溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在獲得網頁響應對象res后,使用res.text屬性可以獲得網頁源代碼,但可能出現亂碼!因為requests庫會使用自動猜測的解碼方式將抓取的網頁源碼進行解碼,然后存儲到res對象的text屬性中;
但有的網站的編碼格式和requests庫默認的解碼格式()不一樣(比如gbk gb2312是gbk的子集),這時候就要自己手動進行解碼,先獲得content屬性,返回的是bytes類型的字符串,再進行解碼decode(“網頁的編碼
格式”)
這時候可能出現新的問題
'gbk' codec can't decode byte 0xd0 in position 15264: illegal multibyte sequence
這是因為遇到了非法字符
比如網頁中有這種字符
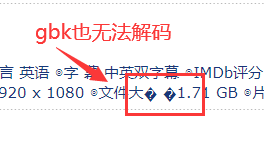
全角空格往往有多種不同的實現方式,比如\xa3\xa0,或者\xa4\x57,這些 字符,看起來都是全角空格,但它們并不是“合法”的全角空格(真正的全角空格是\xa1\xa1),因此在轉碼的過程中出現了異常。
只要字符串中出現了一個非法字符,整篇文章就都無法轉碼。
對于這種字符,根本不需要,不重要!
解決方法:在解碼時候指定errors參數,
decode()的函數原型是decode([encoding], [errors='strict']),可以用第二個參數控制錯誤處理的策略,默認的參數是strict,代表遇到非法字符時拋出異常;
#requests庫默認會使用自己猜測的解碼方式將抓取下來的網頁進行解碼,然后存儲到text屬性上去;
#但在該網站中,編碼方式和默認的解碼方式不一樣,就會產生亂碼,所以要手動進行解碼,先獲得content再decode()解碼
#右鍵查看網頁源代碼,發現是gb2312編碼,gb2312就是gbk的子集,所以用decode("gbk")
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





