篩選和排序就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





