溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下怎樣爬取通過ajax加載數據的網站,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
目前很多網站都使用ajax技術動態加載數據,和常規的網站不一樣,數據時動態加載的,如果我們使用常規的方法爬取網頁,得到的只是一堆html代碼,沒有任何的數據。
請看下面的代碼:
url = 'https://www.toutiao.com/search/?keyword=美女'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
print(response.text)上面的代碼是爬取今日頭條的一個網頁,并打印出get方法返回的文本內容如下圖所示,值現在一堆網頁代碼,并沒有相關的頭條新聞信息
內容過多,只截取部分內容,有興趣的朋友可以執行上面的代碼看下效果。
對于使用ajax動態加載數據的網頁要怎么爬取呢?我們先看下近日頭條是如何使用ajax加載數據的。通過chrome的開發者工具來看數據加載過程。
首先打開chrome瀏覽器,打開開發者工具,點擊Network選項,點擊XHR選項,然后輸入網址:https://www.toutiao.com/search/?keyword=美女 ,點擊Preview選項卡,就會看到通過ajax請求返回的數據,Name那一欄就是ajax請求,當鼠標向下滑動時,就會出現多條ajax請求:

通過上圖我們知道ajax請求返回的是json數據,我們繼續分析ajax請求返回的json數據,點擊data展開數據,接著點擊0展開數據,發現有個title字段,內容剛好和網頁的第一條數據匹配,可知這就是我們要爬取的數據。如下所示:
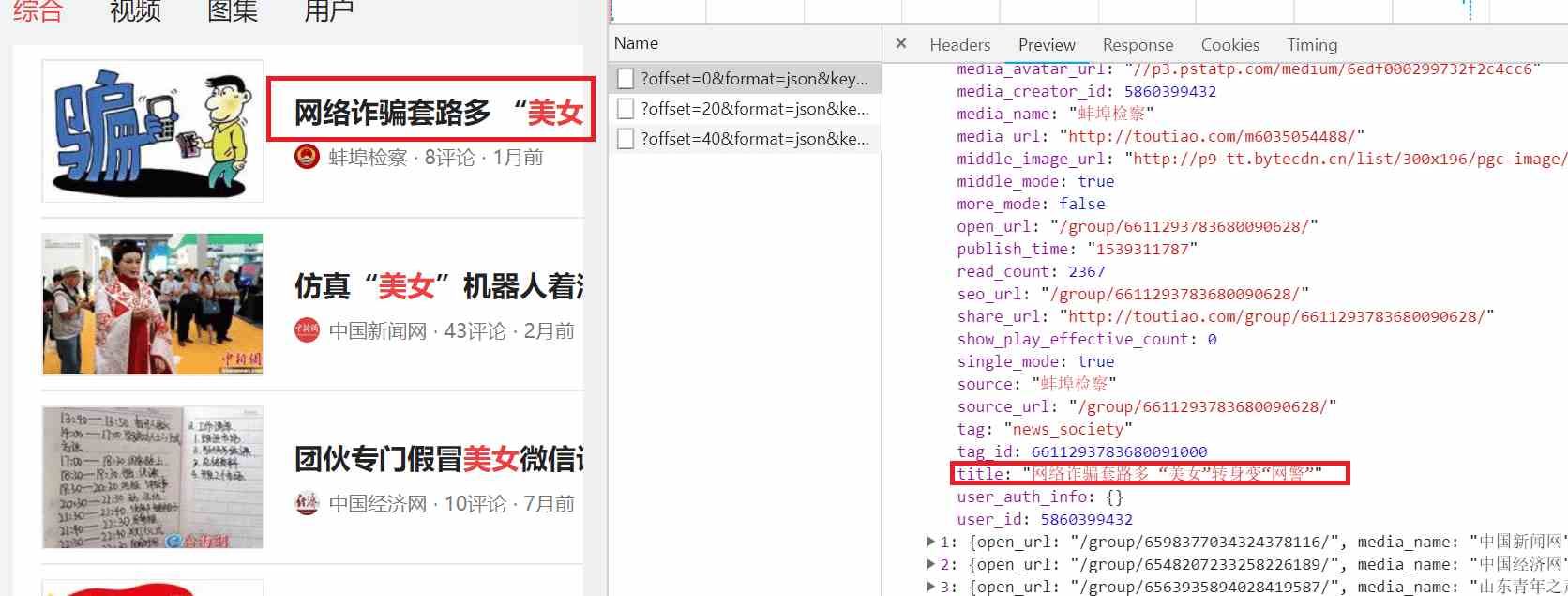
鼠標向下滾動到網頁底部時就會觸發一次ajax請求,下面是三次ajax請求:
https://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E7%BE%8E%E5%A5%B3&autoload=true&count=20&cur_tab=1&from=search_tab&pd=synthesis https://www.toutiao.com/search_content/?offset=20&format=json&keyword=%E7%BE%8E%E5%A5%B3&autoload=true&count=20&cur_tab=1&from=search_tab&pd=synthesis https://www.toutiao.com/search_content/?offset=40&format=json&keyword=%E7%BE%8E%E5%A5%B3&autoload=true&count=20&cur_tab=1&from=search_tab&pd=synthesis
觀察每個ajax請求,發現每個ajax請求都有offset,format,keyword,autoload,count,cur_tab,from,pd參數,除了offset參數有變化之外,其他的都不變化。每次ajax請求offset的參數變化規律是0,20,40,60…,可以推測offset是偏移量,count參數是一次ajax請求返回數據的條數。
為了防止爬蟲被封,每次請求時要把請求時都要傳遞請求頭信息,請求頭信息中包含了瀏覽器的信息,如果請求沒有瀏覽器信息,就認為是網絡爬蟲,直接拒絕訪問。request header信息如下:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search/?keyword=%E7%BE%8E%E5%A5%B3",
'x-requested-with': 'XMLHttpRequest'
}完整代碼如下:
import requests
from urllib.parse import urlencode
def parse_ajax_web(offset):
url = 'https://www.toutiao.com/search_content/?'
#請求頭信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search/",
'x-requested-with': 'XMLHttpRequest'
}
#每個ajax請求要傳遞的參數
parm = {
'offset': offset,
'format': 'json',
'keyword': '美女',
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis'
}
#構造ajax請求url
ajax_url = url + urlencode(parm)
#調用ajax請求
response = requests.get(ajax_url, headers=headers)
#ajax請求返回的是json數據,通過調用json()方法得到json數據
json = response.json()
data = json.get('data')
for item in data:
if item.get('title') is not None:
print(item.get('title'))
def main():
#調用ajax的次數,這里調用5次。
for offset in (range(0,5)):
parse_ajax_web(offset*20)
if __name__ == '__main__':
main()以上是“怎樣爬取通過ajax加載數據的網站”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





