溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了R語言分類算法中隨機森林是什么意思,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
1.原理分析:
隨機森林是通過自助法(boot-strap)重采樣技術,從原始訓練樣本集N中有放回地重復隨機抽取k個樣本生成新的訓練集樣本集合,然后根據自助樣本集生成k個決策樹組成的隨機森林,新數據的分類結果按照決策樹投票多少形成的分數而定.
通俗的理解為由許多棵決策樹組成的森林,而每個樣本需要經過每棵樹進行預測,然后根據所有決策樹的預測結果最后來確定整個隨機森林的預測結果.隨機森林中的每一顆決策樹都為二叉樹,其生成遵循自頂向下的遞歸分裂原則,即從根節點開始依次對訓練集進行劃分.在二叉樹中,根節點包含全部訓練數據,按照節點不純度最小原則,分裂為左節點和右節點,他們分別包含訓數據的一個子集,按照同樣的規則,節點繼續分裂,直到滿足分支停止規則,停止生長.
1.首先我們用N來表示原始訓練集樣本的個數,用M來表示變量的數目.
2.其次我們需要確定一個定值m,該值被用來決定當在一個節點上做決定時,會使用到多少個變量.m
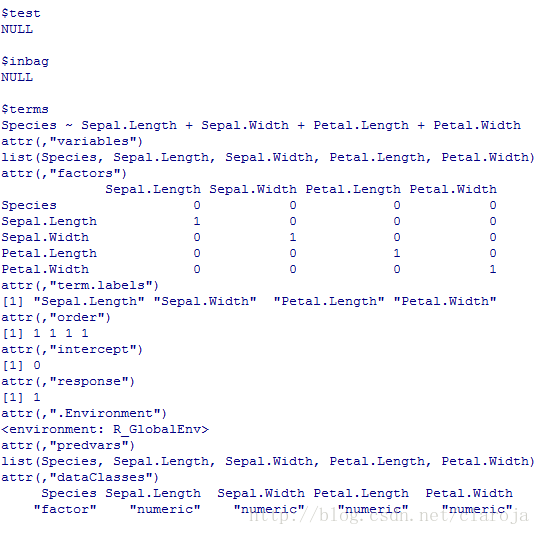
fit_rf=randomForest(Species~.,data=data_train,mtry=4,importance=TRUE,ntree=1000)fit_rf[1:length(fit_rf)]

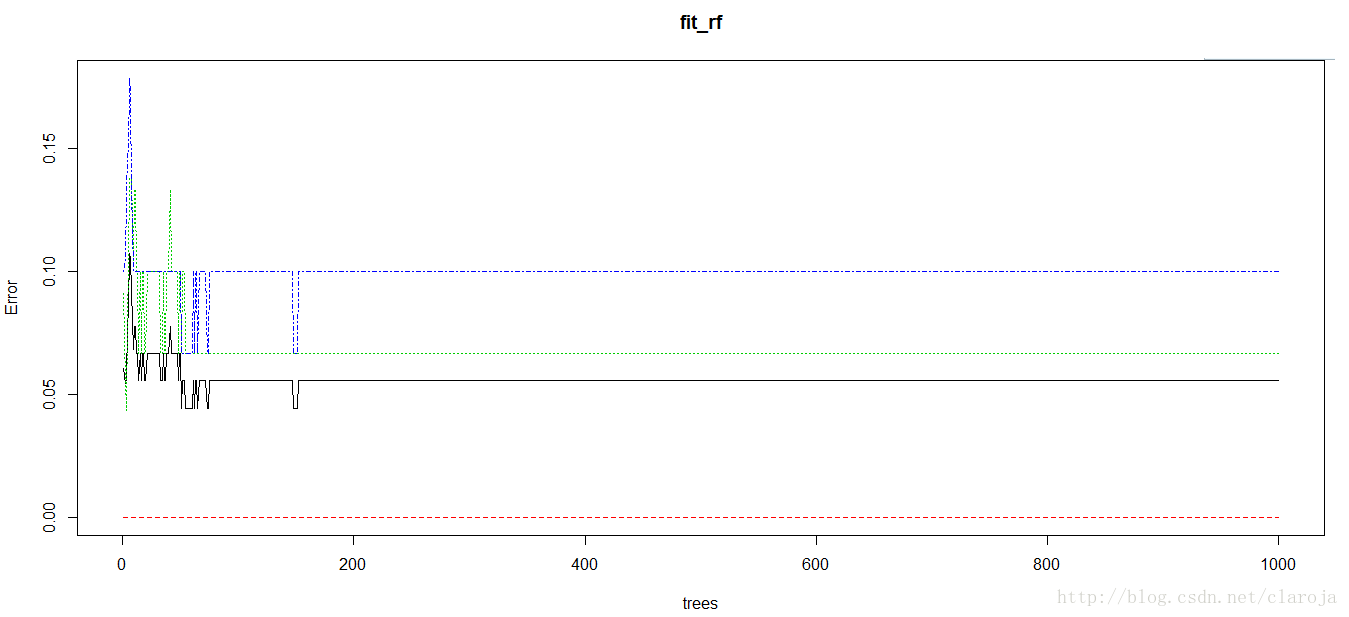
2)作圖
上述內容就是R語言分類算法中隨機森林是什么意思,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





