溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
快要過年了,大家都在忙些什么呢?一到年底公司各種搶票,備年貨,被這過年的氣氛一烘,都歸心似箭,哪還有心思上班啊。歸心似箭=產出低下=一行代碼十個錯=無聊。于是想起了以前學過一段時間的Python,自己平時也挺愛看電影的,手動點進去看電影詳情然后一部一部的去下載太煩了,何不用Python寫個自動下載電影的工具呢?誒,這么一想就不無聊了。以前還沒那么多XX會員的時候,想看看電影都是去XX天堂去找電影資源,大部分想看的電影還是有的,就它了,爬它!
話說以前玩Python的時候爬過挺多網站的,都是在公司干的(Python不屬于公司的業務范圍,純屬自己折騰著好玩),我那個負責運維的同事天天跑過來說:你又在爬啥啊,你去看看新聞,某某爬東西又被抓了!出了事你自己負責啊!哎呀我的娘親,嚇的都沒繼續玩下去了。這個博客是爬取某天堂的資源(具體是哪個天堂下面的代碼里會有的),會不會被抓啊?單純的作為技術討論,個人練手,不做商業用途應該沒事吧?寫到這里小手不禁微微顫抖...
得嘞,死就死吧,我不入地獄誰入地獄,先看最終實現效果:
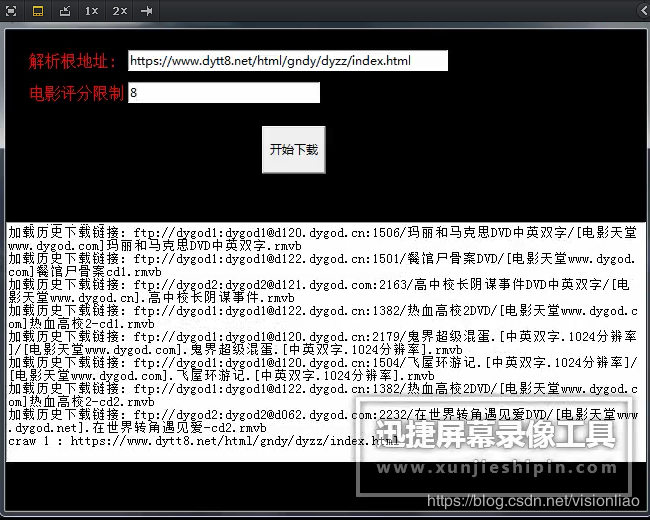
如上,這個下載工具是有界面的(牛皮吧),只要輸入一個根地址和電影評分,就可以自動爬電影了,要完成這個工具需要具備以下知識點:
差不多就這些了,至于實現的技術細節的話,也不多,requests+BeautifulSoup的使用,re正則,Python數據類型,Python線程,dbm、pickle等數據持久化庫的使用,等等,這個工具也就這么些知識范疇了。當然,Python是面向對象的,編程思想是所有語言通用的,這個不是一朝一夕的事,也沒辦法通過語言描述清楚。各位對號入座,以上哪個知識面不足的自己去翻資料學習,我可是直接貼代碼的。
說到Python的學習還是多說兩句吧,以前學習Python爬蟲的時候看的是 @工匠若水 https://blog.csdn.net/yanbober的博客,這哥們的Python文章寫的真不錯,對于有過編程經驗卻從沒接觸過Python的人很有幫助,基本上很快就能上手一個小項目。得嘞,擼代碼:
import url_manager
import html_parser
import html_download
import persist_util
from tkinter import *
from threading import Thread
import os
class SpiderMain(object):
def __init__(self):
self.mUrlManager = url_manager.UrlManager()
self.mHtmlParser = html_parser.HtmlParser()
self.mHtmlDownload = html_download.HtmlDownload()
self.mPersist = persist_util.PersistUtil()
# 加載歷史下載鏈接
def load_history(self):
history_download_links = self.mPersist.load_history_links()
if history_download_links is not None and len(history_download_links) > 0:
for download_link in history_download_links:
self.mUrlManager.add_download_url(download_link)
d_log("加載歷史下載鏈接: " + download_link)
# 保存歷史下載鏈接
def save_history(self):
history_download_links = self.mUrlManager.get_download_url()
if history_download_links is not None and len(history_download_links) > 0:
self.mPersist.save_history_links(history_download_links)
def craw_movie_links(self, root_url, score=8):
count = 0;
self.mUrlManager.add_url(root_url)
while self.mUrlManager.has_continue():
try:
count = count + 1
url = self.mUrlManager.get_url()
d_log("craw %d : %s" % (count, url))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
'Referer': url
}
content = self.mHtmlDownload.down_html(url, retry_count=3, headers=headers)
if content is not None:
doc = content.decode('gb2312', 'ignore')
movie_urls, next_link = self.mHtmlParser.parser_movie_link(doc)
if movie_urls is not None and len(movie_urls) > 0:
for movie_url in movie_urls:
d_log('movie info url: ' + movie_url)
content = self.mHtmlDownload.down_html(movie_url, retry_count=3, headers=headers)
if content is not None:
doc = content.decode('gb2312', 'ignore')
movie_name, movie_score, movie_xunlei_links = self.mHtmlParser.parser_movie_info(doc, score=score)
if movie_xunlei_links is not None and len(movie_xunlei_links) > 0:
for xunlei_link in movie_xunlei_links:
# 判斷該電影是否已經下載過了
is_download = self.mUrlManager.has_download(xunlei_link)
if is_download == False:
# 沒下載過的電影添加到迅雷下載列表
d_log('開始下載 ' + movie_name + ', 鏈接地址: ' + xunlei_link)
self.mUrlManager.add_download_url(xunlei_link)
os.system(r'"D:\迅雷\Thunder\Program\Thunder.exe" {url}'.format(url=xunlei_link))
# 每下載一部電影都實時更新數據庫,這樣可以保證即使程序異常退出也不會重復下載該電影
self.save_history()
if next_link is not None:
d_log('next link: ' + next_link)
self.mUrlManager.add_url(next_link)
except Exception as e:
d_log('錯誤信息: ' + str(e))
def runner(rootLink=None, scoreLimit=None):
if rootLink is None:
return
spider = SpiderMain()
spider.load_history()
if scoreLimit is None:
spider.craw_movie_links(rootLink)
else:
spider.craw_movie_links(rootLink, score=float(scoreLimit))
spider.save_history()
# rootLink = 'https://www.dytt8.net/html/gndy/dyzz/index.html'
# rootLink = 'https://www.dytt8.net/html/gndy/dyzz/list_23_207.html'
def start(rootLink, scoreLimit):
loop_thread = Thread(target=runner, args=(rootLink, scoreLimit,), name='LOOP THREAD')
#loop_thread.setDaemon(True)
loop_thread.start()
#loop_thread.join() # 不能讓主線程等待,否則GUI界面將卡死
btn_start.configure(state='disable')
# 刷新GUI界面,文字滾動效果
def d_log(log):
s = log + '\n'
txt.insert(END, s)
txt.see(END)
if __name__ == "__main__":
rootGUI = Tk()
rootGUI.title('XX電影自動下載工具')
# 設置窗體背景顏色
black_background = '#000000'
rootGUI.configure(background=black_background)
# 獲取屏幕寬度和高度
screen_w, screen_h = rootGUI.maxsize()
# 居中顯示窗體
window_x = (screen_w - 640) / 2
window_y = (screen_h - 480) / 2
window_xy = '640x480+%d+%d' % (window_x, window_y)
rootGUI.geometry(window_xy)
lable_link = Label(rootGUI, text='解析根地址: ',\
bg='black',\
fg='red', \
font=('宋體', 12), \
relief=FLAT)
lable_link.place(x=20, y=20)
lable_link_width = lable_link.winfo_reqwidth()
lable_link_height = lable_link.winfo_reqheight()
input_link = Entry(rootGUI)
input_link.place(x=20+lable_link_width, y=20, relwidth=0.5)
lable_score = Label(rootGUI, text='電影評分限制: ', \
bg='black', \
fg='red', \
font=('宋體', 12), \
relief=FLAT)
lable_score.place(x=20, y=20+lable_link_height+10)
input_score = Entry(rootGUI)
input_score.place(x=20+lable_link_width, y=20+lable_link_height+10, relwidth=0.3)
btn_start = Button(rootGUI, text='開始下載', command=lambda: start(input_link.get(), input_score.get()))
btn_start.place(relx=0.4, rely=0.2, relwidth=0.1, relheight=0.1)
txt = Text(rootGUI)
txt.place(rely=0.4, relwidth=1, relheight=0.5)
rootGUI.mainloop()
spider_main.py,主代碼入口,主要是tkinter 實現的一個簡陋的界面,可以輸入根地址,電影最低評分。所謂的根地址就是某天堂網站的一類電影的入口,比如進入首頁有如下的分類,最新電影、日韓電影、歐美影片、2019精品專區,等等。這里以2019精品專區為例(https://www.dytt8.net/html/gndy/dyzz/index.html),當然,用其它的分類地址入口也是可以的。評分就是個過濾電影的條件,要學會對垃圾電影說不,浪費時間浪費表情,你可以指定大于等于8分的電影才下載,也可以指定大于等于9分等,必須輸入數字哈,輸入些亂七八糟的東西進去程序會崩潰,這個細節我懶得處理。
'''
URL鏈接管理類,負責管理爬取下來的電影鏈接地址,包括新解析出來的鏈接地址,和已經下載過的鏈接地址,保證相同的鏈接地址只會下載一次
'''
class UrlManager(object):
def __init__(self):
self.urls = set()
self.used_urls = set()
self.download_urls = set()
def add_url(self, url):
if url is None:
return
if url not in self.urls and url not in self.used_urls:
self.urls.add(url)
def add_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_url(url)
def has_continue(self):
return len(self.urls) > 0
def get_url(self):
url = self.urls.pop()
self.used_urls.add(url)
return url
def get_download_url(self):
return self.download_urls
def has_download(self, url):
return url in self.download_urls
def add_download_url(self, url):
if url is None:
return
if url not in self.download_urls:
self.download_urls.add(url)
url_manager.py,注釋里寫的很清楚了,基本上每個py文件的關鍵地方我都寫了比較詳細的注釋
import requests
from requests import Timeout
'''
HtmlDownload,通過一個鏈接地址將該html頁面整體down下來,然后通過html_parser.py解析其中有價值的信息
'''
class HtmlDownload(object):
def __init__(self):
self.request_session = requests.session()
self.request_session.proxies
def down_html(self, url, retry_count=3, headers=None, proxies=None, data=None):
if headers:
self.request_session.headers.update(headers)
try:
if data:
content = self.request_session.post(url, data=data, proxies=proxies)
print('result code: ' + str(content.status_code) + ', link: ' + url)
if content.status_code == 200:
return content.content
else:
content = self.request_session.get(url, proxies=proxies)
print('result code: ' + str(content.status_code) + ', link: ' + url)
if content.status_code == 200:
return content.content
except (ConnectionError, Timeout) as e:
print('HtmlDownload ConnectionError or Timeout: ' + str(e))
if retry_count > 0:
self.down_html(url, retry_count-1, headers, proxies, data)
return None
except Exception as e:
print('HtmlDownload Exception: ' + str(e))
html_download.py,就是用requests將靜態網頁的內容整體down下來
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import re
import urllib.parse
import base64
'''
html頁面解析器
'''
class HtmlParser(object):
# 解析電影列表頁面,獲取電影詳情頁面的鏈接
def parser_movie_link(self, content):
try:
urls = set()
next_link = None
doc = BeautifulSoup(content, 'lxml')
div_content = doc.find('div', class_='co_content8')
if div_content is not None:
tables = div_content.find_all('table')
if tables is not None and len(tables) > 0:
for table in tables:
link = table.find('a', class_='ulink')
if link is not None:
print('movie name: ' + link.text)
movie_link = urljoin('https://www.dytt8.net', link.get('href'))
print('movie link ' + movie_link)
urls.add(movie_link)
next = div_content.find('a', text=re.compile(r".*?下一頁.*?"))
if next is not None:
next_link = urljoin('https://www.dytt8.net/html/gndy/dyzz/', next.get('href'))
print('movie next link ' + next_link)
return urls, next_link
except Exception as e:
print('解析電影鏈接地址發生錯誤: ' + str(e))
# 解析電影詳情頁面,獲取電影詳細信息
def parser_movie_info(self, content, score=8):
try:
movie_name = None # 電影名稱
movie_score = 0 # 電影評分
movie_xunlei_links = set() # 電影的迅雷下載地址,可能存在多個
doc = BeautifulSoup(content, 'lxml')
movie_name = doc.find('title').text.replace('迅雷下載_電影天堂', '')
#print(movie_name)
div_zoom = doc.find('div', id='Zoom')
if div_zoom is not None:
# 獲取電影評分
span_txt = div_zoom.text
txt_list = span_txt.split('◎')
if txt_list is not None and len(txt_list) > 0:
for tl in txt_list:
if 'IMDB' in tl or 'IMDb' in tl or 'imdb' in tl or 'IMdb' in tl:
txt_score = tl.split('/')[0]
print(txt_score)
movie_score = re.findall(r"\d+\.?\d*", txt_score)
if movie_score is None or len(movie_score) <= 0:
movie_score = 1
else:
movie_score = movie_score[0]
print(movie_name + ' IMDB影片分數: ' + str(movie_score))
if float(movie_score) < score:
print('電影評分低于' + str(score) + ', 忽略')
return movie_name, movie_score, movie_xunlei_links
txt_a = div_zoom.find_all('a', href=re.compile(r".*?ftp:.*?"))
if txt_a is not None:
# 獲取電影迅雷下載地址,base64轉成迅雷格式
for alink in txt_a:
xunlei_link = alink.get('href')
'''
這里將電影鏈接轉換成迅雷的專用下載鏈接,后來發現不轉換迅雷也能識別
xunlei_link = urllib.parse.quote(xunlei_link)
xunlei_link = xunlei_link.replace('%3A', ':')
xunlei_link = xunlei_link.replace('%40', '@')
xunlei_link = xunlei_link.replace('%5B', '[')
xunlei_link = xunlei_link.replace('%5D', ']')
xunlei_link = 'AA' + xunlei_link + 'ZZ'
xunlei_link = base64.b64encode(xunlei_link.encode('gbk'))
xunlei_link = 'thunder://' + str(xunlei_link, encoding='gbk')
'''
print(xunlei_link)
movie_xunlei_links.add(xunlei_link)
return movie_name, movie_score, movie_xunlei_links
except Exception as e:
print('解析電影詳情頁面錯誤: ' + str(e))
html_parser.py,用bs4解析down下來的html頁面內容,根據網頁規則過去我們需要的東西,這是爬蟲最重要的地方,寫爬蟲的目的就是想要取出對我們有用的東西。
import dbm
import pickle
import os
'''
數據持久化工具類
'''
class PersistUtil(object):
def save_data(self, name='No Name', urls=None):
if urls is None or len(urls) <= 0:
return
try:
history_db = dbm.open('downloader_history', 'c')
history_db[name] = str(urls)
finally:
history_db.close()
def get_data(self):
history_links = set()
try:
history_db = dbm.open('downloader_history', 'r')
for key in history_db.keys():
history_links.add(str(history_db[key], 'gbk'))
except Exception as e:
print('遍歷dbm數據失敗: ' + str(e))
return history_links
# 使用pickle保存歷史下載記錄
def save_history_links(self, urls):
if urls is None or len(urls) <= 0:
return
with open('DownloaderHistory', 'wb') as pickle_file:
pickle.dump(urls, pickle_file)
# 獲取保存在pickle中的歷史下載記錄
def load_history_links(self):
if os.path.exists('DownloaderHistory'):
with open('DownloaderHistory', 'rb') as pickle_file:
return pickle.load(pickle_file)
else:
return None
persist_util.py,數據持久化工具類。
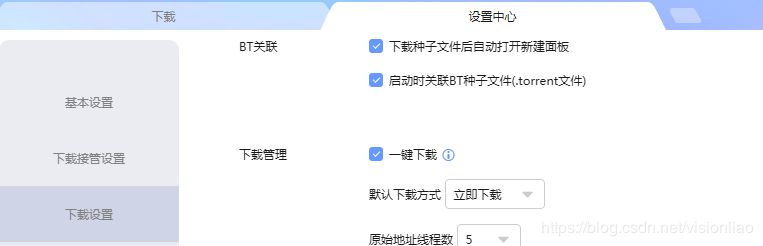
這樣代碼部分就完成了,說下迅雷,我安裝的是最新版的迅雷X,一定要如下圖一樣在迅雷設置打開一鍵下載功能,否則每次新增一個下載任務都會彈出用戶確認框的,還有就是調用迅雷下載資源的代碼:os.system(r'"D:\迅雷\Thunder\Program\Thunder.exe" {url}'.format(url=xunlei_link)),一定要去到迅雷安裝目錄找到Thunder.exe文件,不能用快捷方式的地址(我的電腦->迅雷->右鍵屬性->目標,迅雷X這里顯示的路徑是快捷方式的路徑,不能用這個),否則找不到程序。
到這里你應該就可以電影爬起來了,妥妥的。當然,你想要優化也可以,程序有很多可以優化的地方,比如線程那一塊,比如數據持久化那里..... 初學者可以通過這個練手,然后自己去分析分析靜態網站的規則,把解析html那一塊的代碼改改就可以爬其它的網站了,比如那些有著危險動作的電影... 不過這類電影還是少看為妙,要多讀書,偶爾看了也要擦擦干凈,洗洗干凈,要講衛生。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





