溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關python如何實現H2O中的隨機森林算法的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
H2O中的隨機森林算法介紹及其項目實戰(python實現)
包的引入:from h3o.estimators.random_forest import H2ORandomForestEstimator
H2ORandomForestEstimator 的常用方法和參數介紹:
(一)建模方法:
model =H2ORandomForestEstimator(ntrees=n,max_depth =m) model.train(x=random_pv.names,y='Catrgory',training_frame=trainData)
通過trainData來構建隨機森林模型,model.train中的trainData:訓練集,x:預測變量名稱,y:預測 響應變量的名稱
(二)預測方法:
pre_tag=H2ORandomForestEstimator.predict(model ,test_data) 利用訓練好的模型來對測試集進行預測,其中的model:訓練好的模型, test_data:測試集。
(三)算法參數說明:
(1)ntrees:構建模型時要生成的樹的棵樹。
(2)max_depth :每棵樹的最大深度。
項目要求:
題目一: 利用train.csv中的數據,通過H2O框架中的隨機森林算法構建分類模型,然后利用模型對 test.csv中的數據進行預測,并計算分類的準確度進而評價模型的分類效果;通過調節參 數,觀察分類準確度的變化情況。 注:準確度=預測正確的數占樣本數的比例
題目二: 通過H2o Flow 的隨機森林算法,用同題目一中所用同樣的訓練數據和參數,構建模型; 參看模型中特征的重要性程度,從中選取前8個特征,再去訓練模型,并重新預測結果, 進而計算分類的準確度。
需求完成內容:2個題目的代碼,認為最好的準確度的輸出值和test數據與預測結果合并 后的數據集,命名為predict.csv
python實現代碼如下:
(1) 題目一:
#手動進行調節參數得到最好的準確率
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import h3o
h3o.init()
from h3o.estimators.random_forest import H2ORandomForestEstimator
from __future__ import division
df=h3o.import_file('train.csv')
trainData=df[2:]
model=H2ORandomForestEstimator(ntrees=6,max_depth =16)
model.train(x=trainData.names,y='Catrgory',training_frame=trainData)
df2=h3o.import_file('test.csv')
test_data=df2[2:]
pre_tag=H2ORandomForestEstimator.predict(model ,test_data)
predict=df2.concat(pre_tag)
dfnew=predict[predict['Catrgory']==predict['predict']]
Precision=dfnew.nrow/predict.nrow
print(Precision)
h3o.download_csv(predict,'predict.csv')運行結果最好為87.0833%-6-16,如下

#for循環進行調節參數得到最好的準確率
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import h3o
h3o.init()
from h3o.estimators.random_forest import H2ORandomForestEstimator
from __future__ import division
df=h3o.import_file('train.csv')
trainData=df[2:]
df2=h3o.import_file('test.csv')
test_data=df2[2:]
Precision=0
nt=0
md=0
for i in range(1,50):
for j in range(1,50):
model=H2ORandomForestEstimator(ntrees=i,max_depth =j)
model.train(x=trainData.names,y='Catrgory',training_frame=trainData)
pre_tag=H2ORandomForestEstimator.predict(model ,test_data)
predict=df2.concat(pre_tag)
dfnew=predict[predict['Catrgory']==predict['predict']]
p=dfnew.nrow/predict.nrow
if Precision<p:
Precision=p
nt=i
md=j
print(Precision)
print(i)
print(j)
h3o.download_csv(predict,'predict.csv')運行結果最好為87.5%-49-49,如下

(2)題目二:建模如下,之后挑出排名前8的特征進行再次建模
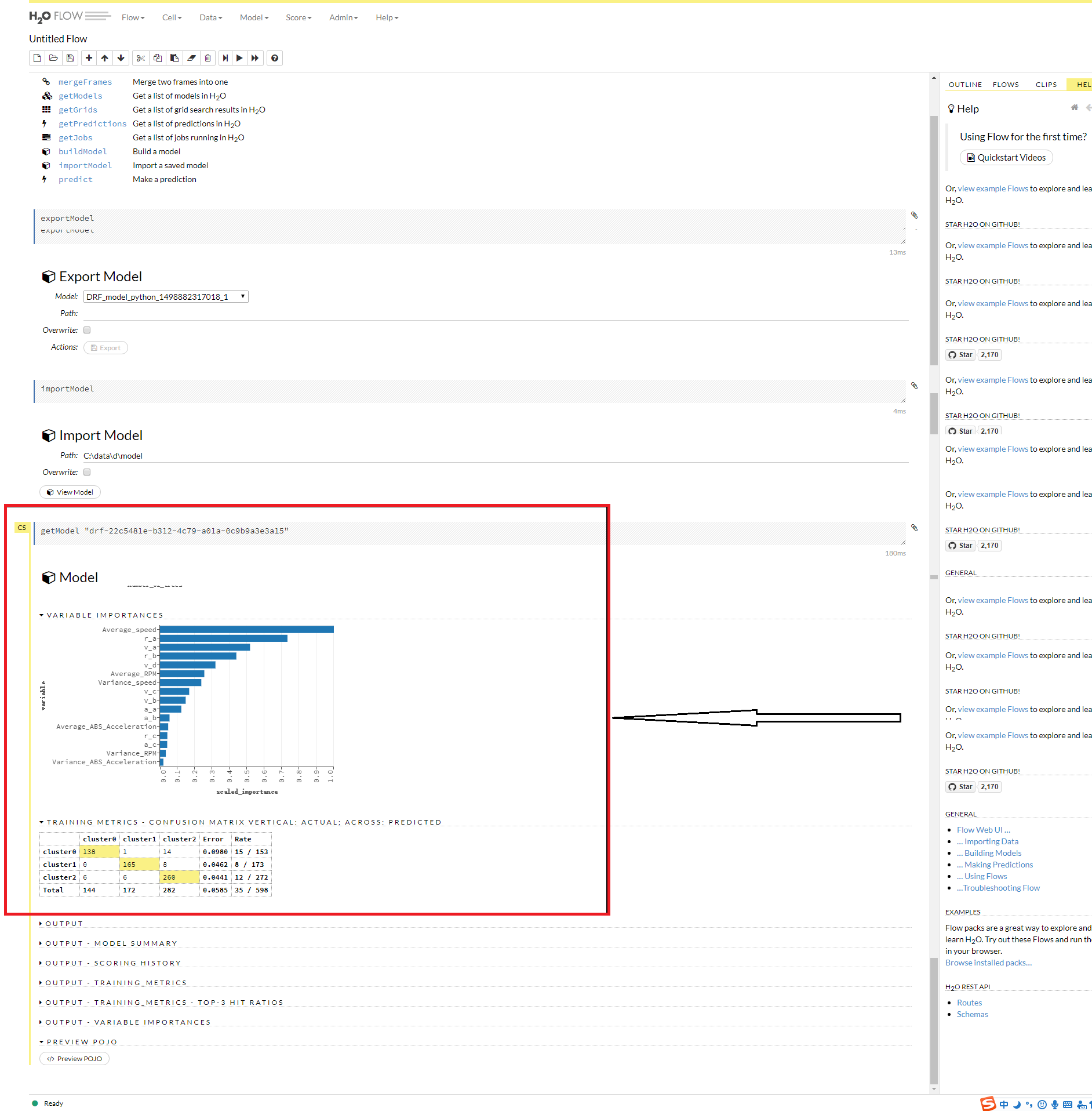
#手動調節參數得到最大準確率
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import h3o
h3o.init()
from h3o.estimators.random_forest import H2ORandomForestEstimator
from __future__ import division
df=h3o.import_file('train.csv')
trainData=df[['Average_speed','r_a','r_b','v_a','v_d','Average_RPM','Variance_speed','v_c','Catrgory']]
df2=h3o.import_file('test.csv')
test_data=df2[['Average_speed','r_a','r_b','v_a','v_d','Average_RPM','Variance_speed','v_c','Catrgory']]
model=H2ORandomForestEstimator(ntrees=5,max_depth =18)
model.train(x=trainData.names,y='Catrgory',training_frame=trainData)
pre_tag=H2ORandomForestEstimator.predict(model ,test_data)
predict=df2.concat(pre_tag)
dfnew=predict[predict['Catrgory']==predict['predict']]
Precision=dfnew.nrow/predict.nrow
print(Precision)
h3o.download_csv(predict,'predict.csv')運行結果最好為87.5%-5-18,如下

#for循環調節參數得到最大正確率
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import h3o
h3o.init()
from h3o.estimators.random_forest import H2ORandomForestEstimator
from __future__ import division
df=h3o.import_file('train.csv')
trainData=df[['Average_speed','r_a','r_b','v_a','v_d','Average_RPM','Variance_speed','v_c','Catrgory']]
df2=h3o.import_file('test.csv')
test_data=df2[['Average_speed','r_a','r_b','v_a','v_d','Average_RPM','Variance_speed','v_c','Catrgory']]
Precision=0
nt=0
md=0
for i in range(1,50):
for j in range(1,50):
model=H2ORandomForestEstimator(ntrees=i,max_depth =j)
model.train(x=trainData.names,y='Catrgory',training_frame=trainData)
pre_tag=H2ORandomForestEstimator.predict(model ,test_data)
predict=df2.concat(pre_tag)
dfnew=predict[predict['Catrgory']==predict['predict']]
p=dfnew.nrow/predict.nrow
if Precision<p:
Precision=p
nt=i
md=j
print(Precision)
print(i)
print(j)
h3o.download_csv(predict,'predict.csv')運行結果最好為87.5%-49-49,如下

感謝各位的閱讀!關于“python如何實現H2O中的隨機森林算法”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





